 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Agile Maneuvers in Highly Constrained Spaces: Learning from Hallucination
Jul 30, 2020
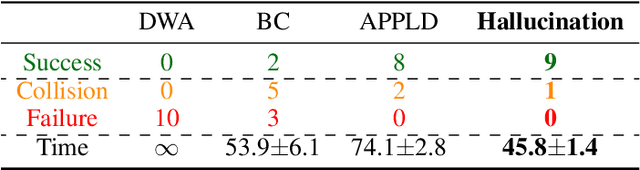
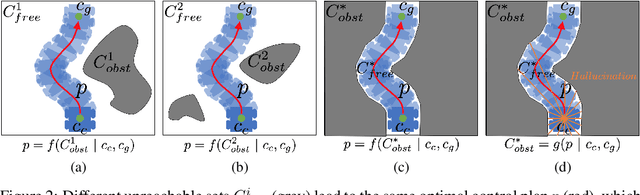
While classical approaches to autonomous robot navigation currently enable operation in certain environments, they break down in tightly constrained spaces, e.g., where the robot needs to engage in agile maneuvers to squeeze between obstacles. Recent machine learning techniques have the potential to address this shortcoming, but existing approaches require vast amounts of navigation experience for training, during which the robot must operate in close proximity to obstacles and risk collision. In this paper, we propose to side-step this requirement by introducing a new machine learning paradigm for autonomous navigation called learning from hallucination (LfH), which can use training data collected in completely safe environments to compute navigation controllers that result in fast, smooth, and safe navigation in highly constrained environments. Our experimental results show that the proposed LfH system outperforms three autonomous navigation baselines on a real robot, including those based on both classical and machine learning techniques (anonymized video: https://tinyurl.com/corl20lfh).
APPLD: Adaptive Planner Parameter Learning from Demonstration
Mar 31, 2020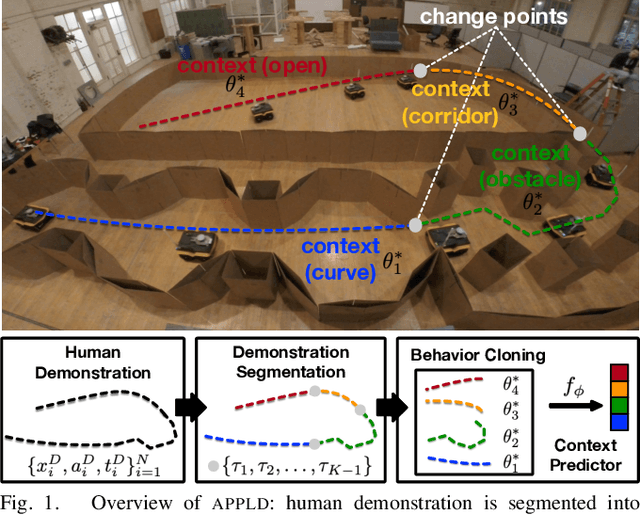
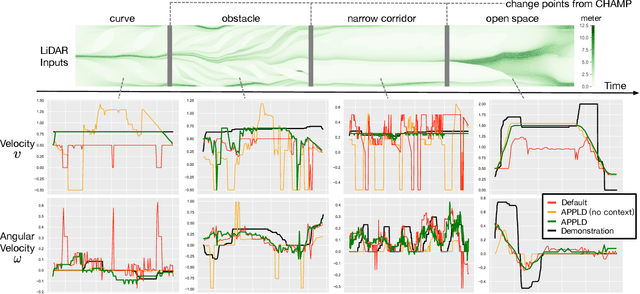
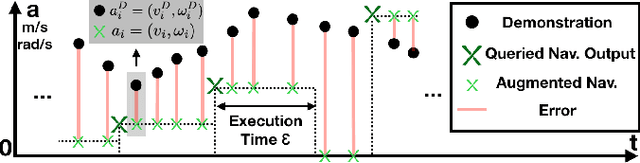
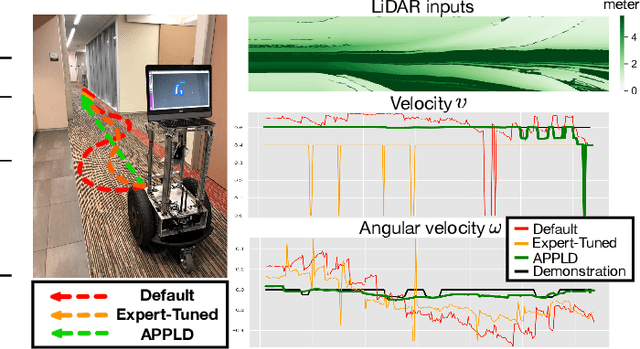
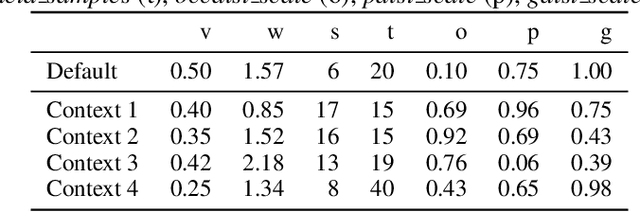
Existing autonomous robot navigation systems allow robots to move from one point to another in a collision-free manner. However, when facing new environments, these systems generally require re-tuning by expert roboticists with a good understanding of the inner workings of the navigation system. In contrast, even users who are unversed in the details of robot