 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting adversaries in Crowdsourcing
Oct 07, 2021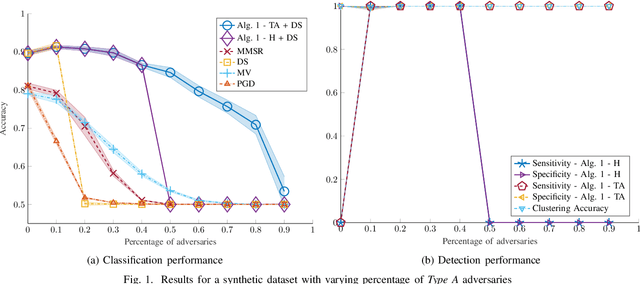
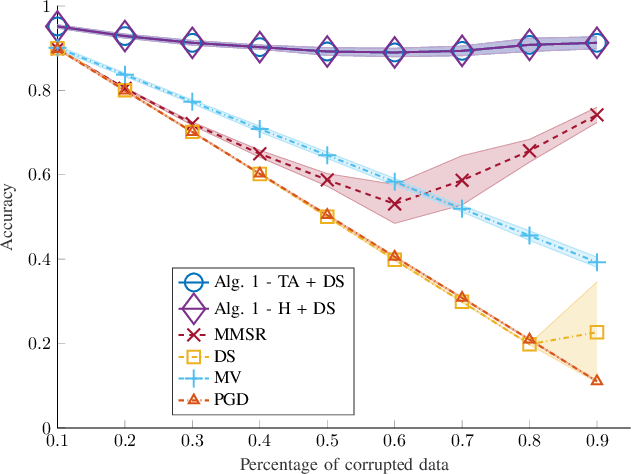
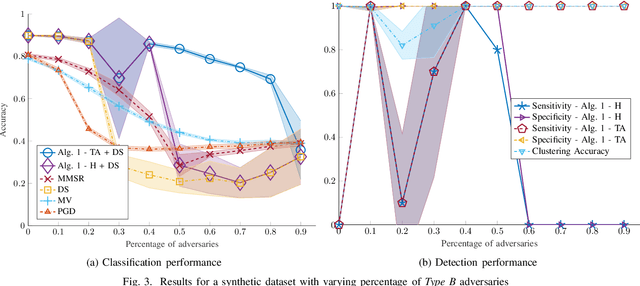
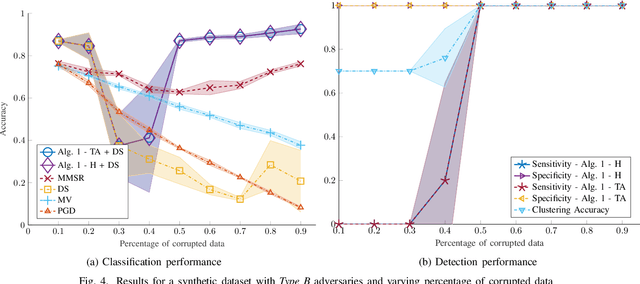
Despite its successes in various machine learning and data science tasks, crowdsourcing can be susceptible to attacks from dedicated adversaries. This work investigates the effects of adversaries on crowdsourced classification, under the popular Dawid and Skene model. The adversaries are allowed to deviate arbitrarily from the considered crowdsourcing model, and may potentially cooperate. To address this scenario, we develop an approach that leverages the structure of second-order moments of annotator responses, to identify large numbers of adversaries, and mitigate their impact on the crowdsourcing task. The potential of the proposed approach is empirically demonstrated on synthetic and real crowdsourcing datasets.
