 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCvxNets: Learnable Convex Decomposition
Sep 12, 2019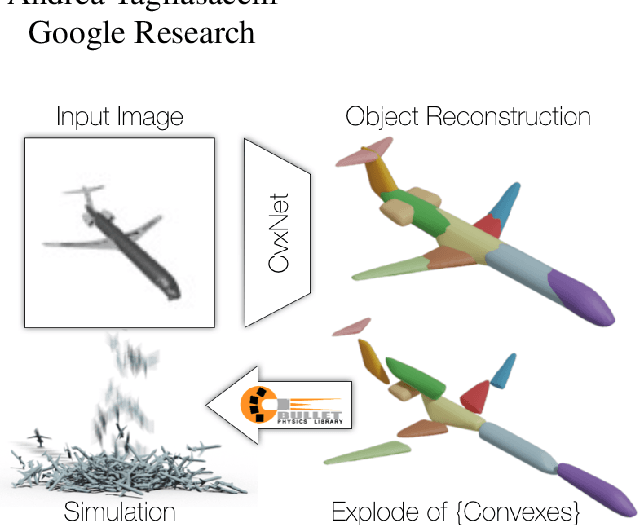
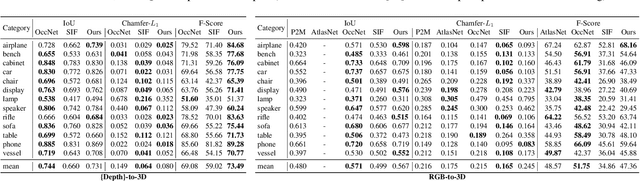
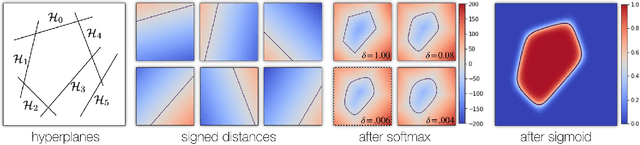
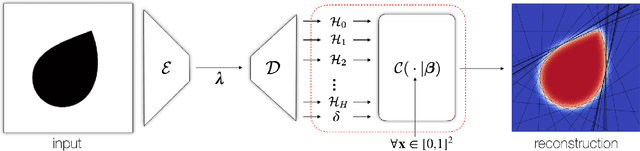
Any solid object can be decomposed into a collection of convex polytopes (in short, convexes). When a small number of convexes are used, such a decomposition can be thought of as a piece-wise approximation of the geometry. This decomposition is fundamental to real-time physics simulation in computer graphics, where it creates a unifying representation of dynamic geometry for collision detection. A convex object also has the property of being simultaneously an explicit and implicit representation: one can interpret it explicitly as a mesh derived by computing the vertices of a convex hull, or implicitly as the collection of half-space constraints or support functions. Their implicit representation makes them particularly well suited for neural network training, as they abstract away from the topology of the geometry they need to represent. We introduce a network architecture to represent a low dimensional family of convexes. This family is automatically derived via an autoencoding process. We investigate the applications of the network including automatic convex decomposition, image to 3D reconstruction, and part-based shape retrieval.
Lookahead Optimizer: k steps forward, 1 step back
Jul 19, 2019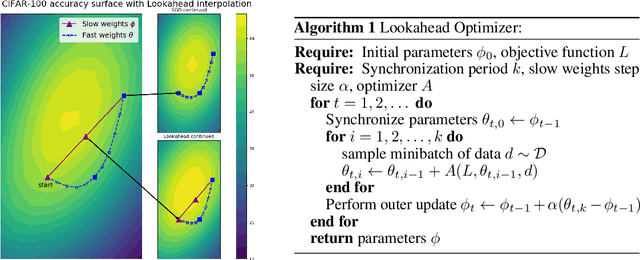

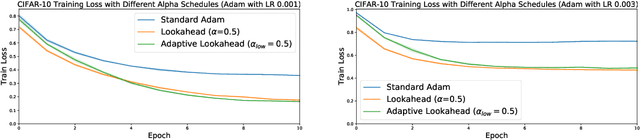

The vast majority of successful deep neural networks are trained using variants of stochastic gradient descent (SGD) algorithms. Recent attempts to improve SGD can be broadly categorized into two approaches: (1) adaptive learning rate schemes, such as AdaGrad and Adam, and (2) accelerated schemes, such as heavy-ball and Nesterov momentum. In this paper, we propose a new optimization algorithm, Lookahead, that is orthogonal to these previous approaches and iteratively updates two sets of weights. Intuitively, the algorithm chooses a search direction by \emph{looking ahead} at the sequence of "fast weights" generated by another optimizer. We show that Lookahead improves the learning stability and lowers the variance of its inner optimizer with negligible computation and memory cost. We empirically demonstrate Lookahead can significantly improve the performance of SGD and Adam, even with their default hyperparameter settings on ImageNet, CIFAR-10/100, neural machine translation, and Penn Treebank.
