 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSITA: Single Image Test-time Adaptation
Dec 08, 2021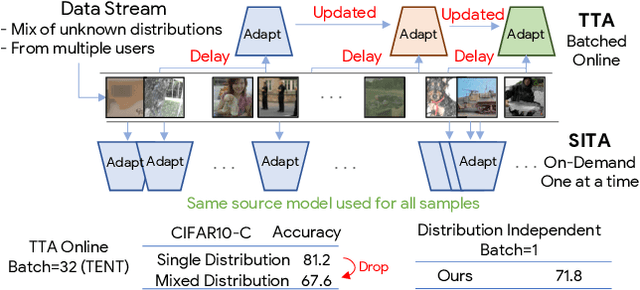


In Test-time Adaptation (TTA), given a model trained on some source data, the goal is to adapt it to make better predictions for test instances from a different distribution. Crucially, TTA assumes no access to the source data or even any additional labeled/unlabeled samples from the target distribution to finetune the source model. In this work, we consider TTA in a more pragmatic setting which we refer to as SITA (Single Image Test-time Adaptation). Here, when making each prediction, the model has access only to the given single test instance, rather than a batch of instances, as has typically been considered in the literature. This is motivated by the realistic scenarios where inference is needed in an on-demand fashion that may not be delayed to "batch-ify" incoming requests or the inference is happening on an edge device (like mobile phone) where there is no scope for batching. The entire adaptation process in SITA should be extremely fast as it happens at inference time. To address this, we propose a novel approach AugBN for the SITA setting that requires only forward propagation. The approach can adapt any off-the-shelf trained model to individual test instances for both classification and segmentation tasks. AugBN estimates normalisation statistics of the unseen test distribution from the given test image using only one forward pass with label-preserving transformations. Since AugBN does not involve any back-propagation, it is significantly faster compared to other recent methods. To the best of our knowledge, this is the first work that addresses this hard adaptation problem using only a single test image. Despite being very simple, our framework is able to achieve significant performance gains compared to directly applying the source model on the target instances, as reflected in our extensive experiments and ablation studies.
