 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRAND: Sequence-Conditioned Transport for Single-Cell Perturbations
Feb 10, 2026Predicting how genetic perturbations change cellular state is a core problem for building controllable models of gene regulation. Perturbations targeting the same gene can produce different transcriptional responses depending on their genomic locus, including different transcription start sites and regulatory elements. Gene-level perturbation models collapse these distinct interventions into the same representation. We introduce STRAND, a generative model that predicts single-cell transcriptional responses by conditioning on regulatory DNA sequence. STRAND represents a perturbation by encoding the sequence at its genomic locus and uses this representation to parameterize a conditional transport process from control to perturbed cell states. Representing perturbations by sequence, rather than by a fixed set of gene identifiers, supports zero-shot inference at loci not seen during training and expands inference-time genomic coverage from ~1.5% for gene-level single-cell foundation models to ~95% of the genome. We evaluate STRAND on CRISPR perturbation datasets in K562, Jurkat, and RPE1 cells. STRAND improves discrimination scores by up to 33% in low-sample regimes, achieves the best average rank on unseen gene perturbation benchmarks, and improves transfer to novel cell lines by up to 0.14 in Pearson correlation. Ablations isolate the gains to sequence conditioning and transport, and case studies show that STRAND resolves functionally alternative transcription start sites missed by gene-level models.
Carbon Footprint Evaluation of Code Generation through LLM as a Service
Mar 30, 2025Due to increased computing use, data centers consume and emit a lot of energy and carbon. These contributions are expected to rise as big data analytics, digitization, and large AI models grow and become major components of daily working routines. To reduce the environmental impact of software development, green (sustainable) coding and claims that AI models can improve energy efficiency have grown in popularity. Furthermore, in the automotive industry, where software increasingly governs vehicle performance, safety, and user experience, the principles of green coding and AI-driven efficiency could significantly contribute to reducing the sector's environmental footprint. We present an overview of green coding and metrics to measure AI model sustainability awareness. This study introduces LLM as a service and uses a generative commercial AI language model, GitHub Copilot, to auto-generate code. Using sustainability metrics to quantify these AI models' sustainability awareness, we define the code's embodied and operational carbon.
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024


This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
Geometric Self-Supervised Pretraining on 3D Protein Structures using Subgraphs
Jun 20, 2024

Protein representation learning aims to learn informative protein embeddings capable of addressing crucial biological questions, such as protein function prediction. Although sequence-based transformer models have shown promising results by leveraging the vast amount of protein sequence data in a self-supervised way, there is still a gap in applying these methods to 3D protein structures. In this work, we propose a pre-training scheme going beyond trivial masking methods leveraging 3D and hierarchical structures of proteins. We propose a novel self-supervised method to pretrain 3D graph neural networks on 3D protein structures, by predicting the distances between local geometric centroids of protein subgraphs and the global geometric centroid of the protein. The motivation for this method is twofold. First, the relative spatial arrangements and geometric relationships among different regions of a protein are crucial for its function. Moreover, proteins are often organized in a hierarchical manner, where smaller substructures, such as secondary structure elements, assemble into larger domains. By considering subgraphs and their relationships to the global protein structure, the model can learn to reason about these hierarchical levels of organization. We experimentally show that our proposed pertaining strategy leads to significant improvements in the performance of 3D GNNs in various protein classification tasks.
E(n) Equivariant Topological Neural Networks
May 24, 2024