Resonant Beam Communications with Echo Interference Elimination
Jun 25, 2021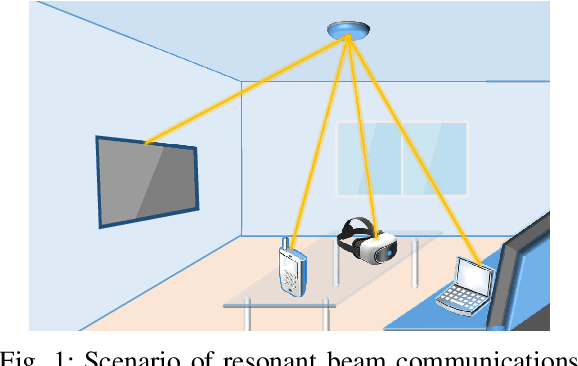
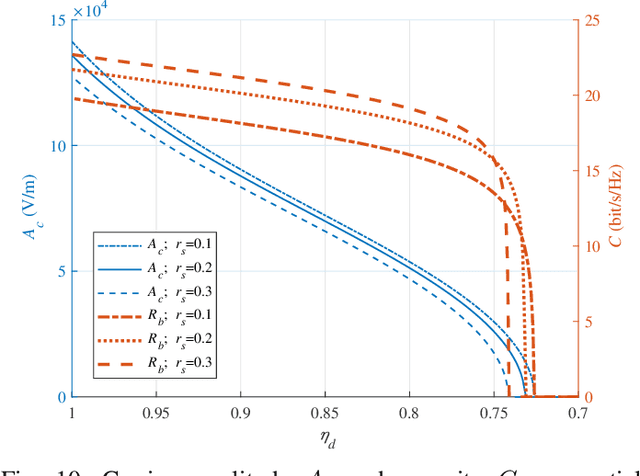
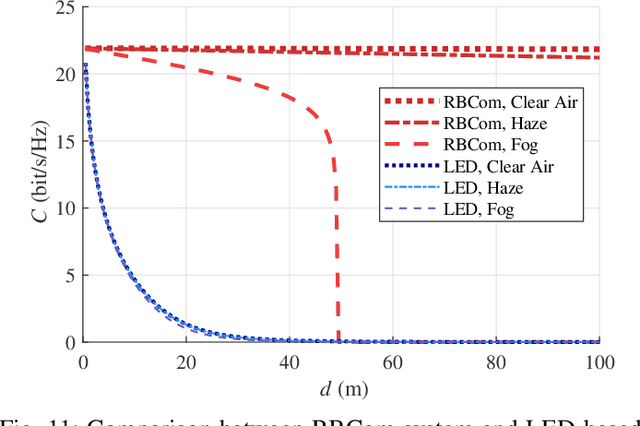
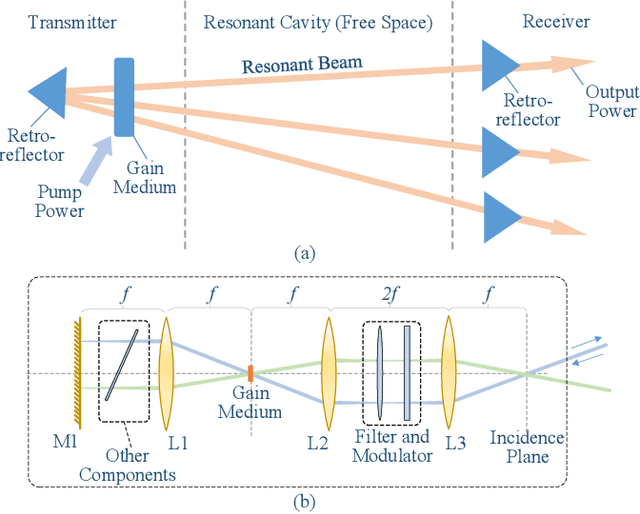
Resonant beam communications (RBCom) is capable of providing wide bandwidth when using light as the carrier. Besides, the RBCom system possesses the characteristics of mobility, high signal-to-noise ratio (SNR), and multiplexing. Nevertheless, the channel of the RBCom system is distinct from other light communication technologies due to the echo interference issue. In this paper, we reveal the mechanism of the echo interference and propose the method to eliminate the interference. Moreover, we present an exemplary design based on frequency shifting and optical filtering, along with its mathematic model and performance analysis. The numerical evaluation shows that the channel capacity is greater than 15 bit/s/Hz.