Node-Level Differentially Private Graph Neural Networks
Dec 06, 2021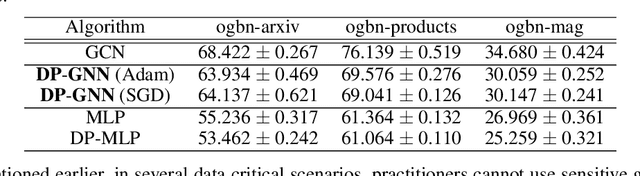
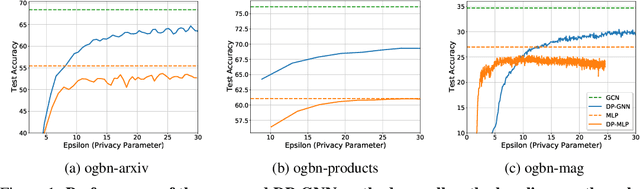
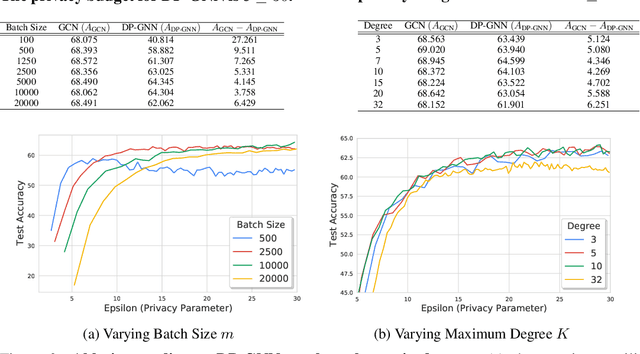
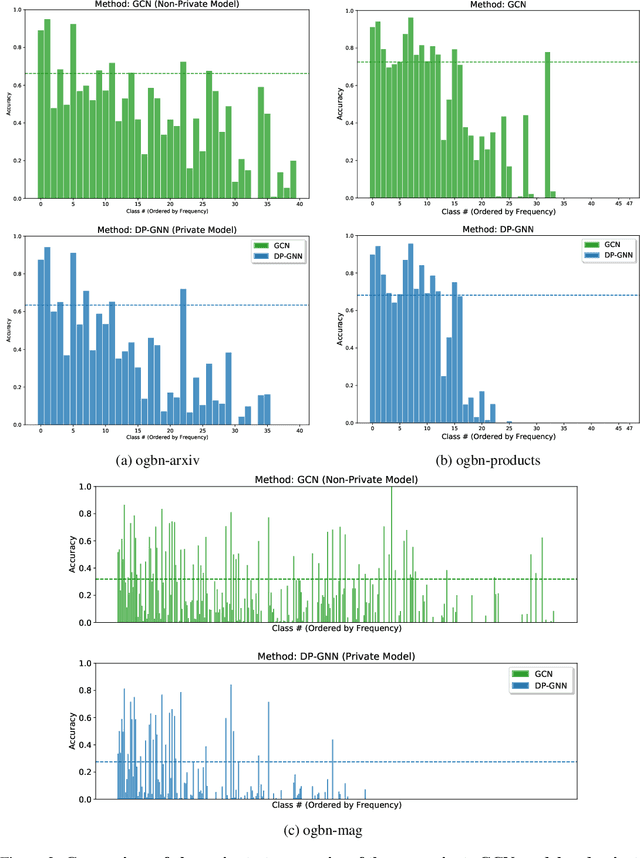
Graph Neural Networks (GNNs) are a popular technique for modelling graph-structured data that compute node-level representations via aggregation of information from the local neighborhood of each node. However, this aggregation implies increased risk of revealing sensitive information, as a node can participate in the inference for multiple nodes. This implies that standard privacy preserving machine learning techniques, such as differentially private stochastic gradient descent (DP-SGD) - which are designed for situations where each data point participates in the inference for one point only - either do not apply, or lead to inaccurate solutions. In this work, we formally define the problem of learning 1-layer GNNs with node-level privacy, and provide an algorithmic solution with a strong differential privacy guarantee. Even though each node can be involved in the inference for multiple nodes, by employing a careful sensitivity analysis anda non-trivial extension of the privacy-by-amplification technique, our method is able to provide accurate solutions with solid privacy parameters. Empirical evaluation on standard benchmarks demonstrates that our method is indeed able to learn accurate privacy preserving GNNs, while still outperforming standard non-private methods that completely ignore graph information.
