 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePix2seq: A Language Modeling Framework for Object Detection
Sep 22, 2021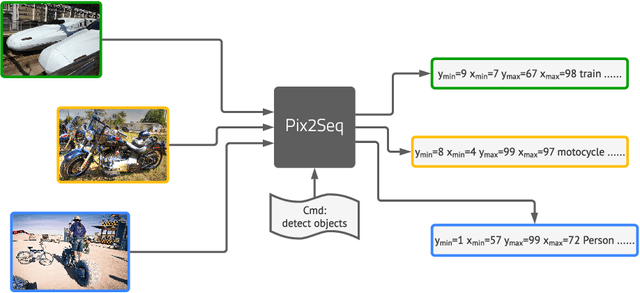
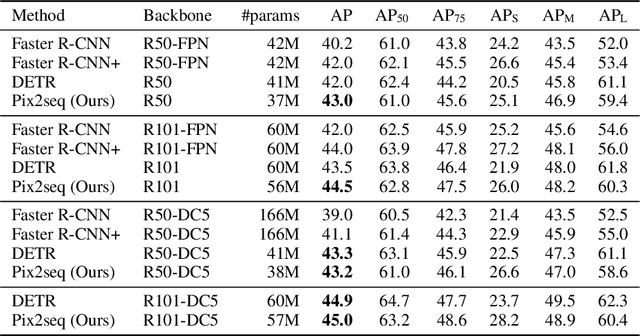
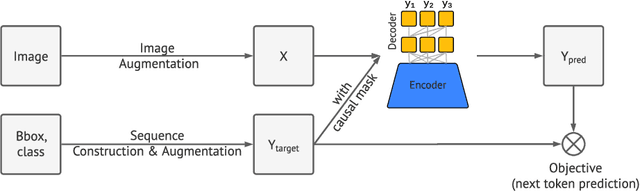
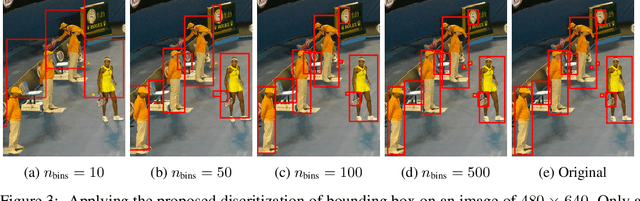
This paper presents Pix2Seq, a simple and generic framework for object detection. Unlike existing approaches that explicitly integrate prior knowledge about the task, we simply cast object detection as a language modeling task conditioned on the observed pixel inputs. Object descriptions (e.g., bounding boxes and class labels) are expressed as sequences of discrete tokens, and we train a neural net to perceive the image and generate the desired sequence. Our approach is based mainly on the intuition that if a neural net knows about where and what the objects are, we just need to teach it how to read them out. Beyond the use of task-specific data augmentations, our approach makes minimal assumptions about the task, yet it achieves competitive results on the challenging COCO dataset, compared to highly specialized and well optimized detection algorithms.