Detecting and Diagnosing Adversarial Images with Class-Conditional Capsule Reconstructions
Jul 05, 2019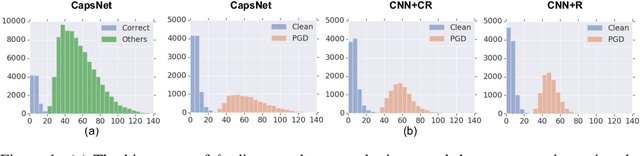
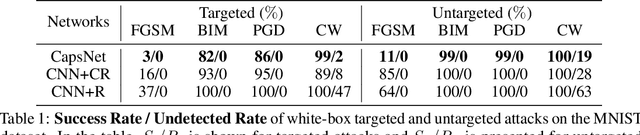
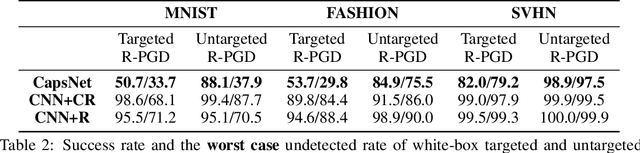

Adversarial examples raise questions about whether neural network models are sensitive to the same visual features as humans. Most of the proposed methods for mitigating adversarial examples have subsequently been defeated by stronger attacks. Motivated by these issues, we take a different approach and propose to instead detect adversarial examples based on class-conditional reconstructions of the input. Our method uses the reconstruction network proposed as part of Capsule Networks (CapsNets), but is general enough to be applied to standard convolutional networks. We find that adversarial or otherwise corrupted images result in much larger reconstruction errors than normal inputs, prompting a simple detection method by thresholding the reconstruction error. Based on these findings, we propose the Reconstructive Attack which seeks both to cause a misclassification and a low reconstruction error. While this attack produces undetected adversarial examples, we find that for CapsNets the resulting perturbations can cause the images to appear visually more like the target class. This suggests that CapsNets utilize features that are more aligned with human perception and address the central issue raised by adversarial examples.
When Does Label Smoothing Help?
Jun 06, 2019
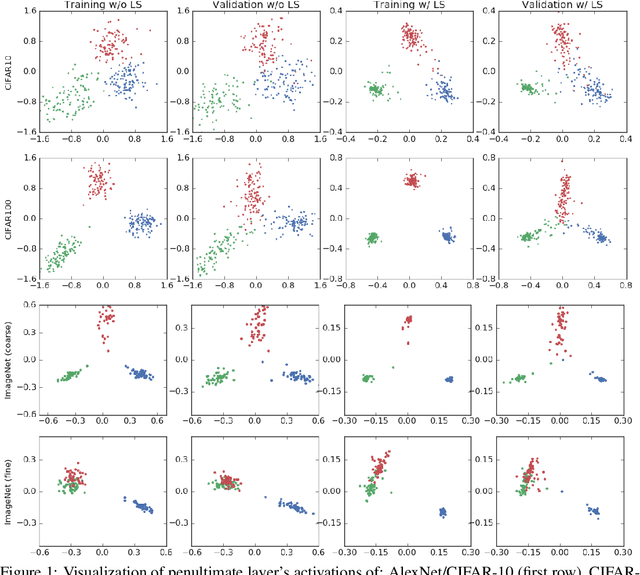

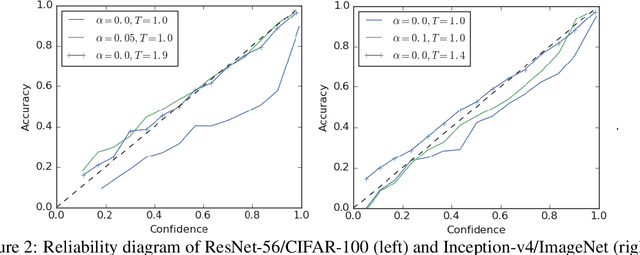
The generalization and learning speed of a multi-class neural network can often be significantly improved by using soft targets that are a weighted average of the hard targets and the uniform distribution over labels. Smoothing the labels in this way prevents the network from becoming over-confident and label smoothing has been used in many state-of-the-art models, including image classification, language translation and speech recognition. Despite its widespread use, label smoothing is still poorly understood. Here we show empirically that in addition to improving generalization, label smoothing improves model calibration which can significantly improve beam-search. However, we also observe that if a teacher network is trained with label smoothing, knowledge distillation into a student network is much less effective. To explain these observations, we visualize how label smoothing changes the representations learned by the penultimate layer of the network. We show that label smoothing encourages the representations of training examples from the same class to group in tight clusters. This results in loss of information in the logits about resemblances between instances of different classes, which is necessary for distillation, but does not hurt generalization or calibration of the model's predictions.