Unsupervised Adaptation of Semantic Segmentation Models without Source Data
Dec 04, 2021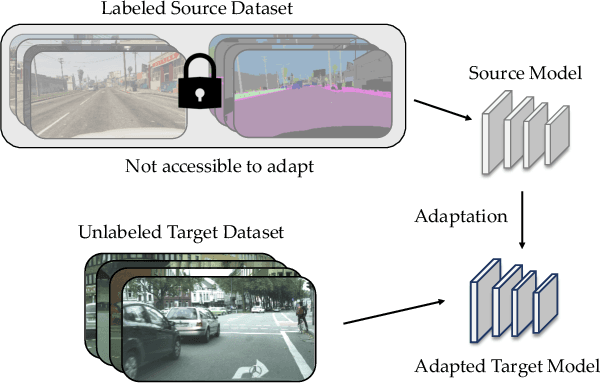
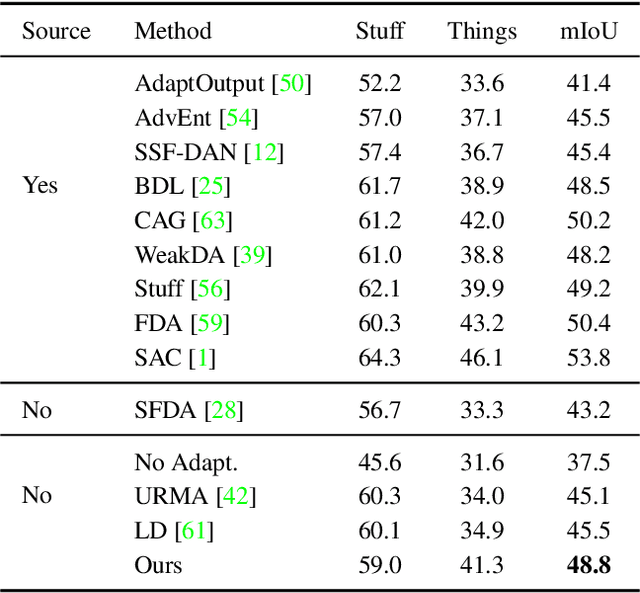
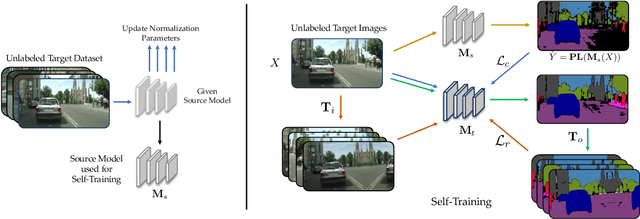
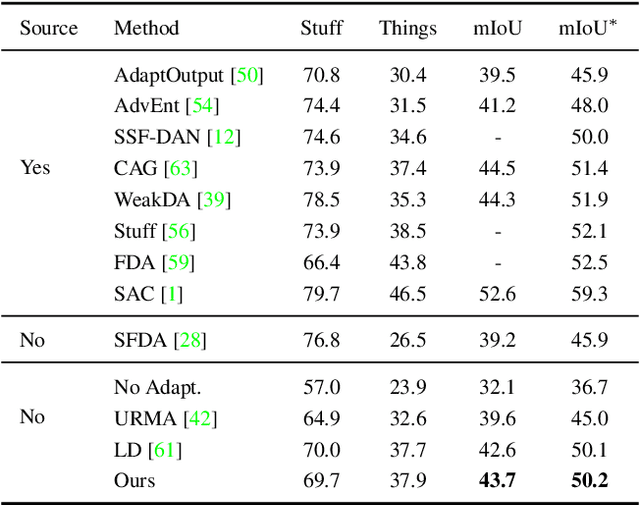
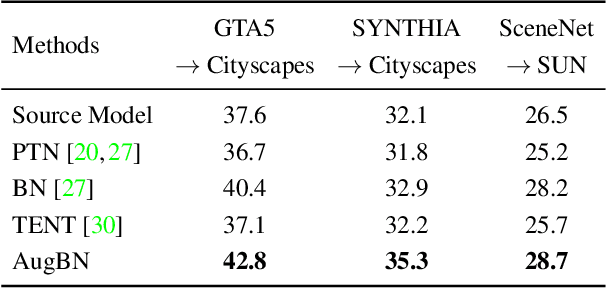
We consider the novel problem of unsupervised domain adaptation of source models, without access to the source data for semantic segmentation. Unsupervised domain adaptation aims to adapt a model learned on the labeled source data, to a new unlabeled target dataset. Existing methods assume that the source data is available along with the target data during adaptation. However, in practical scenarios, we may only have access to the source model and the unlabeled target data, but not the labeled source, due to reasons such as privacy, storage, etc. In this work, we propose a self-training approach to extract the knowledge from the source model. To compensate for the distribution shift from source to target, we first update only the normalization parameters of the network with the unlabeled target data. Then we employ confidence-filtered pseudo labeling and enforce consistencies against certain transformations. Despite being very simple and intuitive, our framework is able to achieve significant performance gains compared to directly applying the source model on the target data as reflected in our extensive experiments and ablation studies. In fact, the performance is just a few points away from the recent state-of-the-art methods which use source data for adaptation. We further demonstrate the generalisability of the proposed approach for fully test-time adaptation setting, where we do not need any target training data and adapt only during test-time.