Unveiling Anomalous Edges and Nominal Connectivity of Attributed Networks
Apr 17, 2021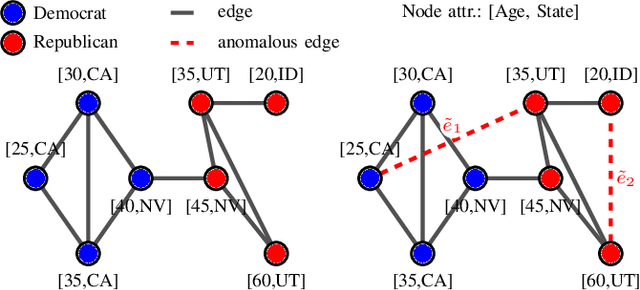
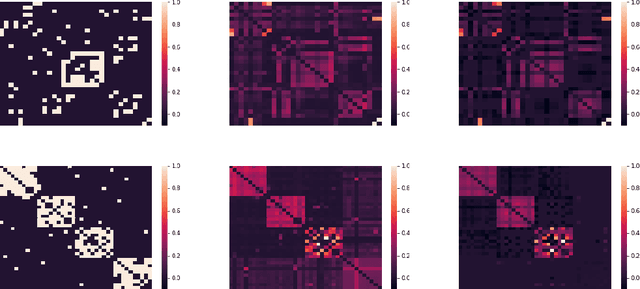
Uncovering anomalies in attributed networks has recently gained popularity due to its importance in unveiling outliers and flagging adversarial behavior in a gamut of data and network science applications including {the Internet of Things (IoT)}, finance, security, to list a few. The present work deals with uncovering anomalous edges in attributed graphs using two distinct formulations with complementary strengths, which can be easily distributed, and hence efficient. The first relies on decomposing the graph data matrix into low rank plus sparse components to markedly improve performance. The second broadens the scope of the first by performing robust recovery of the unperturbed graph, which enhances the anomaly identification performance. The novel methods not only capture anomalous edges linking nodes of different communities, but also spurious connections between any two nodes with different features. Experiments conducted on real and synthetic data corroborate the effectiveness of both methods in the anomaly identification task.
Learning to Solve the AC-OPF using Sensitivity-Informed Deep Neural Networks
Mar 27, 2021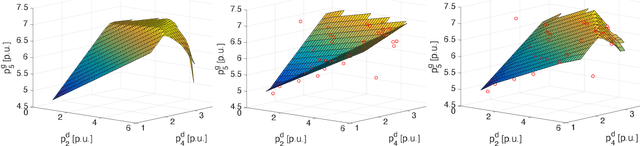
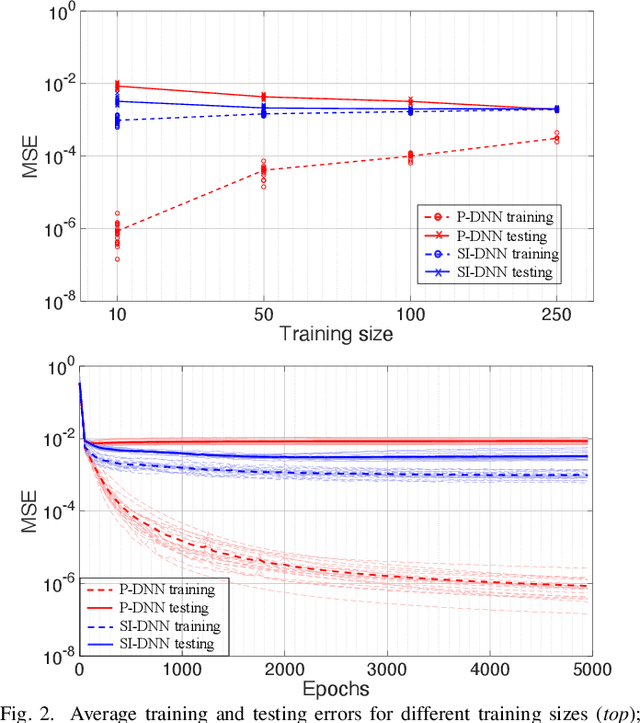
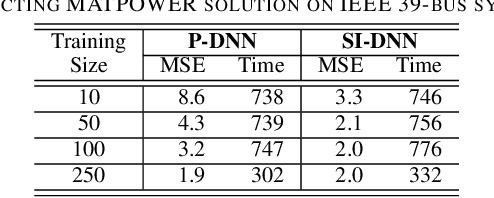
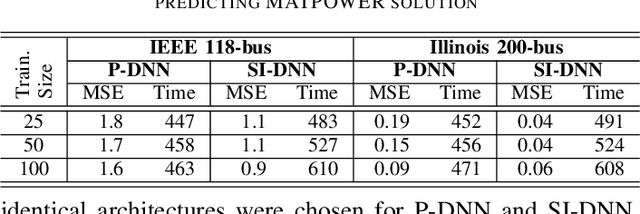
To shift the computational burden from real-time to offline in delay-critical power systems applications, recent works entertain the idea of using a deep neural network (DNN) to predict the solutions of the AC optimal power flow (AC-OPF) once presented load demands. As network topologies may change, training this DNN in a sample-efficient manner becomes a necessity. To improve data efficiency, this work utilizes the fact OPF data are not simple training labels, but constitute the solutions of a parametric optimization problem. We thus advocate training a sensitivity-informed DNN (SI-DNN) to match not only the OPF optimizers, but also their partial derivatives with respect to the OPF parameters (loads). It is shown that the required