 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSITA: Single Image Test-time Adaptation
Dec 08, 2021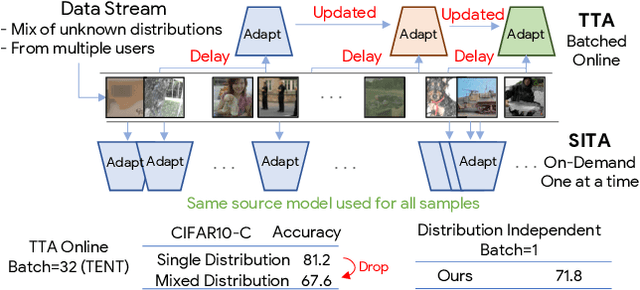


In Test-time Adaptation (TTA), given a model trained on some source data, the goal is to adapt it to make better predictions for test instances from a different distribution. Crucially, TTA assumes no access to the source data or even any additional labeled/unlabeled samples from the target distribution to finetune the source model. In this work, we consider TTA in a more pragmatic setting which we refer to as SITA (Single Image Test-time Adaptation). Here, when making each prediction, the model has access only to the given single test instance, rather than a batch of instances, as has typically been considered in the literature. This is motivated by the realistic scenarios where inference is needed in an on-demand fashion that may not be delayed to "batch-ify" incoming requests or the inference is happening on an edge device (like mobile phone) where there is no scope for batching. The entire adaptation process in SITA should be extremely fast as it happens at inference time. To address this, we propose a novel approach AugBN for the SITA setting that requires only forward propagation. The approach can adapt any off-the-shelf trained model to individual test instances for both classification and segmentation tasks. AugBN estimates normalisation statistics of the unseen test distribution from the given test image using only one forward pass with label-preserving transformations. Since AugBN does not involve any back-propagation, it is significantly faster compared to other recent methods. To the best of our knowledge, this is the first work that addresses this hard adaptation problem using only a single test image. Despite being very simple, our framework is able to achieve significant performance gains compared to directly applying the source model on the target instances, as reflected in our extensive experiments and ablation studies.
Unsupervised Adaptation of Semantic Segmentation Models without Source Data
Dec 04, 2021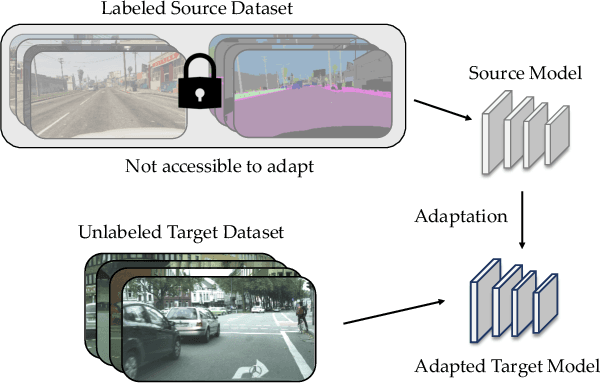
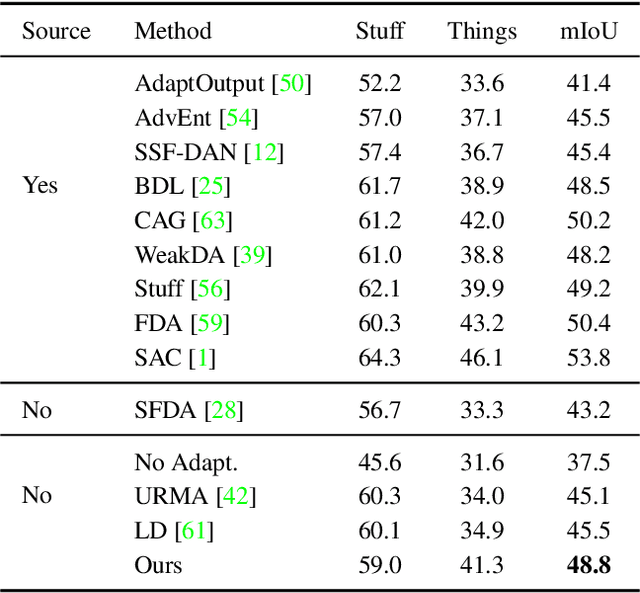
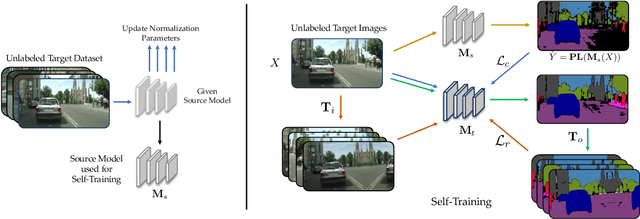
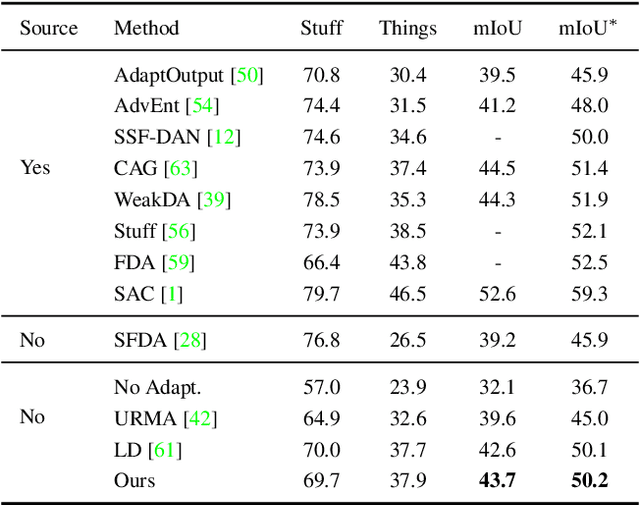
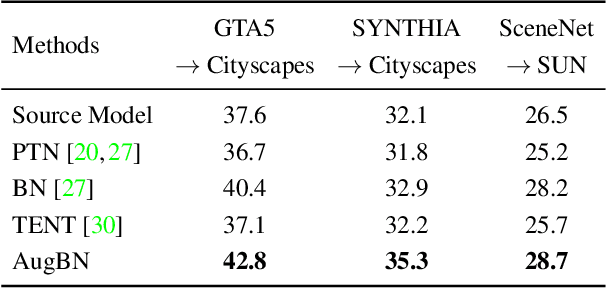