On Learning to Rank Long Sequences with Contextual Bandits
Jun 07, 2021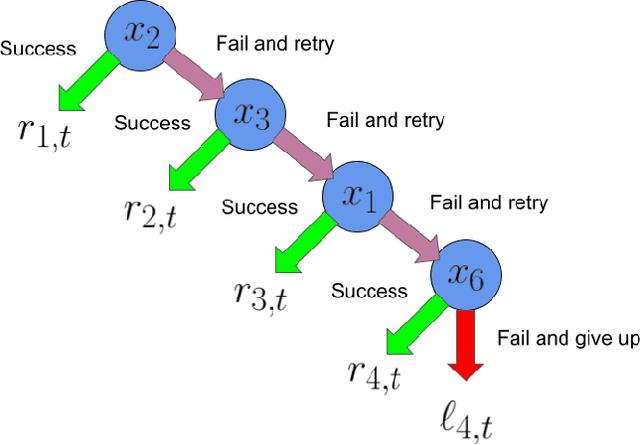
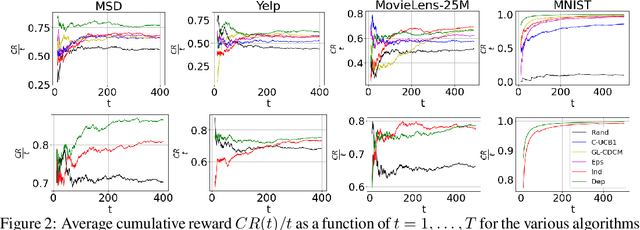
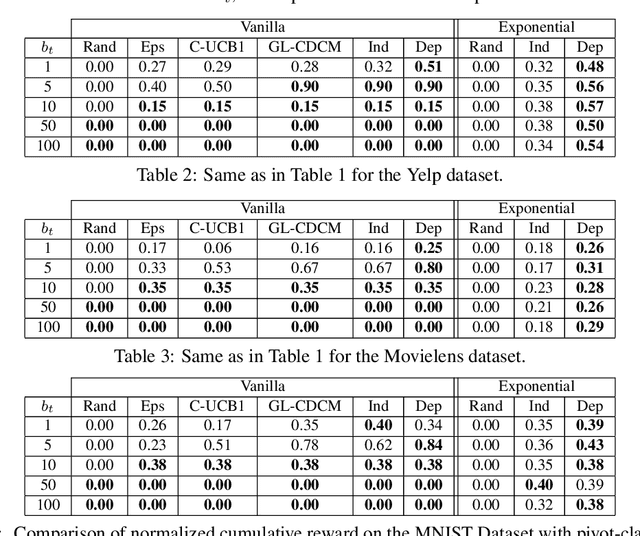
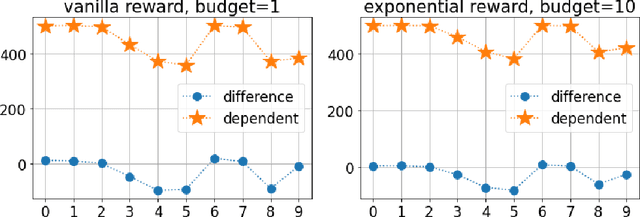
Motivated by problems of learning to rank long item sequences, we introduce a variant of the cascading bandit model that considers flexible length sequences with varying rewards and losses. We formulate two generative models for this problem within the generalized linear setting, and design and analyze upper confidence algorithms for it. Our analysis delivers tight regret bounds which, when specialized to vanilla cascading bandits, results in sharper guarantees than previously available in the literature. We evaluate our algorithms on a number of real-world datasets, and show significantly improved empirical performance as compared to known cascading bandit baselines.