Jacobian matrices do exist under mild conditions, and can be readily computed from the related primal/dual solutions. The proposed SI-DNN is compatible with a broad range of OPF solvers, including a non-convex quadratically constrained quadratic program (QCQP), its semidefinite program (SDP) relaxation, and MATPOWER; while SI-DNN can be seamlessly integrated in other learning-to-OPF schemes. Numerical tests on three benchmark power systems corroborate the advanced generalization and constraint satisfaction capabilities for the OPF solutions predicted by an SI-DNN over a conventionally trained DNN, especially in low-data setups.
Adversarial Linear Contextual Bandits with Graph-Structured Side Observations
Dec 28, 2020
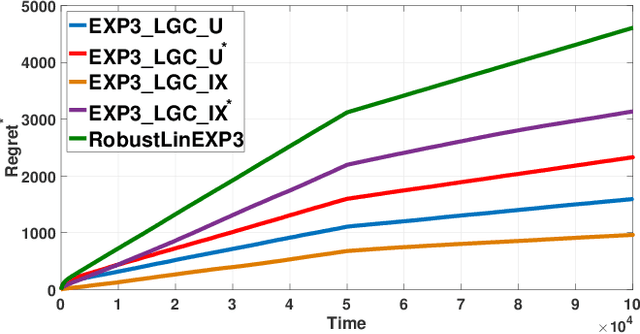
This paper studies the adversarial graphical contextual bandits, a variant of adversarial multi-armed bandits that leverage two categories of the most common side information: \emph{contexts} and \emph{side observations}. In this setting, a learning agent repeatedly chooses from a set of $K$ actions after being presented with a $d$-dimensional context vector. The agent not only incurs and observes the loss of the chosen action, but also observes the losses of its neighboring actions in the observation structures, which are encoded as a series of feedback graphs. This setting models a variety of applications in social networks, where both contexts and graph-structured side observations are available. Two efficient algorithms are developed based on \texttt{EXP3}. Under mild conditions, our analysis shows that for undirected feedback graphs the first algorithm, \texttt{EXP3-LGC-U}, achieves the regret of order $\mathcal{O}(\sqrt{(K+\alpha(G)d)T\log{K}})$ over the time horizon $T$, where $\alpha(G)$ is the average \emph{independence number} of the feedback graphs. A slightly weaker result is presented for the directed graph setting as well. The second algorithm, \texttt{EXP3-LGC-IX}, is developed for a special class of problems, for which the regret is reduced to $\mathcal{O}(\sqrt{\alpha(G)dT\log{K}\log(KT)})$ for both directed as well as undirected feedback graphs. Numerical tests corroborate the efficiency of proposed algorithms.