navigation algorithms can generate desirable navigation behavior in new environments via teleoperation. In this paper, we introduce APPLD, Adaptive Planner Parameter Learning from Demonstration, that allows existing navigation systems to be successfully applied to new complex environments, given only a human teleoperated demonstration of desirable navigation. APPLD is verified on two robots running different navigation systems in different environments. Experimental results show that APPLD can outperform navigation systems with the default and expert-tuned parameters, and even the human demonstrator themselves.
A Narration-based Reward Shaping Approach using Grounded Natural Language Commands
Oct 31, 2019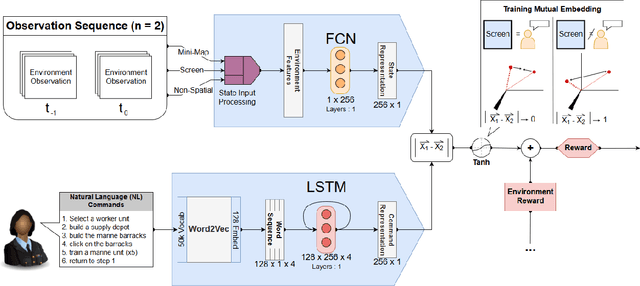
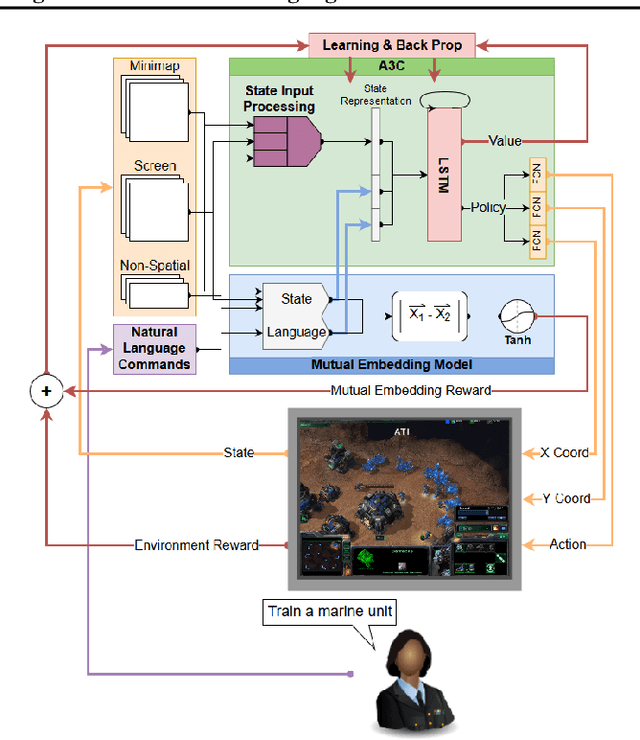
While deep reinforcement learning techniques have led to agents that are successfully able to learn to perform a number of tasks that had been previously unlearnable, these techniques are still susceptible to the longstanding problem of reward sparsity. This is especially true for tasks such as training an agent to play StarCraft II, a real-time strategy game where reward is only given at the end of a game which is usually very long. While this problem can be addressed through reward shaping, such approaches typically require a human expert with specialized knowledge. Inspired by the vision of enabling reward shaping through the more-accessible paradigm of natural-language narration, we develop a technique that can provide the benefits of reward shaping using natural language commands. Our narration-guided RL agent projects sequences of natural-language commands into the same high-dimensional representation space as corresponding goal states. We show that we can get improved performance with our method compared to traditional reward-shaping approaches. Additionally, we demonstrate the ability of our method to generalize to unseen natural-language commands.