Cerberus: A Multi-headed Derenderer
May 28, 2019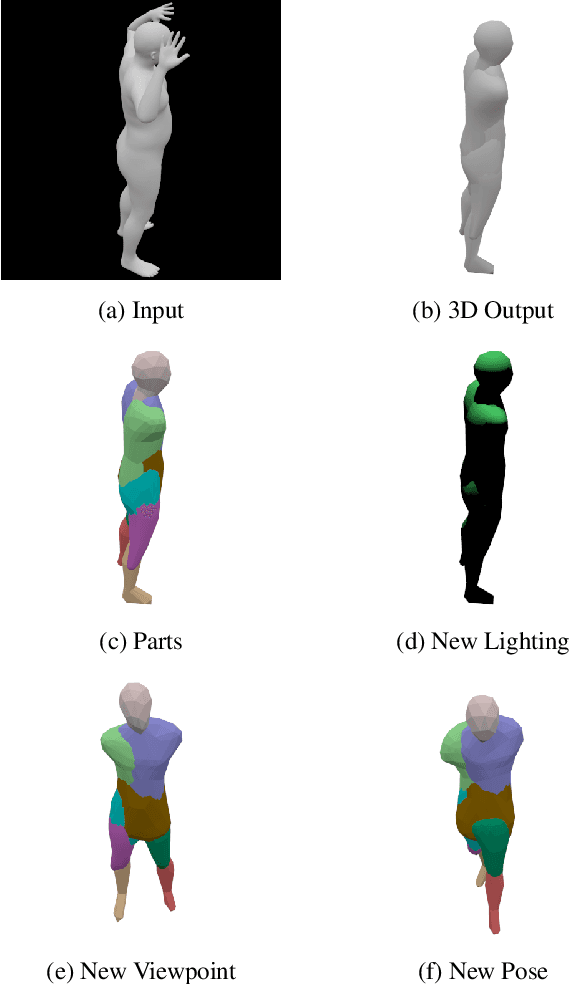

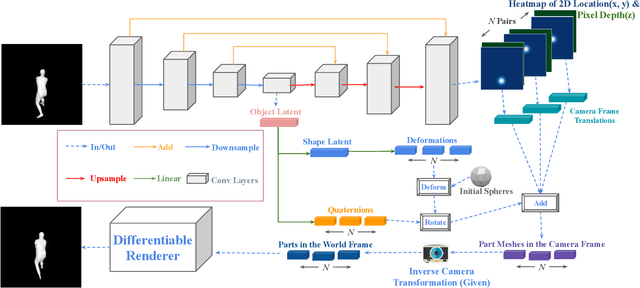
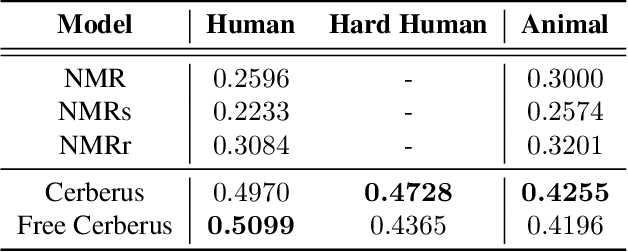
To generalize to novel visual scenes with new viewpoints and new object poses, a visual system needs representations of the shapes of the parts of an object that are invariant to changes in viewpoint or pose. 3D graphics representations disentangle visual factors such as viewpoints and lighting from object structure in a natural way. It is possible to learn to invert the process that converts 3D graphics representations into 2D images, provided the 3D graphics representations are available as labels. When only the unlabeled images are available, however, learning to derender is much harder. We consider a simple model which is just a set of free floating parts. Each part has its own relation to the camera and its own triangular mesh which can be deformed to model the shape of the part. At test time, a neural network looks at a single image and extracts the shapes of the parts and their relations to the camera. Each part can be viewed as one head of a multi-headed derenderer. During training, the extracted parts are used as input to a differentiable 3D renderer and the reconstruction error is backpropagated to train the neural net. We make the learning task easier by encouraging the deformations of the part meshes to be invariant to changes in viewpoint and invariant to the changes in the relative positions of the parts that occur when the pose of an articulated body changes. Cerberus, our multi-headed derenderer, outperforms previous methods for extracting 3D parts from single images without part annotations, and it does quite well at extracting natural parts of human figures.