How to represent part-whole hierarchies in a neural network
Feb 25, 2021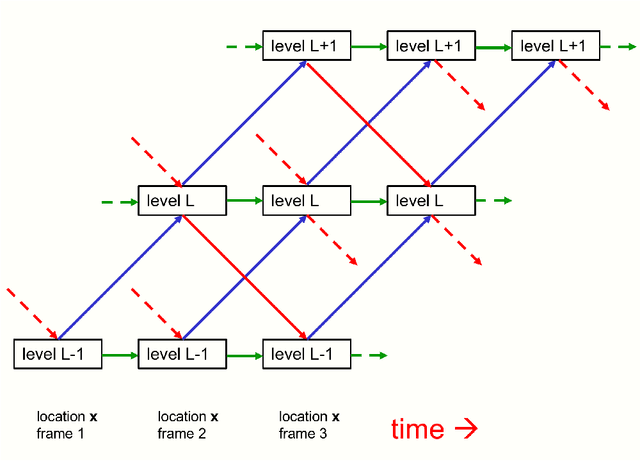
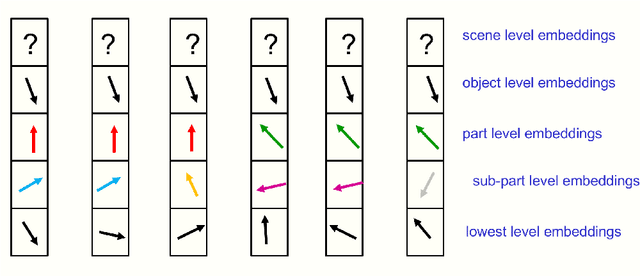
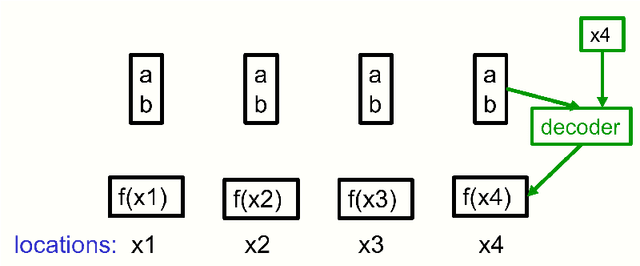
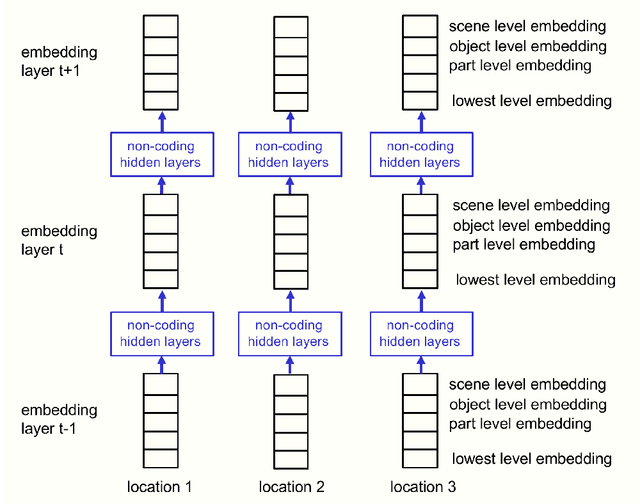
This paper does not describe a working system. Instead, it presents a single idea about representation which allows advances made by several different groups to be combined into an imaginary system called GLOM. The advances include transformers, neural fields, contrastive representation learning, distillation and capsules. GLOM answers the question: How can a neural network with a fixed architecture parse an image into a part-whole hierarchy which has a different structure for each image? The idea is simply to use islands of identical vectors to represent the nodes in the parse tree. If GLOM can be made to work, it should significantly improve the interpretability of the representations produced by transformer-like systems when applied to vision or language
Canonical Capsules: Unsupervised Capsules in Canonical Pose
Dec 08, 2020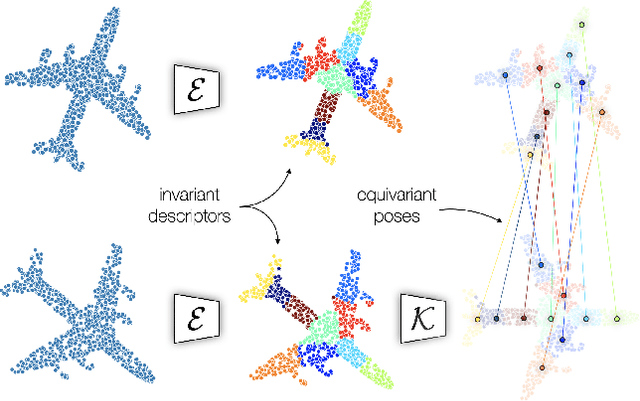
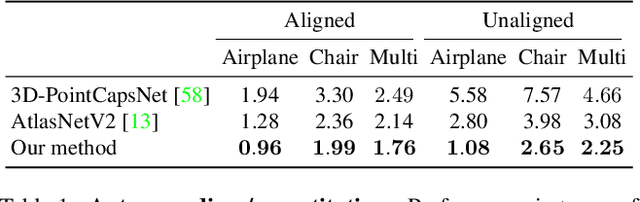

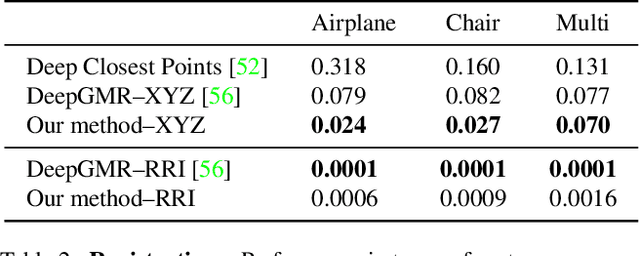
We propose an unsupervised capsule architecture for 3D point clouds. We compute capsule decompositions of objects through permutation-equivariant attention, and self-supervise the process by training with pairs of randomly rotated objects. Our key idea is to aggregate the attention masks into semantic keypoints, and use these to supervise a decomposition that satisfies the capsule invariance/equivariance properties. This not only enables the training of a semantically consistent