 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness of Prompt-based Few-Shot Learning for Natural Language Understanding
Jun 21, 2023State-of-the-art few-shot learning (FSL) methods leverage prompt-based fine-tuning to obtain remarkable results for natural language understanding (NLU) tasks. While much of the prior FSL methods focus on improving downstream task performance, there is a limited understanding of the adversarial robustness of such methods. In this work, we conduct an extensive study of several state-of-the-art FSL methods to assess their robustness to adversarial perturbations. To better understand the impact of various factors towards robustness (or the lack of it), we evaluate prompt-based FSL methods against fully fine-tuned models for aspects such as the use of unlabeled data, multiple prompts, number of few-shot examples, model size and type. Our results on six GLUE tasks indicate that compared to fully fine-tuned models, vanilla FSL methods lead to a notable relative drop in task performance (i.e., are less robust) in the face of adversarial perturbations. However, using (i) unlabeled data for prompt-based FSL and (ii) multiple prompts flip the trend. We further demonstrate that increasing the number of few-shot examples and model size lead to increased adversarial robustness of vanilla FSL methods. Broadly, our work sheds light on the adversarial robustness evaluation of prompt-based FSL methods for NLU tasks.
Cross-Modal Attribute Insertions for Assessing the Robustness of Vision-and-Language Learning
Jun 19, 2023The robustness of multimodal deep learning models to realistic changes in the input text is critical for their applicability to important tasks such as text-to-image retrieval and cross-modal entailment. To measure robustness, several existing approaches edit the text data, but do so without leveraging the cross-modal information present in multimodal data. Information from the visual modality, such as color, size, and shape, provide additional attributes that users can include in their inputs. Thus, we propose cross-modal attribute insertions as a realistic perturbation strategy for vision-and-language data that inserts visual attributes of the objects in the image into the corresponding text (e.g., "girl on a chair" to "little girl on a wooden chair"). Our proposed approach for cross-modal attribute insertions is modular, controllable, and task-agnostic. We find that augmenting input text using cross-modal insertions causes state-of-the-art approaches for text-to-image retrieval and cross-modal entailment to perform poorly, resulting in relative drops of 15% in MRR and 20% in $F_1$ score, respectively. Crowd-sourced annotations demonstrate that cross-modal insertions lead to higher quality augmentations for multimodal data than augmentations using text-only data, and are equivalent in quality to original examples. We release the code to encourage robustness evaluations of deep vision-and-language models: https://github.com/claws-lab/multimodal-robustness-xmai.
Large-Scale Text Analysis Using Generative Language Models: A Case Study in Discovering Public Value Expressions in AI Patents
May 18, 2023Labeling data is essential for training text classifiers but is often difficult to accomplish accurately, especially for complex and abstract concepts. Seeking an improved method, this paper employs a novel approach using a generative language model (GPT-4) to produce labels and rationales for large-scale text analysis. We apply this approach to the task of discovering public value expressions in US AI patents. We collect a database comprising 154,934 patent documents using an advanced Boolean query submitted to InnovationQ+. The results are merged with full patent text from the USPTO, resulting in 5.4 million sentences. We design a framework for identifying and labeling public value expressions in these AI patent sentences. A prompt for GPT-4 is developed which includes definitions, guidelines, examples, and rationales for text classification. We evaluate the quality of the labels and rationales produced by GPT-4 using BLEU scores and topic modeling and find that they are accurate, diverse, and faithful. These rationales also serve as a chain-of-thought for the model, a transparent mechanism for human verification, and support for human annotators to overcome cognitive limitations. We conclude that GPT-4 achieved a high-level of recognition of public value theory from our framework, which it also uses to discover unseen public value expressions. We use the labels produced by GPT-4 to train BERT-based classifiers and predict sentences on the entire database, achieving high F1 scores for the 3-class (0.85) and 2-class classification (0.91) tasks. We discuss the implications of our approach for conducting large-scale text analyses with complex and abstract concepts and suggest that, with careful framework design and interactive human oversight, generative language models can offer significant advantages in quality and in reduced time and costs for producing labels and rationales.
Learning the Visualness of Text Using Large Vision-Language Models
May 11, 2023Visual text evokes an image in a person's mind, while non-visual text fails to do so. A method to automatically detect visualness in text will unlock the ability to augment text with relevant images, as neural text-to-image generation and retrieval models operate on the implicit assumption that the input text is visual in nature. We curate a dataset of 3,620 English sentences and their visualness scores provided by multiple human annotators. Additionally, we use documents that contain text and visual assets to create a distantly supervised corpus of document text and associated images. We also propose a fine-tuning strategy that adapts large vision-language models like CLIP that assume a one-to-one correspondence between text and image to the task of scoring text visualness from text input alone. Our strategy involves modifying the model's contrastive learning objective to map text identified as non-visual to a common NULL image while matching visual text to their corresponding images in the document. We evaluate the proposed approach on its ability to (i) classify visual and non-visual text accurately, and (ii) attend over words that are identified as visual in psycholinguistic studies. Empirical evaluation indicates that our approach performs better than several heuristics and baseline models for the proposed task. Furthermore, to highlight the importance of modeling the visualness of text, we conduct qualitative analyses of text-to-image generation systems like DALL-E.