Graph neural networks excel at modeling pairwise interactions, but they cannot flexibly accommodate higher-order interactions and features. Topological deep learning (TDL) has emerged recently as a promising tool for addressing this issue. TDL enables the principled modeling of arbitrary multi-way, hierarchical higher-order interactions by operating on combinatorial topological spaces, such as simplicial or cell complexes, instead of graphs. However, little is known about how to leverage geometric features such as positions and velocities for TDL. This paper introduces E(n)-Equivariant Topological Neural Networks (ETNNs), which are E(n)-equivariant message-passing networks operating on combinatorial complexes, formal objects unifying graphs, hypergraphs, simplicial, path, and cell complexes. ETNNs incorporate geometric node features while respecting rotation and translation equivariance. Moreover, ETNNs are natively ready for settings with heterogeneous interactions. We provide a theoretical analysis to show the improved expressiveness of ETNNs over architectures for geometric graphs. We also show how several E(n) equivariant variants of TDL models can be directly derived from our framework. The broad applicability of ETNNs is demonstrated through two tasks of vastly different nature: i) molecular property prediction on the QM9 benchmark and ii) land-use regression for hyper-local estimation of air pollution with multi-resolution irregular geospatial data. The experiment results indicate that ETNNs are an effective tool for learning from diverse types of richly structured data, highlighting the benefits of principled geometric inductive bias.
Learn to Code Sustainably: An Empirical Study on LLM-based Green Code Generation
Mar 05, 2024The increasing use of information technology has led to a significant share of energy consumption and carbon emissions from data centers. These contributions are expected to rise with the growing demand for big data analytics, increasing digitization, and the development of large artificial intelligence (AI) models. The need to address the environmental impact of software development has led to increased interest in green (sustainable) coding and claims that the use of AI models can lead to energy efficiency gains. Here, we provide an empirical study on green code and an overview of green coding practices, as well as metrics used to quantify the sustainability awareness of AI models. In this framework, we evaluate the sustainability of auto-generated code. The auto-generate codes considered in this study are produced by generative commercial AI language models, GitHub Copilot, OpenAI ChatGPT-3, and Amazon CodeWhisperer. Within our methodology, in order to quantify the sustainability awareness of these AI models, we propose a definition of the code's "green capacity", based on certain sustainability metrics. We compare the performance and green capacity of human-generated code and code generated by the three AI language models in response to easy-to-hard problem statements. Our findings shed light on the current capacity of AI models to contribute to sustainable software development.
Learn2Extend: Extending sequences by retaining their statistical properties with mixture models
Dec 03, 2023



This paper addresses the challenge of extending general finite sequences of real numbers within a subinterval of the real line, maintaining their inherent statistical properties by employing machine learning. Our focus lies on preserving the gap distribution and pair correlation function of these point sets. Leveraging advancements in deep learning applied to point processes, this paper explores the use of an auto-regressive \textit{Sequence Extension Mixture Model} (SEMM) for extending finite sequences, by estimating directly the conditional density, instead of the intensity function. We perform comparative experiments on multiple types of point processes, including Poisson, locally attractive, and locally repelling sequences, and we perform a case study on the prediction of Riemann $\zeta$ function zeroes. The results indicate that the proposed mixture model outperforms traditional neural network architectures in sequence extension with the retention of statistical properties. Given this motivation, we showcase the capabilities of a mixture model to extend sequences, maintaining specific statistical properties, i.e. the gap distribution, and pair correlation indicators.
GNNDelete: A General Strategy for Unlearning in Graph Neural Networks
Feb 26, 2023



Graph unlearning, which involves deleting graph elements such as nodes, node labels, and relationships from a trained graph neural network (GNN) model, is crucial for real-world applications where data elements may become irrelevant, inaccurate, or privacy-sensitive. However, existing methods for graph unlearning either deteriorate model weights shared across all nodes or fail to effectively delete edges due to their strong dependence on local graph neighborhoods. To address these limitations, we introduce GNNDelete, a novel model-agnostic layer-wise operator that optimizes two critical properties, namely, Deleted Edge Consistency and Neighborhood Influence, for graph unlearning. Deleted Edge Consistency ensures that the influence of deleted elements is removed from both model weights and neighboring representations, while Neighborhood Influence guarantees that the remaining model knowledge is preserved after deletion. GNNDelete updates representations to delete nodes and edges from the model while retaining the rest of the learned knowledge. We conduct experiments on seven real-world graphs, showing that GNNDelete outperforms existing approaches by up to 38.8% (AUC) on edge, node, and node feature deletion tasks, and 32.2% on distinguishing deleted edges from non-deleted ones. Additionally, GNNDelete is efficient, taking 12.3x less time and 9.3x less space than retraining GNN from scratch on WordNet18.
New Frontiers in Graph Autoencoders: Joint Community Detection and Link Prediction
Nov 16, 2022