decomposition, but also allows us to learn a canonicalization operation that enables object-centric reasoning. In doing so, we require neither classification labels nor manually-aligned training datasets to train. Yet, by learning an object-centric representation in an unsupervised manner, our method outperforms the state-of-the-art on 3D point cloud reconstruction, registration, and unsupervised classification. We will release the code and dataset to reproduce our results as soon as the paper is published.
Teaching with Commentaries
Nov 05, 2020
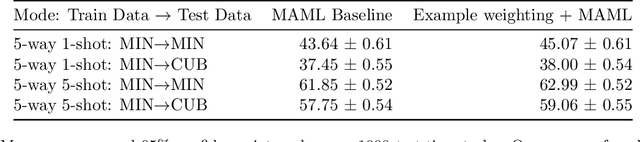
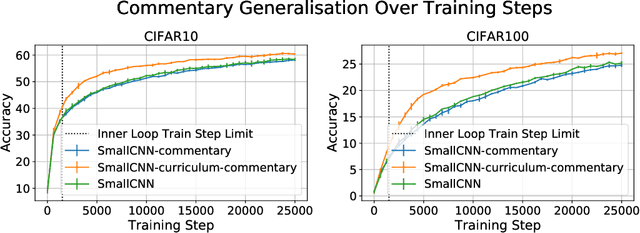

Effective training of deep neural networks can be challenging, and there remain many open questions on how to best learn these models. Recently developed methods to improve neural network training examine teaching: providing learned information during the training process to improve downstream model performance. In this paper, we take steps towards extending the scope of teaching. We propose a flexible teaching framework using commentaries, meta-learned information helpful for training on a particular task or dataset. We present an efficient and scalable gradient-based method to learn commentaries, leveraging recent work on implicit differentiation. We explore diverse applications of commentaries, from learning weights for individual training examples, to parameterizing label-dependent data augmentation policies, to representing attention masks that highlight salient image regions. In these settings, we find that commentaries can improve training speed and/or performance and also provide fundamental insights about the dataset and training process.