Transfer Learning Across Heterogeneous Features For Efficient Tensor Program Generation
Apr 11, 2023Tuning tensor program generation involves searching for various possible program transformation combinations for a given program on target hardware to optimize the tensor program execution. It is already a complex process because of the massive search space and exponential combinations of transformations make auto-tuning tensor program generation more challenging, especially when we have a heterogeneous target. In this research, we attempt to address these problems by learning the joint neural network and hardware features and transferring them to the new target hardware. We extensively study the existing state-of-the-art dataset, TenSet, perform comparative analysis on the test split strategies and propose methodologies to prune the dataset. We adopt an attention-inspired approach for tuning the tensor programs enabling them to embed neural network and hardware-specific features. Our approach could prune the dataset up to 45\% of the baseline without compromising the Pairwise Comparison Accuracy (PCA). Further, the proposed methodology can achieve on-par or improved mean inference time with 25%-40% of the baseline tuning time across different networks and target hardware.
Robustness of Fusion-based Multimodal Classifiers to Cross-Modal Content Dilutions
Nov 04, 2022



As multimodal learning finds applications in a wide variety of high-stakes societal tasks, investigating their robustness becomes important. Existing work has focused on understanding the robustness of vision-and-language models to imperceptible variations on benchmark tasks. In this work, we investigate the robustness of multimodal classifiers to cross-modal dilutions - a plausible variation. We develop a model that, given a multimodal (image + text) input, generates additional dilution text that (a) maintains relevance and topical coherence with the image and existing text, and (b) when added to the original text, leads to misclassification of the multimodal input. Via experiments on Crisis Humanitarianism and Sentiment Detection tasks, we find that the performance of task-specific fusion-based multimodal classifiers drops by 23.3% and 22.5%, respectively, in the presence of dilutions generated by our model. Metric-based comparisons with several baselines and human evaluations indicate that our dilutions show higher relevance and topical coherence, while simultaneously being more effective at demonstrating the brittleness of the multimodal classifiers. Our work aims to highlight and encourage further research on the robustness of deep multimodal models to realistic variations, especially in human-facing societal applications. The code and other resources are available at https://claws-lab.github.io/multimodal-robustness/.
The Impact of COVID-19 Pandemic on LGBTQ Online Communities
May 27, 2022
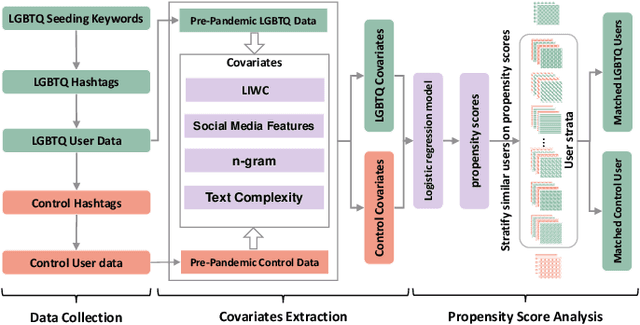
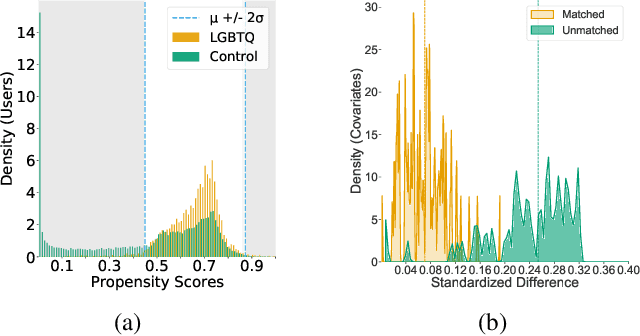
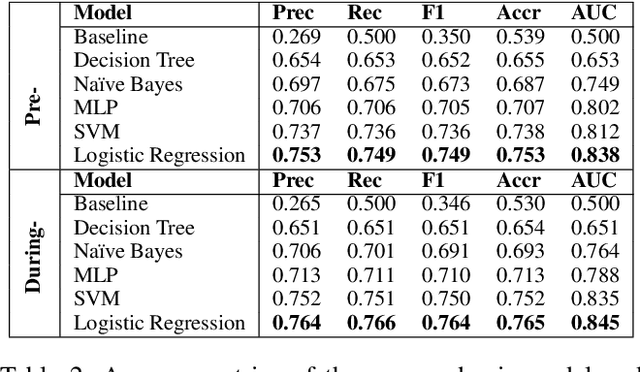