Bayesian Semi-supervised Crowdsourcing
Dec 20, 2020



Crowdsourcing has emerged as a powerful paradigm for efficiently labeling large datasets and performing various learning tasks, by leveraging crowds of human annotators. When additional information is available about the data, semi-supervised crowdsourcing approaches that enhance the aggregation of labels from human annotators are well motivated. This work deals with semi-supervised crowdsourced classification, under two regimes of semi-supervision: a) label constraints, that provide ground-truth labels for a subset of data; and b) potentially easier to obtain instance-level constraints, that indicate relationships between pairs of data. Bayesian algorithms based on variational inference are developed for each regime, and their quantifiably improved performance, compared to unsupervised crowdsourcing, is analytically and empirically validated on several crowdsourcing datasets.
Enhancing Parameter-Free Frank Wolfe with an Extra Subproblem
Dec 09, 2020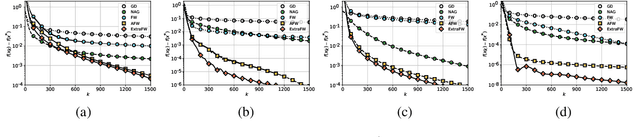

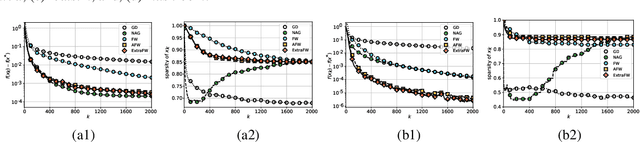
Aiming at convex optimization under structural constraints, this work introduces and analyzes a variant of the Frank Wolfe (FW) algorithm termed ExtraFW. The distinct feature of ExtraFW is the pair of gradients leveraged per iteration, thanks to which the decision variable is updated in a prediction-correction (PC) format. Relying on no problem dependent parameters in the step sizes, the convergence rate of ExtraFW for general convex problems is shown to be ${\cal O}(\frac{1}{k})$, which is optimal in the sense of matching the lower bound on the number of solved FW subproblems. However, the merit of ExtraFW is its faster rate ${\cal O}\big(\frac{1}{k^2} \big)$ on a class of machine learning problems. Compared with other parameter-free FW variants that have faster rates on the same problems, ExtraFW has improved rates and fine-grained analysis thanks to its PC update. Numerical tests on binary classification with different sparsity-promoting constraints demonstrate that the empirical performance of ExtraFW is significantly better than FW, and even faster than Nesterov's accelerated gradient on certain datasets. For matrix completion, ExtraFW enjoys smaller optimality gap, and lower rank than FW.
Learning while Respecting Privacy and Robustness to Distributional Uncertainties and Adversarial Data
Jul 07, 2020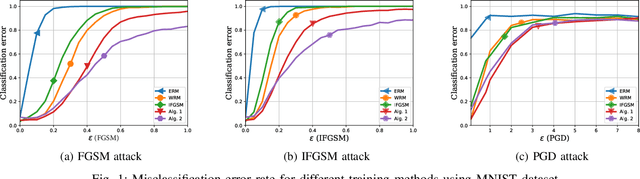
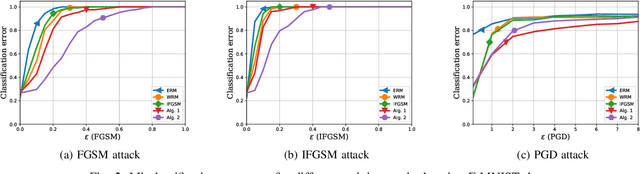
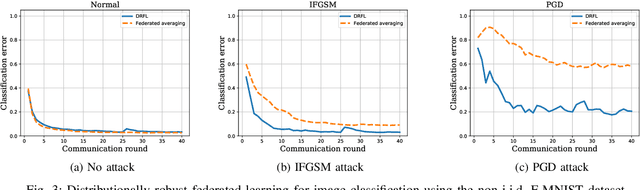
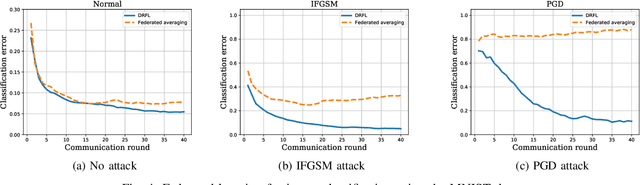