We consider the novel problem of unsupervised domain adaptation of source models, without access to the source data for semantic segmentation. Unsupervised domain adaptation aims to adapt a model learned on the labeled source data, to a new unlabeled target dataset. Existing methods assume that the source data is available along with the target data during adaptation. However, in practical scenarios, we may only have access to the source model and the unlabeled target data, but not the labeled source, due to reasons such as privacy, storage, etc. In this work, we propose a self-training approach to extract the knowledge from the source model. To compensate for the distribution shift from source to target, we first update only the normalization parameters of the network with the unlabeled target data. Then we employ confidence-filtered pseudo labeling and enforce consistencies against certain transformations. Despite being very simple and intuitive, our framework is able to achieve significant performance gains compared to directly applying the source model on the target data as reflected in our extensive experiments and ablation studies. In fact, the performance is just a few points away from the recent state-of-the-art methods which use source data for adaptation. We further demonstrate the generalisability of the proposed approach for fully test-time adaptation setting, where we do not need any target training data and adapt only during test-time.
Multi-Stage Fusion for One-Click Segmentation
Oct 20, 2020
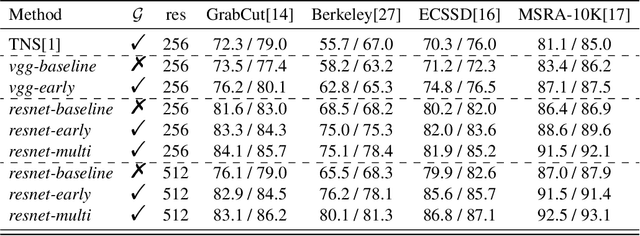
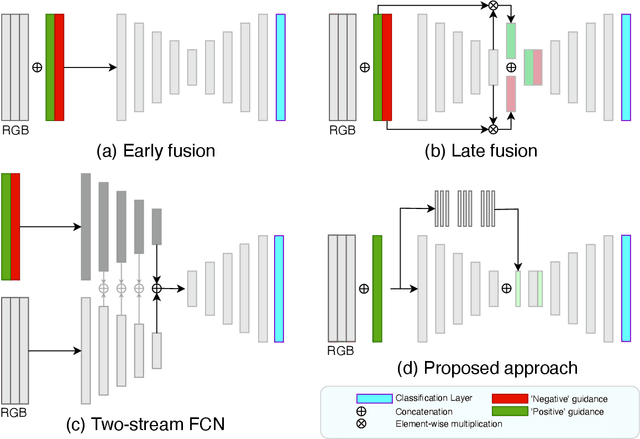
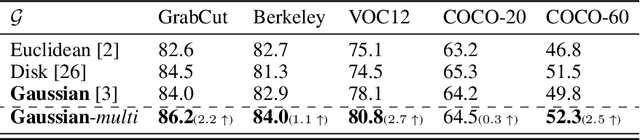
Segmenting objects of interest in an image is an essential building block of applications such as photo-editing and image analysis. Under interactive settings, one should achieve good segmentations while minimizing user input. Current deep learning-based interactive segmentation approaches use early fusion and incorporate user cues at the image input layer. Since segmentation CNNs have many layers, early fusion may weaken the influence of user interactions on the final prediction results. As such, we propose a new multi-stage guidance framework for interactive segmentation. By incorporating user cues at different stages of the network, we allow user interactions to impact the final segmentation output in a more direct way. Our proposed framework has a negligible increase in parameter count compared to early-fusion frameworks. We perform extensive experimentation on the standard interactive instance segmentation and one-click segmentation benchmarks and report state-of-the-art performance.