The COVID-19 pandemic has disproportionately impacted the lives of minorities, such as members of the LGBTQ community (lesbian, gay, bisexual, transgender, and queer) due to pre-existing social disadvantages and health disparities. Although extensive research has been carried out on the impact of the COVID-19 pandemic on different aspects of the general population's lives, few studies are focused on the LGBTQ population. In this paper, we identify a group of Twitter users who self-disclose to belong to the LGBTQ community. We develop and evaluate two sets of machine learning classifiers using a pre-pandemic and a during pandemic dataset to identify Twitter posts exhibiting minority stress, which is a unique pressure faced by the members of the LGBTQ population due to their sexual and gender identities. For this task, we collect a set of 20,593,823 posts by 7,241 self-disclosed LGBTQ users and annotate a randomly selected subset of 2800 posts. We demonstrate that our best pre-pandemic and during pandemic models show strong and stable performance for detecting posts that contain minority stress. We investigate the linguistic differences in minority stress posts across pre- and during-pandemic periods. We find that anger words are strongly associated with minority stress during the COVID-19 pandemic. We explore the impact of the pandemic on the emotional states of the LGBTQ population by conducting controlled comparisons with the general population. We adopt propensity score-based matching to perform a causal analysis. The results show that the LBGTQ population have a greater increase in the usage of cognitive words and worsened observable attribute in the usage of positive emotion words than the group of the general population with similar pre-pandemic behavioral attributes.
Overcoming Language Disparity in Online Content Classification with Multimodal Learning
May 19, 2022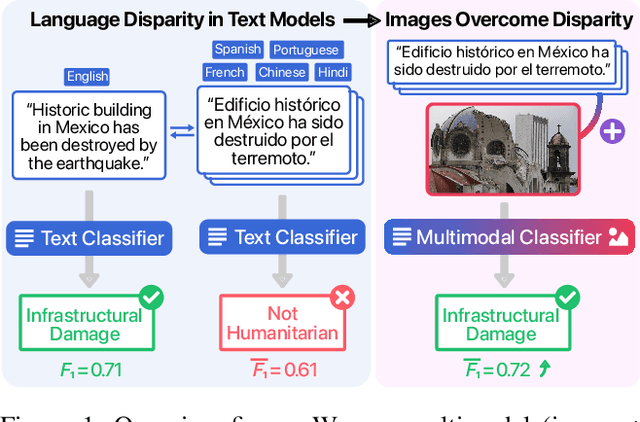
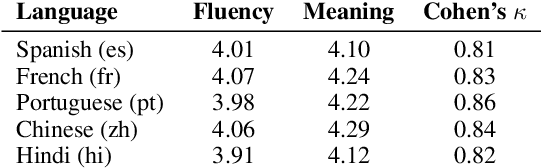

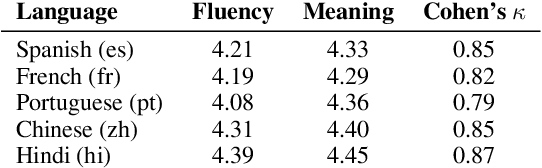
Advances in Natural Language Processing (NLP) have revolutionized the way researchers and practitioners address crucial societal problems. Large language models are now the standard to develop state-of-the-art solutions for text detection and classification tasks. However, the development of advanced computational techniques and resources is disproportionately focused on the English language, sidelining a majority of the languages spoken globally. While existing research has developed better multilingual and monolingual language models to bridge this language disparity between English and non-English languages, we explore the promise of incorporating the information contained in images via multimodal machine learning. Our comparative analyses on three detection tasks focusing on crisis information, fake news, and emotion recognition, as well as five high-resource non-English languages, demonstrate that: (a) detection frameworks based on pre-trained large language models like BERT and multilingual-BERT systematically perform better on the English language compared against non-English languages, and (b) including images via multimodal learning bridges this performance gap. We situate our findings with respect to existing work on the pitfalls of large language models, and discuss their theoretical and practical implications. Resources for this paper are available at https://multimodality-language-disparity.github.io/.