Data used to train machine learning models can be adversarial--maliciously constructed by adversaries to fool the model. Challenge also arises by privacy, confidentiality, or due to legal constraints when data are geographically gathered and stored across multiple learners, some of which may hold even an "anonymized" or unreliable dataset. In this context, the distributionally robust optimization framework is considered for training a parametric model, both in centralized and federated learning settings. The objective is to endow the trained model with robustness against adversarially manipulated input data, or, distributional uncertainties, such as mismatches between training and testing data distributions, or among datasets stored at different workers. To this aim, the data distribution is assumed unknown, and lies within a Wasserstein ball centered around the empirical data distribution. This robust learning task entails an infinite-dimensional optimization problem, which is challenging. Leveraging a strong duality result, a surrogate is obtained, for which three stochastic primal-dual algorithms are developed: i) stochastic proximal gradient descent with an $\epsilon$-accurate oracle, which invokes an oracle to solve the convex sub-problems; ii) stochastic proximal gradient descent-ascent, which approximates the solution of the convex sub-problems via a single gradient ascent step; and, iii) a distributionally robust federated learning algorithm, which solves the sub-problems locally at different workers where data are stored. Compared to the empirical risk minimization and federated learning methods, the proposed algorithms offer robustness with little computation overhead. Numerical tests using image datasets showcase the merits of the proposed algorithms under several existing adversarial attacks and distributional uncertainties.
How Does Momentum Help Frank Wolfe?
Jun 19, 2020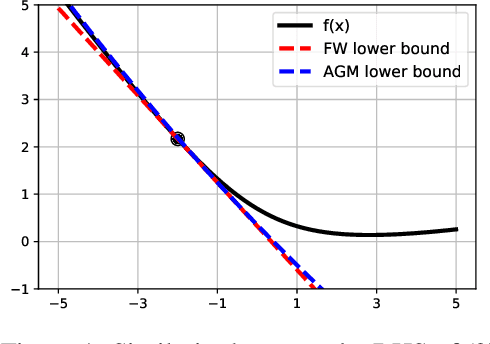
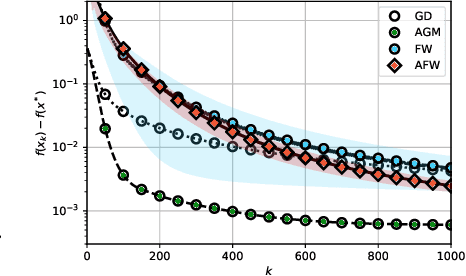
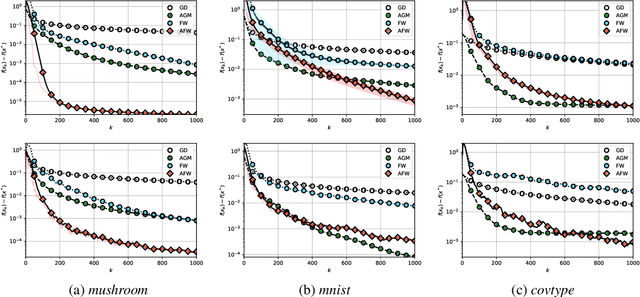
We unveil the connections between Frank Wolfe (FW) type algorithms and the momentum in Accelerated Gradient Methods (AGM). On the negative side, these connections illustrate why momentum is unlikely to be effective for FW type algorithms. The encouraging message behind this link, on the other hand, is that momentum is useful for FW on a class of problems. In particular, we prove that a momentum variant of FW, that we term accelerated Frank Wolfe (AFW), converges with a faster rate $\tilde{\cal O}(\frac{1}{k^2})$ on certain constraint sets despite the same ${\cal O}(\frac{1}{k})$ rate as FW on general cases. Given the possible acceleration of AFW at almost no extra cost, it is thus a competitive alternative to FW. Numerical experiments on benchmarked machine learning tasks further validate our theoretical findings.