RIDM: Reinforced Inverse Dynamics Modeling for Learning from a Single Observed Demonstration
Jul 01, 2019
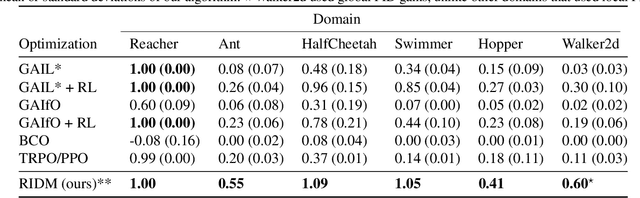

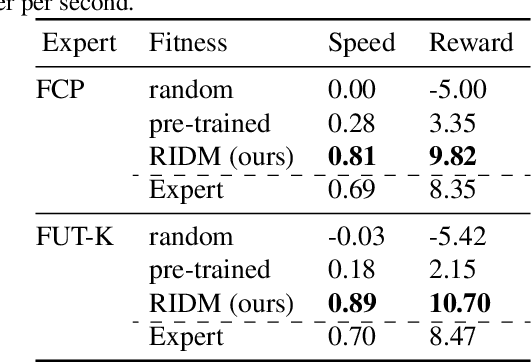
Imitation learning has long been an approach to alleviate the tractability issues that arise in reinforcement learning. However, most literature makes several assumptions such as access to the expert's actions, availability of many expert demonstrations, and injection of task-specific domain knowledge into the learning process. We propose reinforced inverse dynamics modeling (RIDM), a method of combining reinforcement learning and imitation from observation (IfO) to perform imitation using a single expert demonstration, with no access to the expert's actions, and with little task-specific domain knowledge. Given only a single set of the expert's raw states, such as joint angles in a robot control task, at each time-step, we learn an inverse dynamics model to produce the necessary low-level actions, such as torques, to transition from one state to the next such that the reward from the environment is maximized. We demonstrate that RIDM outperforms other techniques when we apply the same constraints on the other methods on six domains of the MuJoCo simulator and for two different robot soccer tasks for two experts from the RoboCup 3D simulation league on the SimSpark simulator.