Learn to Intervene: An Adaptive Learning Policy for Restless Bandits in Application to Preventive Healthcare
May 17, 2021


In many public health settings, it is important for patients to adhere to health programs, such as taking medications and periodic health checks. Unfortunately, beneficiaries may gradually disengage from such programs, which is detrimental to their health. A concrete example of gradual disengagement has been observed by an organization that carries out a free automated call-based program for spreading preventive care information among pregnant women. Many women stop picking up calls after being enrolled for a few months. To avoid such disengagements, it is important to provide timely interventions. Such interventions are often expensive and can be provided to only a small fraction of the beneficiaries. We model this scenario as a restless multi-armed bandit (RMAB) problem, where each beneficiary is assumed to transition from one state to another depending on the intervention. Moreover, since the transition probabilities are unknown a priori, we propose a Whittle index based Q-Learning mechanism and show that it converges to the optimal solution. Our method improves over existing learning-based methods for RMABs on multiple benchmarks from literature and also on the maternal healthcare dataset.
The Beauty of Capturing Faces: Rating the Quality of Digital Portraits
Jan 28, 2015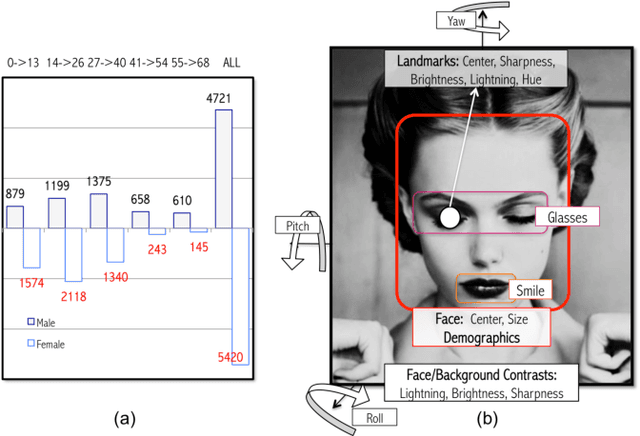

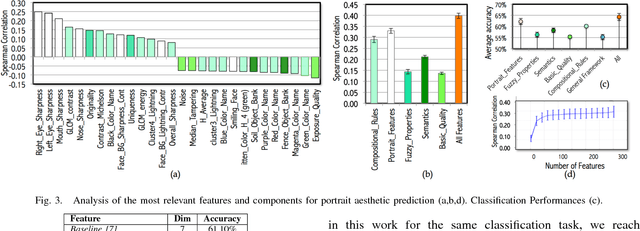
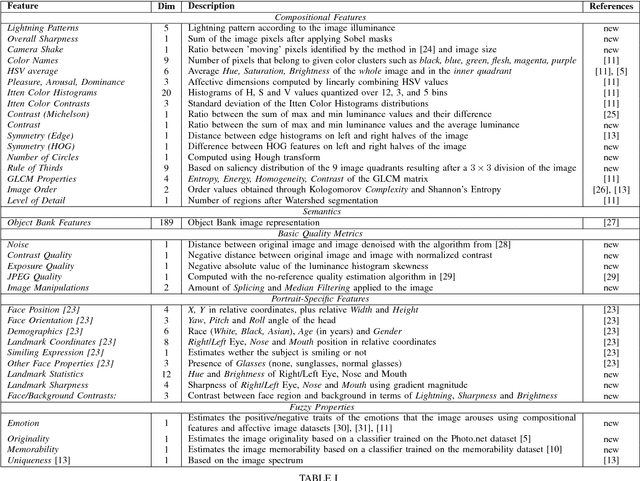
Digital portrait photographs are everywhere, and while the number of face pictures keeps growing, not much work has been done to on automatic portrait beauty assessment. In this paper, we design a specific framework to automatically evaluate the beauty of digital portraits. To this end, we procure a large dataset of face images annotated not only with aesthetic scores but also with information about the traits of the subject portrayed. We design a set of visual features based on portrait photography literature, and extensively analyze their relation with portrait beauty, exposing interesting findings about what makes a portrait beautiful. We find that the beauty of a portrait is linked to its artistic value, and independent from age, race and gender of the subject. We also show that a classifier trained with our features to separate beautiful portraits from non-beautiful portraits outperforms generic aesthetic classifiers.