Big Self-Supervised Models are Strong Semi-Supervised Learners
Jun 17, 2020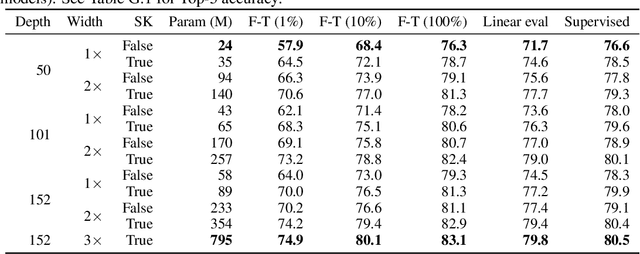
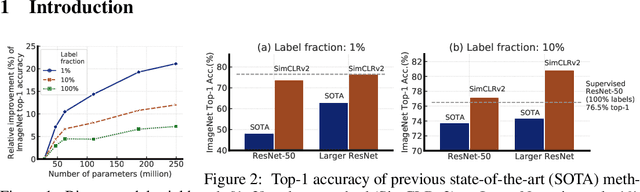
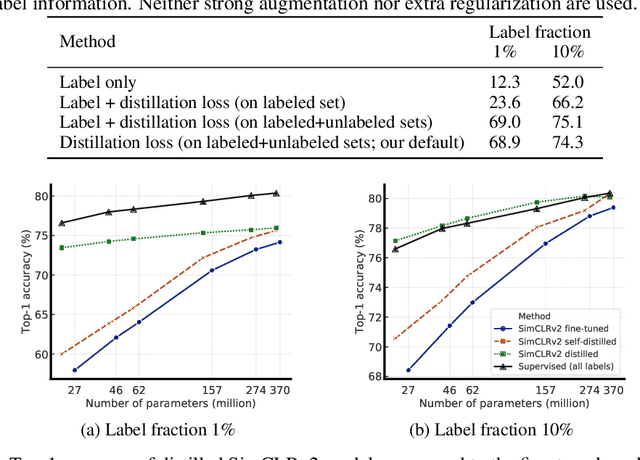
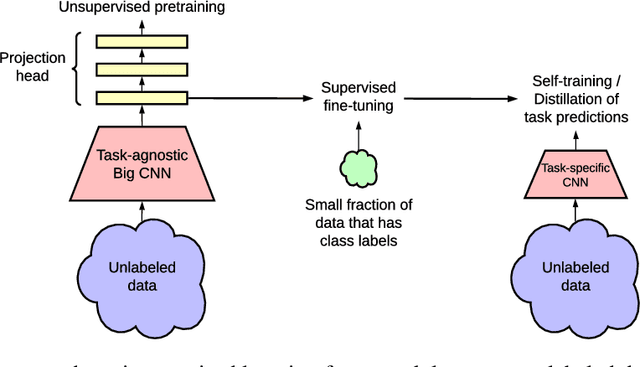
One paradigm for learning from few labeled examples while making best use of a large amount of unlabeled data is unsupervised pretraining followed by supervised fine-tuning. Although this paradigm uses unlabeled data in a task-agnostic way, in contrast to most previous approaches to semi-supervised learning for computer vision, we show that it is surprisingly effective for semi-supervised learning on ImageNet. A key ingredient of our approach is the use of a big (deep and wide) network during pretraining and fine-tuning. We find that, the fewer the labels, the more this approach (task-agnostic use of unlabeled data) benefits from a bigger network. After fine-tuning, the big network can be further improved and distilled into a much smaller one with little loss in classification accuracy by using the unlabeled examples for a second time, but in a task-specific way. The proposed semi-supervised learning algorithm can be summarized in three steps: unsupervised pretraining of a big ResNet model using SimCLRv2 (a modification of SimCLR), supervised fine-tuning on a few labeled examples, and distillation with unlabeled examples for refining and transferring the task-specific knowledge. This procedure achieves 73.9\% ImageNet top-1 accuracy with just 1\% of the labels ($\le$13 labeled images per class) using ResNet-50, a $10\times$ improvement in label efficiency over the previous state-of-the-art. With 10\% of labels, ResNet-50 trained with our method achieves 77.5\% top-1 accuracy, outperforming standard supervised training with all of the labels.