Graph autoencoders (GAE) and variational graph autoencoders (VGAE) emerged as powerful methods for link prediction (LP). Their performances are less impressive on community detection (CD), where they are often outperformed by simpler alternatives such as the Louvain method. It is still unclear to what extent one can improve CD with GAE and VGAE, especially in the absence of node features. It is moreover uncertain whether one could do so while simultaneously preserving good performances on LP in a multi-task setting. In this workshop paper, summarizing results from our journal publication (Salha-Galvan et al. 2022), we show that jointly addressing these two tasks with high accuracy is possible. For this purpose, we introduce a community-preserving message passing scheme, doping our GAE and VGAE encoders by considering both the initial graph and Louvain-based prior communities when computing embedding spaces. Inspired by modularity-based clustering, we further propose novel training and optimization strategies specifically designed for joint LP and CD. We demonstrate the empirical effectiveness of our approach, referred to as Modularity-Aware GAE and VGAE, on various real-world graphs.
Geometric multimodal representation learning
Sep 07, 2022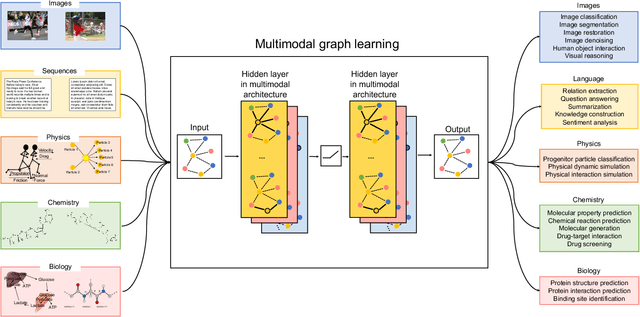
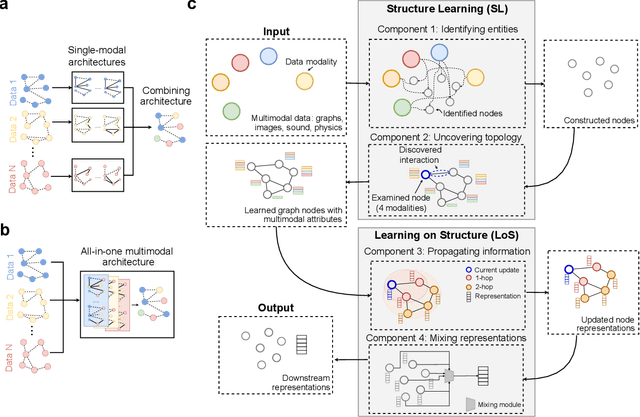
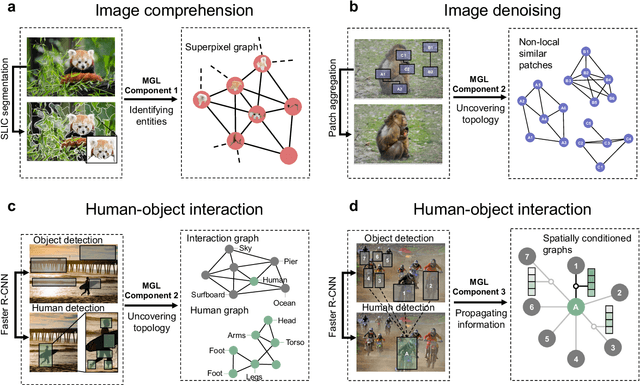
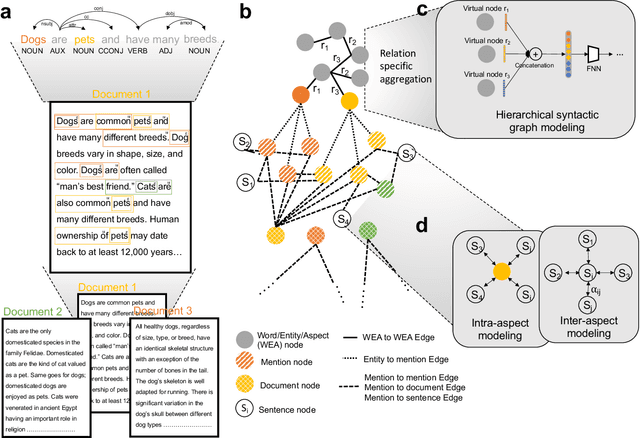
Graph-centric artificial intelligence (graph AI) has achieved remarkable success in modeling interacting systems prevalent in nature, from dynamical systems in biology to particle physics. The increasing heterogeneity of data calls for graph neural architectures that can combine multiple inductive biases. However, combining data from various sources is challenging because appropriate inductive bias may vary by data modality. Multimodal learning methods fuse multiple data modalities while leveraging cross-modal dependencies to address this challenge. Here, we survey 140 studies in graph-centric AI and realize that diverse data types are increasingly brought together using graphs and fed into sophisticated multimodal models. These models stratify into image-, language-, and knowledge-grounded multimodal learning. We put forward an algorithmic blueprint for multimodal graph learning based on this categorization. The blueprint serves as a way to group state-of-the-art architectures that treat multimodal data by choosing appropriately four different components. This effort can pave the way for standardizing the design of sophisticated multimodal architectures for highly complex real-world problems.