 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubclass Distillation
Feb 10, 2020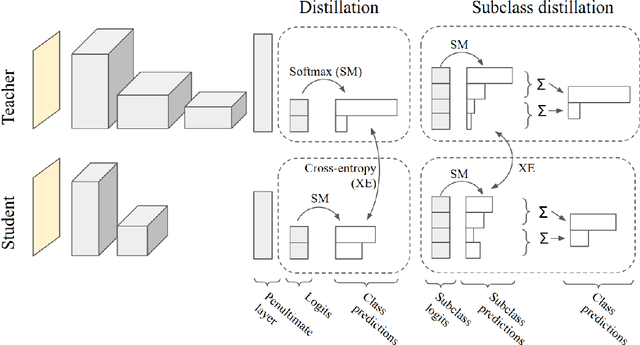

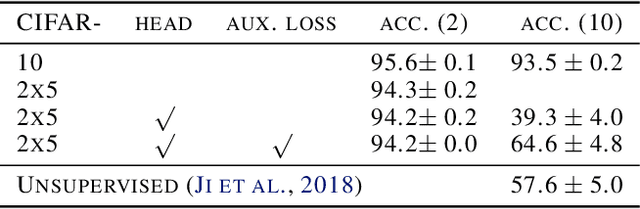
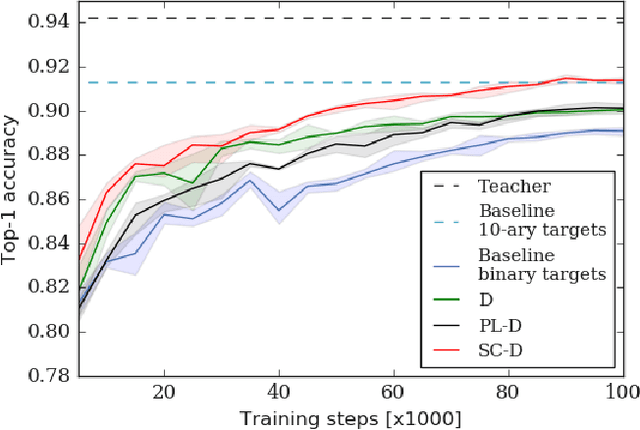
After a large "teacher" neural network has been trained on labeled data, the probabilities that the teacher assigns to incorrect classes reveal a lot of information about the way in which the teacher generalizes. By training a small "student" model to match these probabilities, it is possible to transfer most of the generalization ability of the teacher to the student, often producing a much better small model than directly training the student on the training data. The transfer works best when there are many possible classes because more is then revealed about the function learned by the teacher, but in cases where there are only a few possible classes we show that we can improve the transfer by forcing the teacher to divide each class into many subclasses that it invents during the supervised training. The student is then trained to match the subclass probabilities. For datasets where there are known, natural subclasses we demonstrate that the teacher learns similar subclasses and these improve distillation. For clickthrough datasets where the subclasses are unknown we demonstrate that subclass distillation allows the student to learn faster and better.
When Does Label Smoothing Help?
Jun 06, 2019
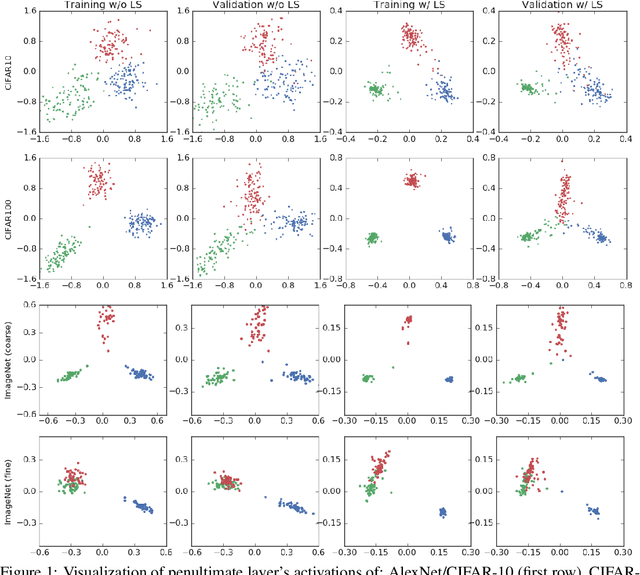

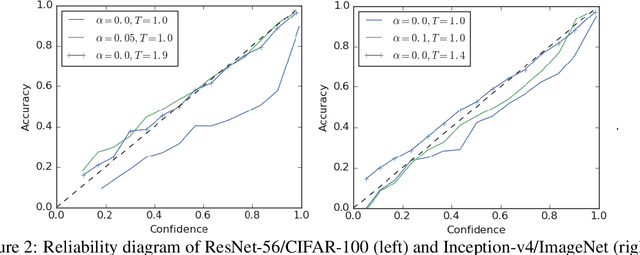
The generalization and learning speed of a multi-class neural network can often be significantly improved by using soft targets that are a weighted average of the hard targets and the uniform distribution over labels. Smoothing the labels in this way prevents the network from becoming over-confident and label smoothing has been used in many state-of-the-art models, including image classification, language translation and speech recognition. Despite its widespread use, label smoothing is still poorly understood. Here we show empirically that in addition to improving generalization, label smoothing improves model calibration which can significantly improve beam-search. However, we also observe that if a teacher network is trained with label smoothing, knowledge distillation into a student network is much less effective. To explain these observations, we visualize how label smoothing changes the representations learned by the penultimate layer of the network. We show that label smoothing encourages the representations of training examples from the same class to group in tight clusters. This results in loss of information in the logits about resemblances between instances of different classes, which is necessary for distillation, but does not hurt generalization or calibration of the model's predictions.