Imputer: Sequence Modelling via Imputation and Dynamic Programming
Feb 20, 2020
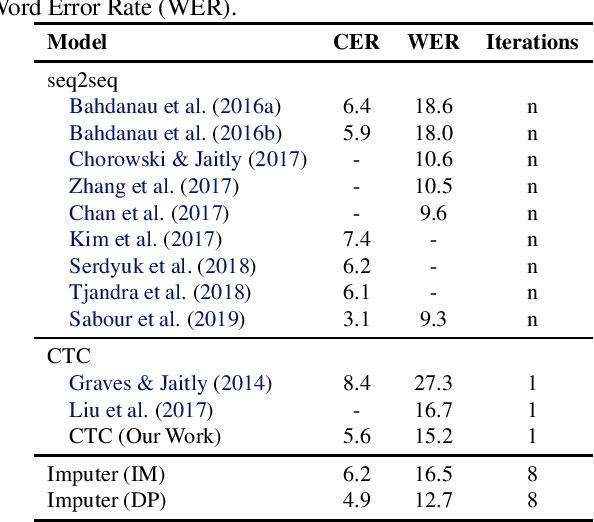
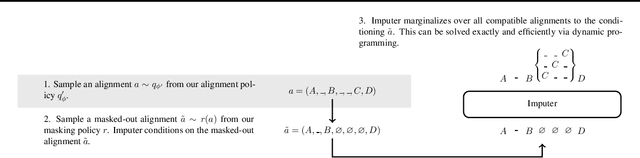
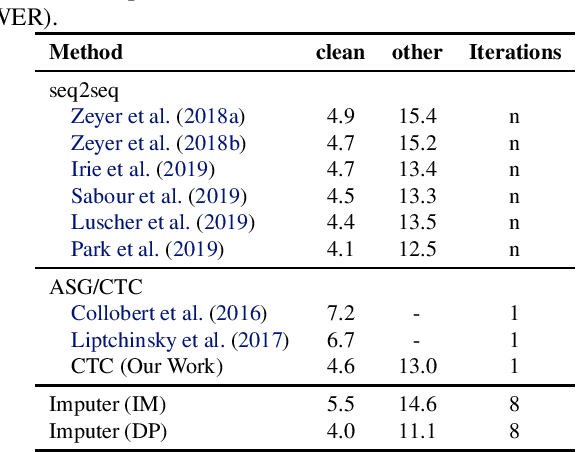
This paper presents the Imputer, a neural sequence model that generates output sequences iteratively via imputations. The Imputer is an iterative generative model, requiring only a constant number of generation steps independent of the number of input or output tokens. The Imputer can be trained to approximately marginalize over all possible alignments between the input and output sequences, and all possible generation orders. We present a tractable dynamic programming training algorithm, which yields a lower bound on the log marginal likelihood. When applied to end-to-end speech recognition, the Imputer outperforms prior non-autoregressive models and achieves competitive results to autoregressive models. On LibriSpeech test-other, the Imputer achieves 11.1 WER, outperforming CTC at 13.0 WER and seq2seq at 12.5 WER.
Deflecting Adversarial Attacks
Feb 18, 2020

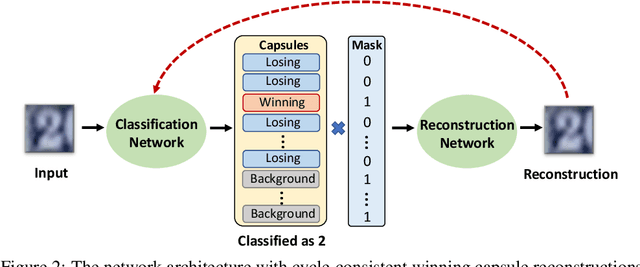

There has been an ongoing cycle where stronger defenses against adversarial attacks are subsequently broken by a more advanced defense-aware attack. We present a new approach towards ending this cycle where we "deflect'' adversarial attacks by causing the attacker to produce an input that semantically resembles the attack's target class. To this end, we first propose a stronger defense based on Capsule Networks that combines three detection mechanisms to achieve state-of-the-art detection performance on both standard and defense-aware attacks. We then show that undetected attacks against our defense often perceptually resemble the adversarial target class by performing a human study where participants are asked to label images produced by the attack. These attack images can no longer be called "adversarial'' because our network classifies them the same way as humans do.