Similarity of Neural Network Representations Revisited
May 14, 2019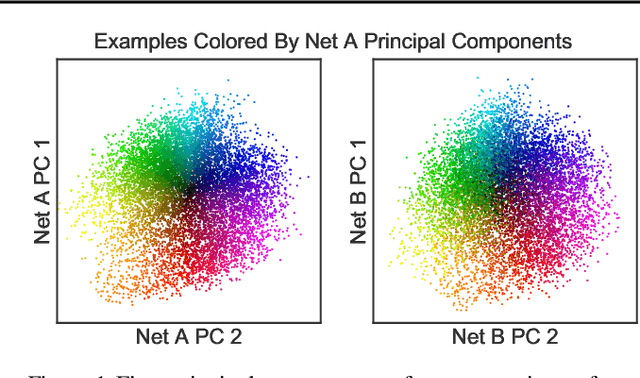

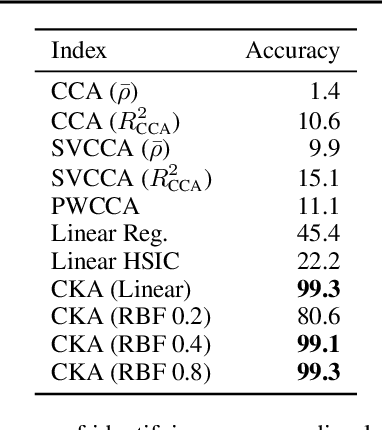
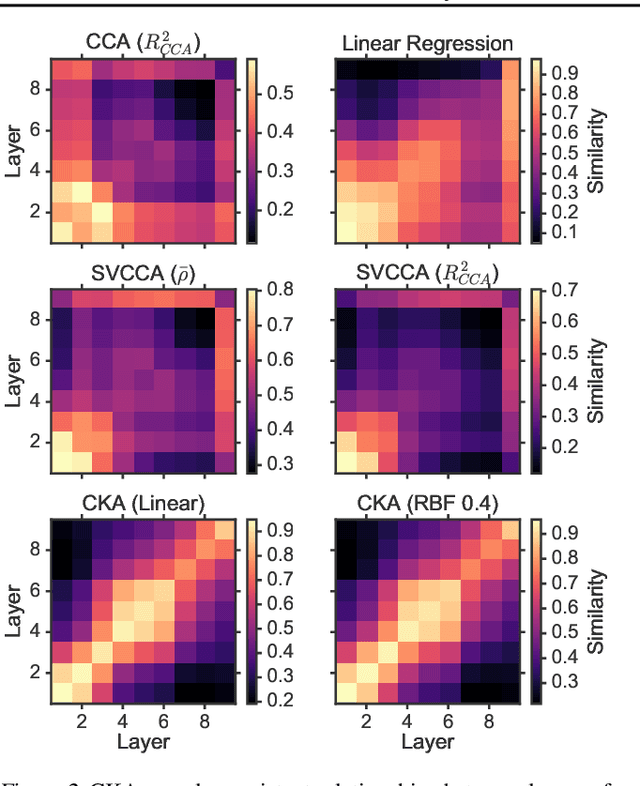
Recent work has sought to understand the behavior of neural networks by comparing representations between layers and between different trained models. We examine methods for comparing neural network representations based on canonical correlation analysis (CCA). We show that CCA belongs to a family of statistics for measuring multivariate similarity, but that neither CCA nor any other statistic that is invariant to invertible linear transformation can measure meaningful similarities between representations of higher dimension than the number of data points. We introduce a similarity index that measures the relationship between representational similarity matrices and does not suffer from this limitation. This similarity index is equivalent to centered kernel alignment (CKA) and is also closely connected to CCA. Unlike CCA, CKA can reliably identify correspondences between representations in networks trained from different initializations.