Sample-efficient Adversarial Imitation Learning from Observation
Jun 18, 2019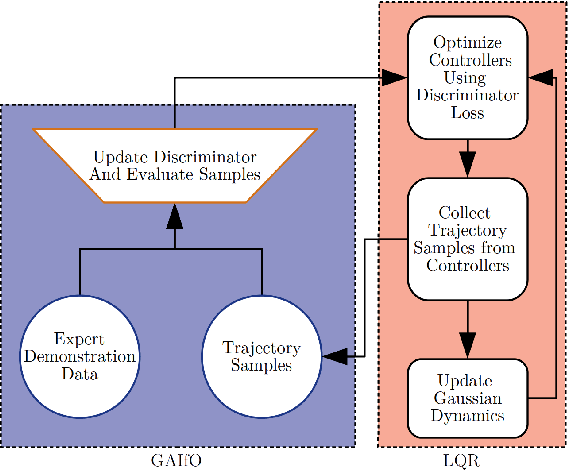

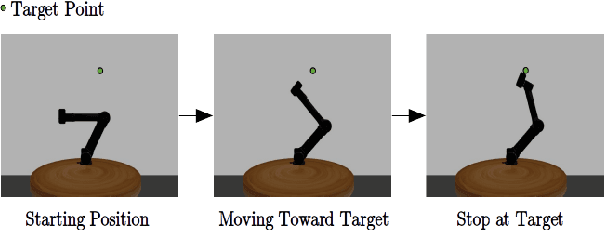
Imitation from observation is the framework of learning tasks by observing demonstrated state-only trajectories. Recently, adversarial approaches have achieved significant performance improvements over other methods for imitating complex behaviors. However, these adversarial imitation algorithms often require many demonstration examples and learning iterations to produce a policy that is successful at imitating a demonstrator's behavior. This high sample complexity often prohibits these algorithms from being deployed on physical robots. In this paper, we propose an algorithm that addresses the sample inefficiency problem by utilizing ideas from trajectory centric reinforcement learning algorithms. We test our algorithm and conduct experiments using an imitation task on a physical robot arm and its simulated version in Gazebo and will show the improvement in learning rate and efficiency.
Recent Advances in Imitation Learning from Observation
May 30, 2019
Imitation learning is the process by which one agent tries to learn how to perform a certain task using information generated by another, often more-expert agent performing that same task. Conventionally, the imitator has access to both state and action information generated by an expert performing the task (e.g., the expert may provide a kinesthetic demonstration of object placement using a robotic arm). However, requiring the action information prevents imitation learning from a large number of existing valuable learning resources such as online videos of humans performing tasks. To overcome this issue, the specific problem of imitation from observation (IfO) has recently garnered a great deal of attention, in which the imitator only has access to the state information (e.g., video frames) generated by the expert. In this paper, we provide a literature review of methods developed for IfO, and then point out some open research problems and potential future work.
Imitation Learning from Video by Leveraging Proprioception
May 22, 2019
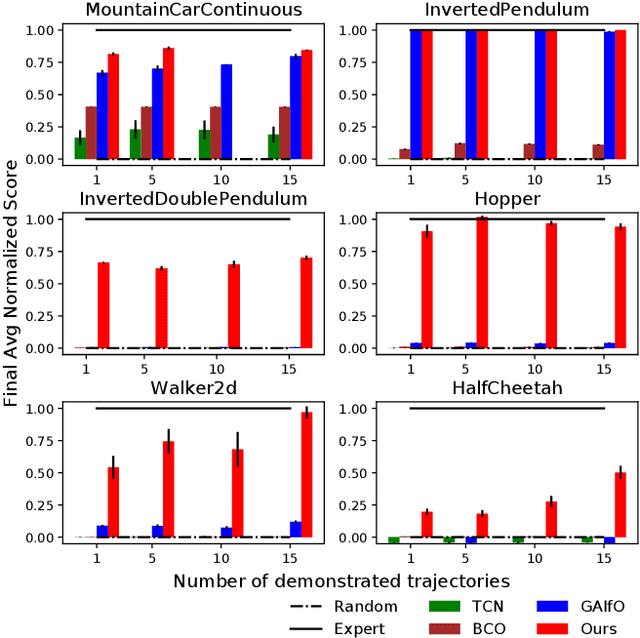
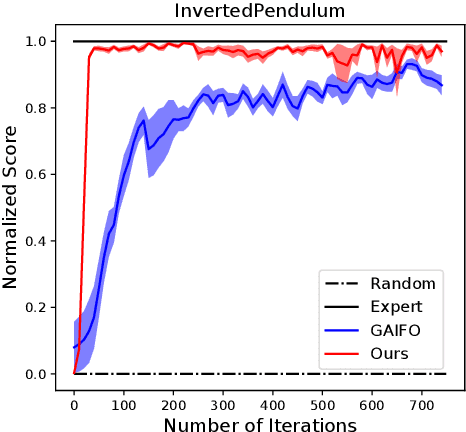
Classically, imitation learning algorithms have been developed for idealized situations, e.g., the demonstrations are often required to be collected in the exact same environment and usually include the demonstrator's actions. Recently, however, the research community has begun to address some of these shortcomings by offering algorithmic solutions that enable imitation learning from observation (IfO), e.g., learning to perform a task from visual demonstrations that may be in a different environment and do not include actions. Motivated by the fact that agents often also have access to their own internal states (i.e., proprioception), we propose and study an IfO algorithm that leverages this information in the policy learning process. The proposed architecture learns policies over proprioceptive state representations and compares the resulting trajectories visually to the demonstration data. We experimentally test the proposed technique on several MuJoCo domains and show that it outperforms other imitation from observation algorithms by a large margin.