Communication-Efficient Robust Federated Learning Over Heterogeneous Datasets
Jun 17, 2020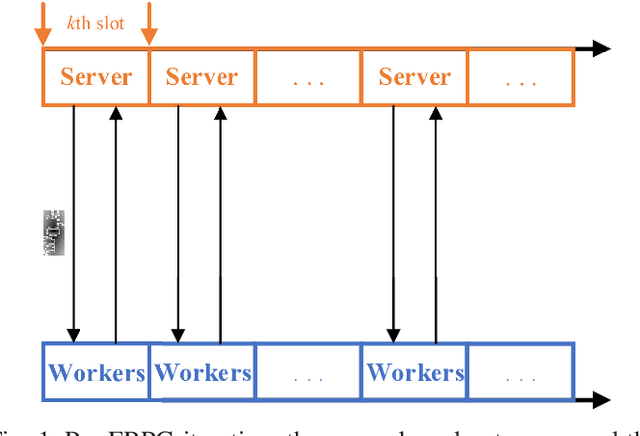
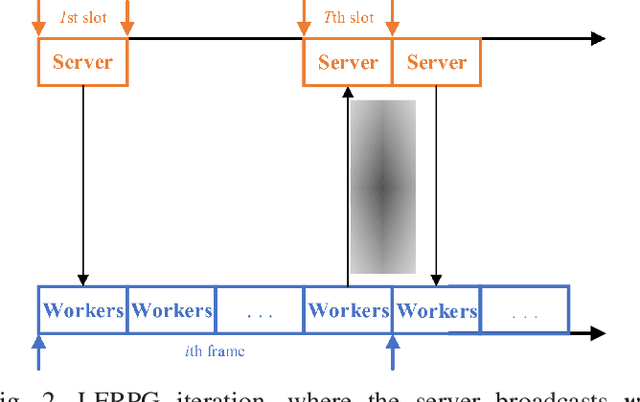
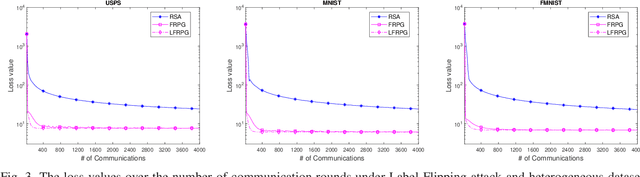
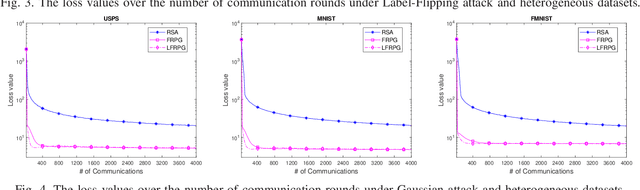
This work investigates fault-resilient federated learning when the data samples are non-uniformly distributed across workers, and the number of faulty workers is unknown to the central server. In the presence of adversarially faulty workers who may strategically corrupt datasets, the local messages exchanged (e.g., local gradients and/or local model parameters) can be unreliable, and thus the vanilla stochastic gradient descent (SGD) algorithm is not guaranteed to converge. Recently developed algorithms improve upon vanilla SGD by providing robustness to faulty workers at the price of slowing down convergence. To remedy this limitation, the present work introduces a fault-resilient proximal gradient (FRPG) algorithm that relies on Nesterov's acceleration technique. To reduce the communication overhead of FRPG, a local (L) FRPG algorithm is also developed to allow for intermittent server-workers parameter exchanges. For strongly convex loss functions, FRPG and LFRPG have provably faster convergence rates than a benchmark robust stochastic aggregation algorithm. Moreover, LFRPG converges faster than FRPG while using the same communication rounds. Numerical tests performed on various real datasets confirm the accelerated convergence of FRPG and LFRPG over the robust stochastic aggregation benchmark and competing alternatives.