Analyzing and Improving Representations with the Soft Nearest Neighbor Loss
Feb 05, 2019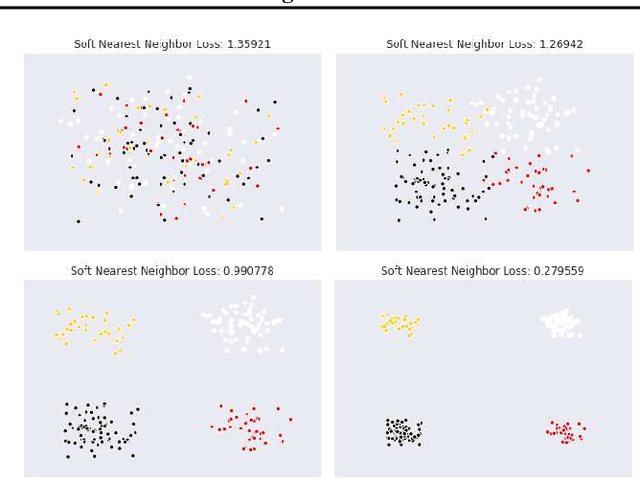
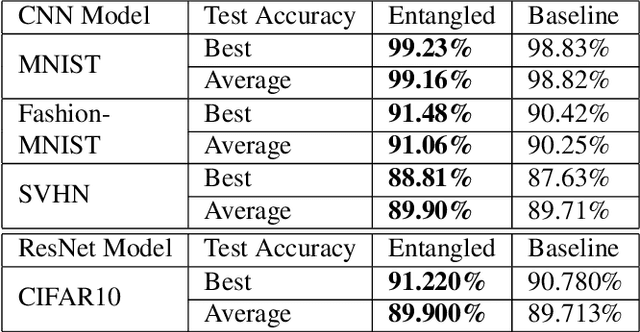
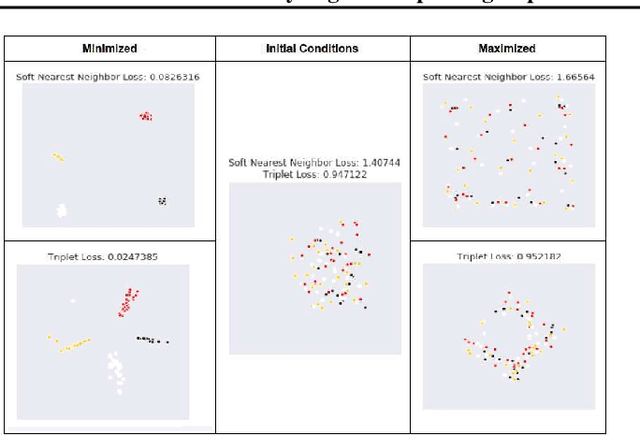
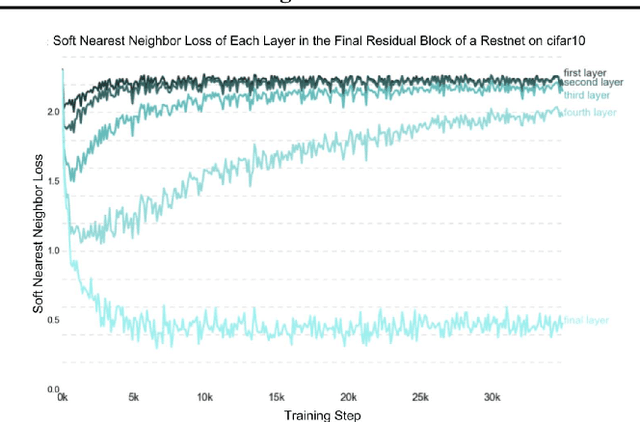
We explore and expand the $\textit{Soft Nearest Neighbor Loss}$ to measure the $\textit{entanglement}$ of class manifolds in representation space: i.e., how close pairs of points from the same class are relative to pairs of points from different classes. We demonstrate several use cases of the loss. As an analytical tool, it provides insights into the evolution of class similarity structures during learning. Surprisingly, we find that $\textit{maximizing}$ the entanglement of representations of different classes in the hidden layers is beneficial for discrimination in the final layer, possibly because it encourages representations to identify class-independent similarity structures. Maximizing the soft nearest neighbor loss in the hidden layers leads not only to improved generalization but also to better-calibrated estimates of uncertainty on outlier data. Data that is not from the training distribution can be recognized by observing that in the hidden layers, it has fewer than the normal number of neighbors from the predicted class.