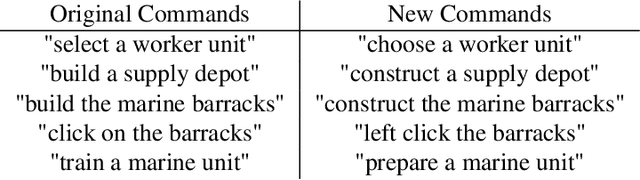
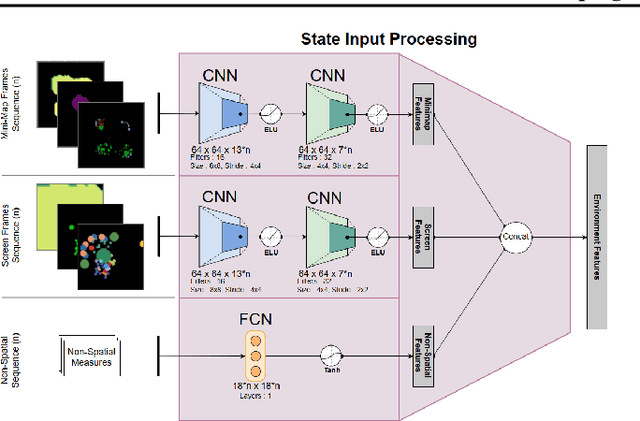
Grounding Natural Language Commands to StarCraft II Game States for Narration-Guided Reinforcement Learning
Apr 24, 2019While deep reinforcement learning techniques have led to agents that are successfully able to learn to perform a number of tasks that had been previously unlearnable, these techniques are still susceptible to the longstanding problem of {\em reward sparsity}. This is especially true for tasks such as training an agent to play StarCraft II, a real-time strategy game where reward is only given at the end of a game which is usually very long. While this problem can be addressed through reward shaping, such approaches typically require a human expert with specialized knowledge. Inspired by the vision of enabling reward shaping through the more-accessible paradigm of natural-language narration, we investigate to what extent we can contextualize these narrations by grounding them to the goal-specific states. We present a mutual-embedding model using a multi-input deep-neural network that projects a sequence of natural language commands into the same high-dimensional representation space as corresponding goal states. We show that using this model we can learn an embedding space with separable and distinct clusters that accurately maps natural-language commands to corresponding game states . We also discuss how this model can allow for the use of narrations as a robust form of reward shaping to improve RL performance and efficiency.