Characterizing, Detecting, and Predicting Online Ban Evasion
Feb 10, 2022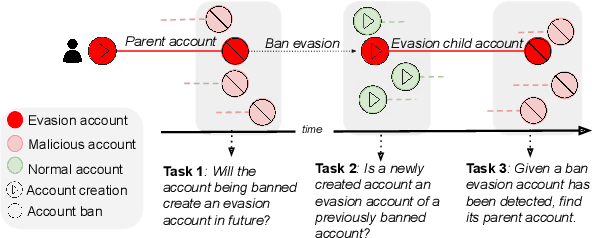



Moderators and automated methods enforce bans on malicious users who engage in disruptive behavior. However, malicious users can easily create a new account to evade such bans. Previous research has focused on other forms of online deception, like the simultaneous operation of multiple accounts by the same entities (sockpuppetry), impersonation of other individuals, and studying the effects of de-platforming individuals and communities. Here we conduct the first data-driven study of ban evasion, i.e., the act of circumventing bans on an online platform, leading to temporally disjoint operation of accounts by the same user. We curate a novel dataset of 8,551 ban evasion pairs (parent, child) identified on Wikipedia and contrast their behavior with benign users and non-evading malicious users. We find that evasion child accounts demonstrate similarities with respect to their banned parent accounts on several behavioral axes - from similarity in usernames and edited pages to similarity in content added to the platform and its psycholinguistic attributes. We reveal key behavioral attributes of accounts that are likely to evade bans. Based on the insights from the analyses, we train logistic regression classifiers to detect and predict ban evasion at three different points in the ban evasion lifecycle. Results demonstrate the effectiveness of our methods in predicting future evaders (AUC = 0.78), early detection of ban evasion (AUC = 0.85), and matching child accounts with parent accounts (MRR = 0.97). Our work can aid moderators by reducing their workload and identifying evasion pairs faster and more efficiently than current manual and heuristic-based approaches. Dataset is available $\href{https://github.com/srijankr/ban_evasion}{\text{here}}$.
BeautifAI -- A Personalised Occasion-oriented Makeup Recommendation System
Sep 13, 2021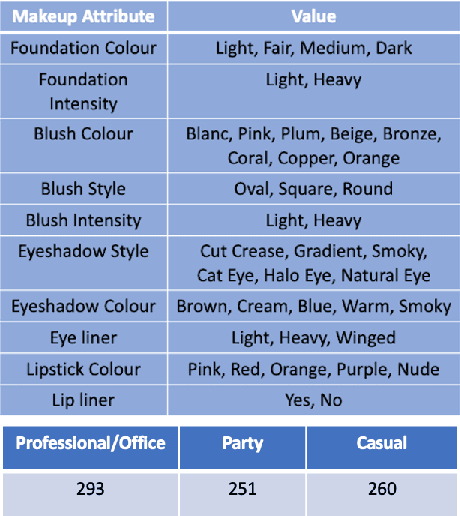
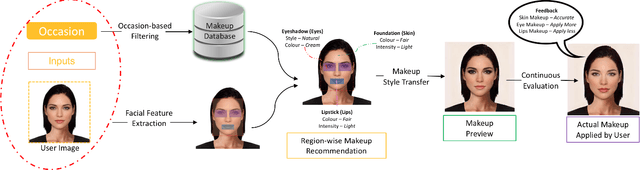
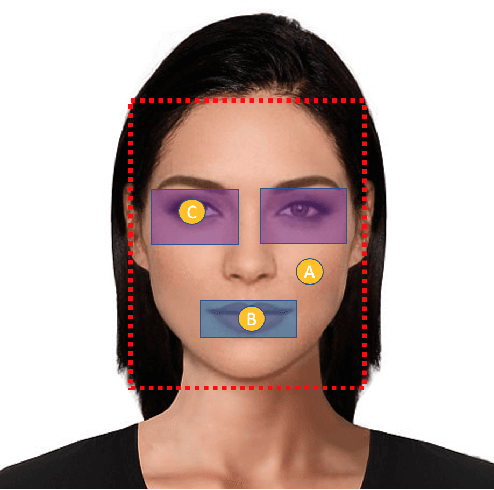

With the global metamorphosis of the beauty industry and the rising demand for beauty products worldwide, the need for an efficacious makeup recommendation system has never been more. Despite the significant advancements made towards personalised makeup recommendation, the current research still falls short of incorporating the context of occasion in makeup recommendation and integrating feedback for users. In this work, we propose BeautifAI, a novel makeup recommendation system, delivering personalised occasion-oriented makeup recommendations to users while providing real-time previews and continuous feedback. The proposed work's novel contributions, including the incorporation of occasion context, region-wise makeup recommendation, real-time makeup previews and continuous makeup feedback, set our system apart from the current work in makeup recommendation. We also demonstrate our proposed system's efficacy in providing personalised makeup recommendation by conducting a user study.