DARCCC: Detecting Adversaries by Reconstruction from Class Conditional Capsules
Nov 16, 2018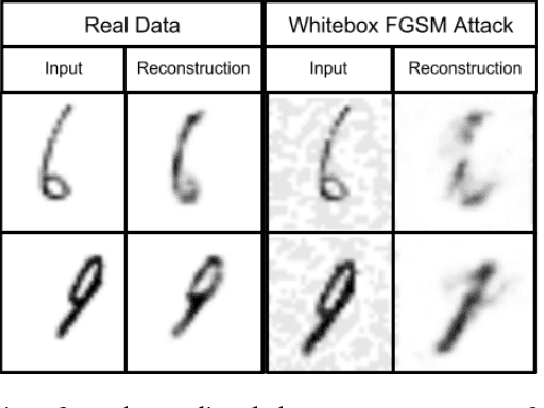

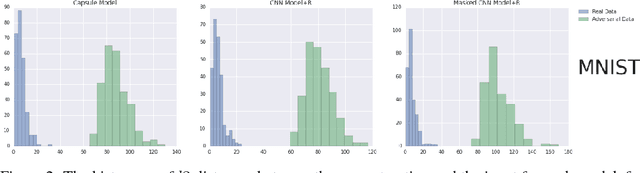
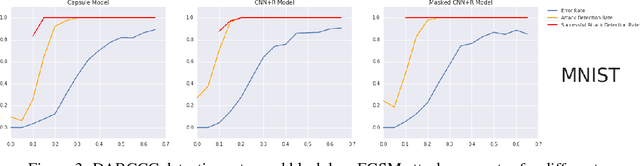
We present a simple technique that allows capsule models to detect adversarial images. In addition to being trained to classify images, the capsule model is trained to reconstruct the images from the pose parameters and identity of the correct top-level capsule. Adversarial images do not look like a typical member of the predicted class and they have much larger reconstruction errors when the reconstruction is produced from the top-level capsule for that class. We show that setting a threshold on the $l2$ distance between the input image and its reconstruction from the winning capsule is very effective at detecting adversarial images for three different datasets. The same technique works quite well for CNNs that have been trained to reconstruct the image from all or part of the last hidden layer before the softmax. We then explore a stronger, white-box attack that takes the reconstruction error into account. This attack is able to fool our detection technique but in order to make the model change its prediction to another class, the attack must typically make the "adversarial" image resemble images of the other class.