A Simple Framework for Contrastive Learning of Visual Representations
Feb 13, 2020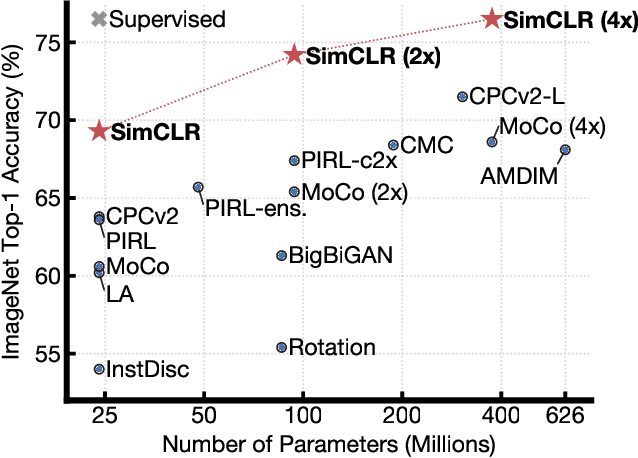

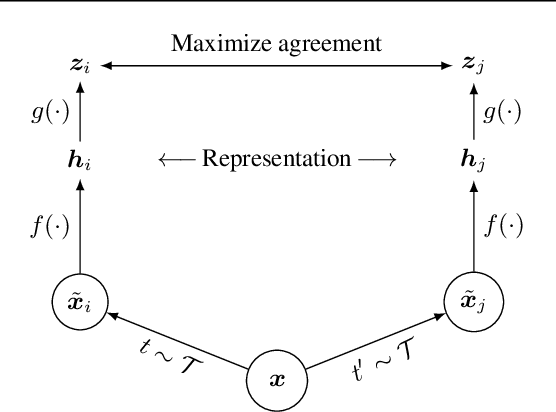

This paper presents SimCLR: a simple framework for contrastive learning of visual representations. We simplify recently proposed contrastive self-supervised learning algorithms without requiring specialized architectures or a memory bank. In order to understand what enables the contrastive prediction tasks to learn useful representations, we systematically study the major components of our framework. We show that (1) composition of data augmentations plays a critical role in defining effective predictive tasks, (2) introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations, and (3) contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning. By combining these findings, we are able to considerably outperform previous methods for self-supervised and semi-supervised learning on ImageNet. A linear classifier trained on self-supervised representations learned by SimCLR achieves 76.5% top-1 accuracy, which is a 7% relative improvement over previous state-of-the-art, matching the performance of a supervised ResNet-50. When fine-tuned on only 1% of the labels, we achieve 85.8% top-5 accuracy, outperforming AlexNet with 100X fewer labels.