Distilling a Neural Network Into a Soft Decision Tree
Nov 27, 2017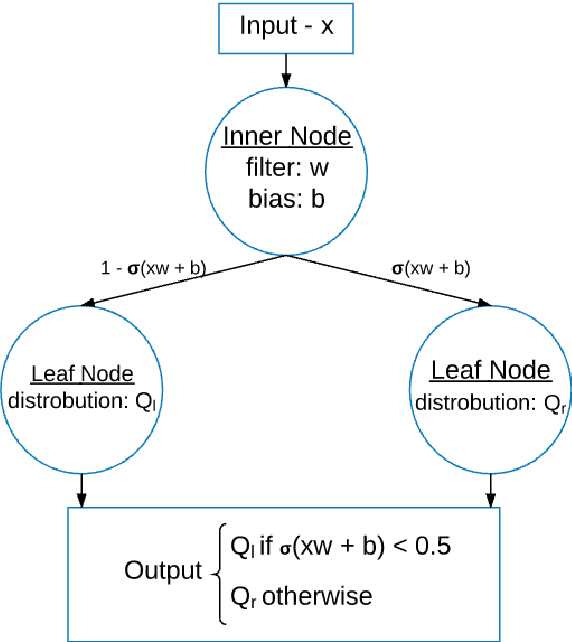
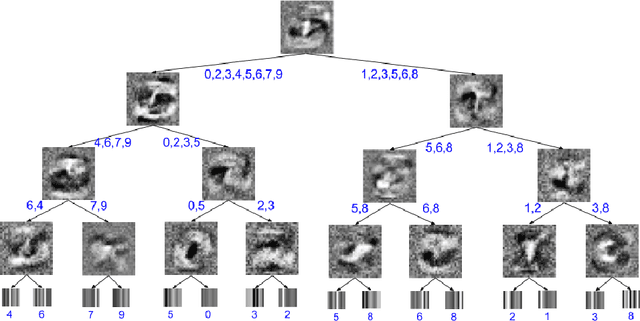

Deep neural networks have proved to be a very effective way to perform classification tasks. They excel when the input data is high dimensional, the relationship between the input and the output is complicated, and the number of labeled training examples is large. But it is hard to explain why a learned network makes a particular classification decision on a particular test case. This is due to their reliance on distributed hierarchical representations. If we could take the knowledge acquired by the neural net and express the same knowledge in a model that relies on hierarchical decisions instead, explaining a particular decision would be much easier. We describe a way of using a trained neural net to create a type of soft decision tree that generalizes better than one learned directly from the training data.
Regularizing Neural Networks by Penalizing Confident Output Distributions
Jan 23, 2017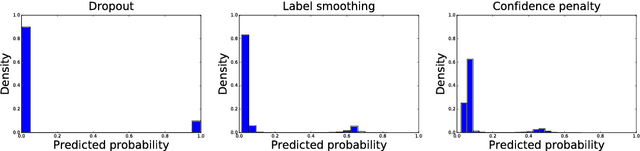
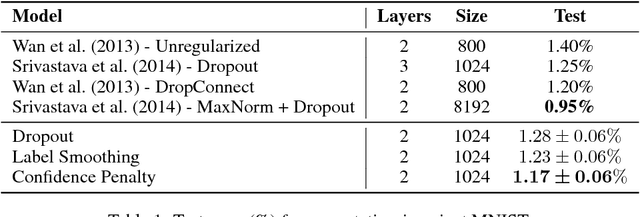
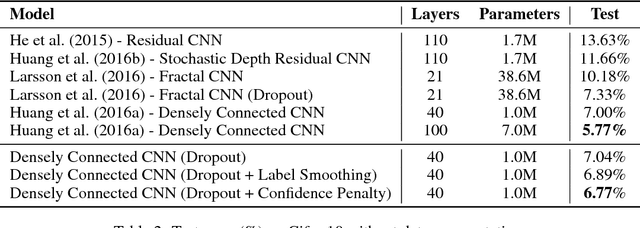
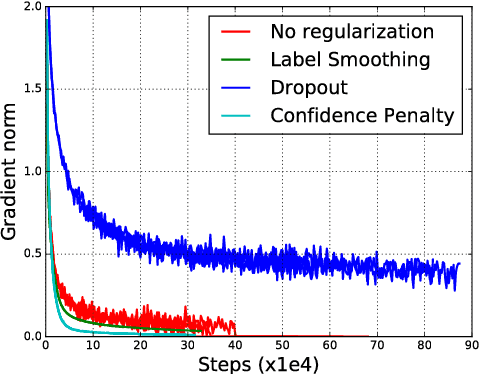
We systematically explore regularizing neural networks by penalizing low entropy output distributions. We show that penalizing low entropy output distributions, which has been shown to improve exploration in reinforcement learning, acts as a strong regularizer in supervised learning. Furthermore, we connect a maximum entropy based confidence penalty to label smoothing through the direction of the KL divergence. We exhaustively evaluate the proposed confidence penalty and label smoothing on 6 common benchmarks: image classification (MNIST and Cifar-10), language modeling (Penn Treebank), machine translation (WMT'14 English-to-German), and speech recognition (TIMIT and WSJ). We find that both label smoothing and the confidence penalty improve state-of-the-art models across benchmarks without modifying existing hyperparameters, suggesting the wide applicability of these regularizers.