Subclass Distillation
Feb 10, 2020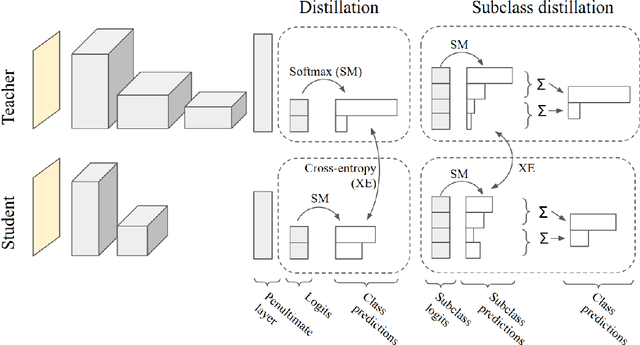

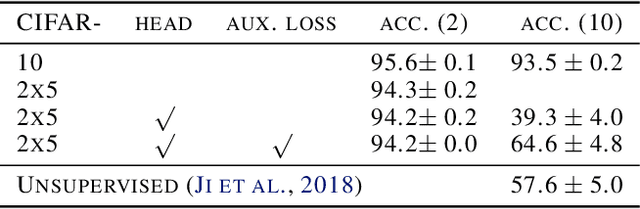
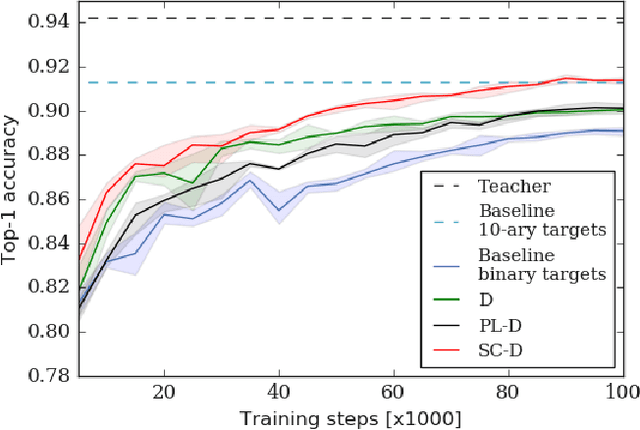
After a large "teacher" neural network has been trained on labeled data, the probabilities that the teacher assigns to incorrect classes reveal a lot of information about the way in which the teacher generalizes. By training a small "student" model to match these probabilities, it is possible to transfer most of the generalization ability of the teacher to the student, often producing a much better small model than directly training the student on the training data. The transfer works best when there are many possible classes because more is then revealed about the function learned by the teacher, but in cases where there are only a few possible classes we show that we can improve the transfer by forcing the teacher to divide each class into many subclasses that it invents during the supervised training. The student is then trained to match the subclass probabilities. For datasets where there are known, natural subclasses we demonstrate that the teacher learns similar subclasses and these improve distillation. For clickthrough datasets where the subclasses are unknown we demonstrate that subclass distillation allows the student to learn faster and better.
NASA: Neural Articulated Shape Approximation
Dec 06, 2019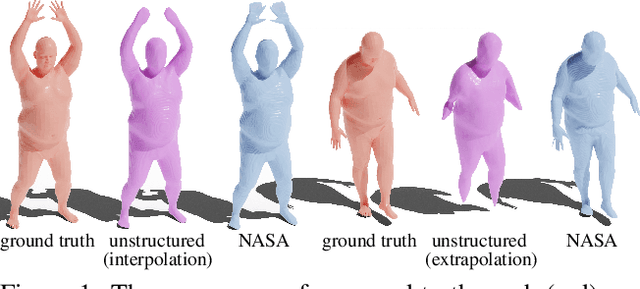
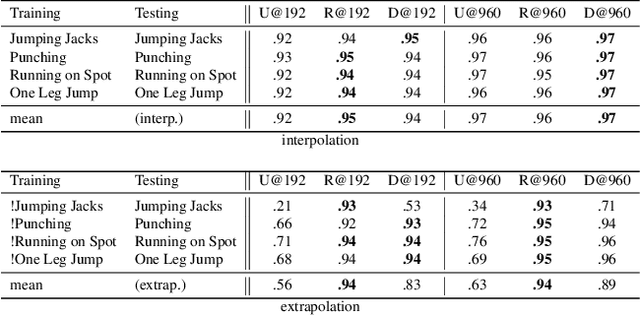


Efficient representation of articulated objects such as human bodies is an important problem in computer vision and graphics. To efficiently simulate deformation, existing approaches represent objects as meshes and deform them using skinning techniques. This paper introduces neural articulated shape approximation (NASA), a framework that enables efficient representation of articulated deformable objects using neural indicator functions parameterized by pose. In contrast to classic approaches, NASA avoids the need to convert between different representations. For occupancy testing, NASA circumvents the complexity of meshes and mitigates the issue of water-tightness. In comparison with regular grids and octrees, our approach provides high resolution without high memory use.