Deterministic Implementations for Reproducibility in Deep Reinforcement Learning
Sep 19, 2018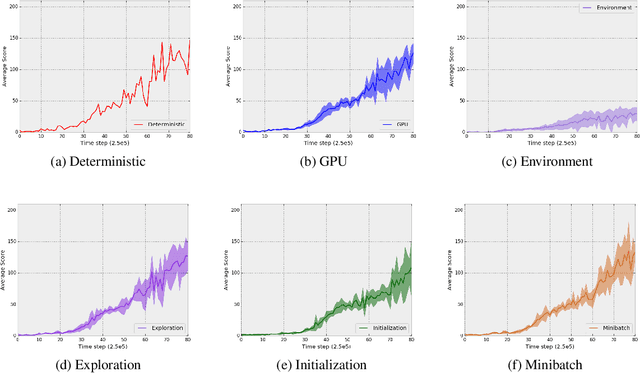
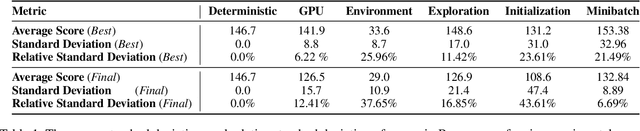
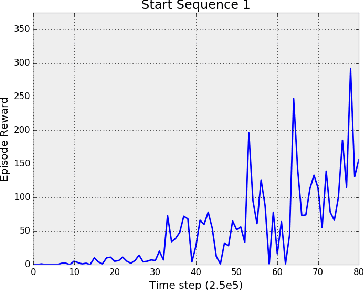
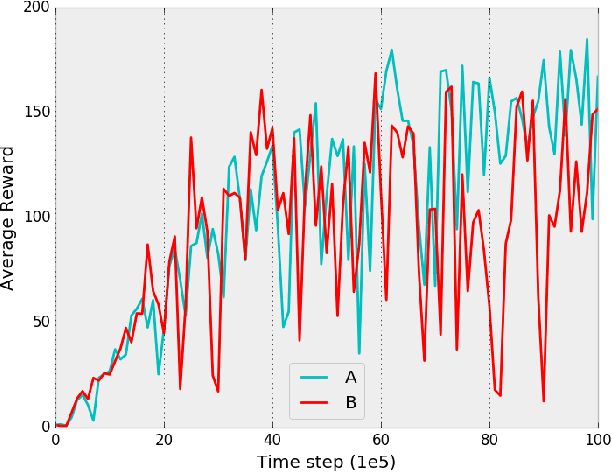
While deep reinforcement learning (DRL) has led to numerous successes in recent years, reproducing these successes can be extremely challenging. One reproducibility challenge particularly relevant to DRL is nondeterminism in the training process, which can substantially affect the results. Motivated by this challenge, we study the positive impacts of deterministic implementations in eliminating nondeterminism in training. To do so, we consider the particular case of the deep Q-learning algorithm, for which we produce a deterministic implementation by identifying and controlling all sources of nondeterminism in the training process. One by one, we then allow individual sources of nondeterminism to affect our otherwise deterministic implementation, and measure the impact of each source on the variance in performance. We find that individual sources of nondeterminism can substantially impact the performance of agent, illustrating the benefits of deterministic implementations. In addition, we also discuss the important role of deterministic implementations in achieving exact replicability of results.
Generative Adversarial Imitation from Observation
Jul 17, 2018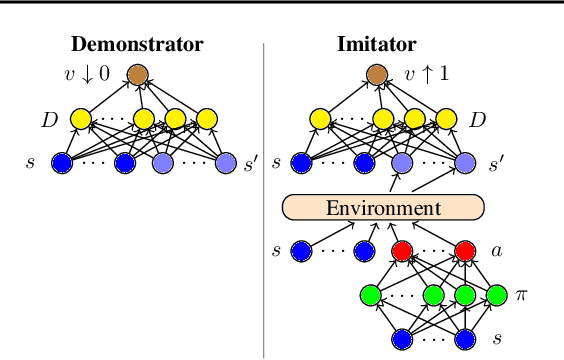
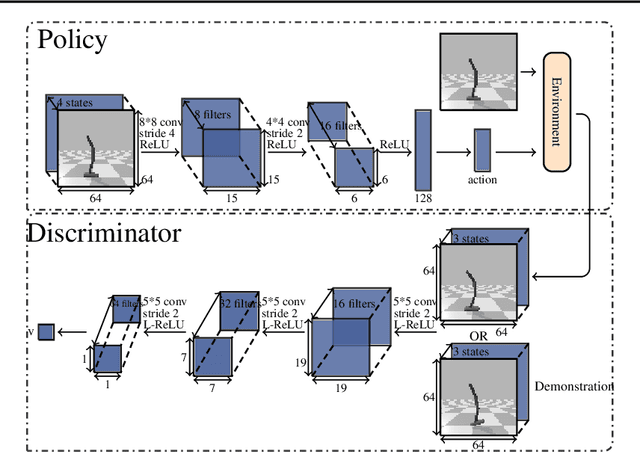
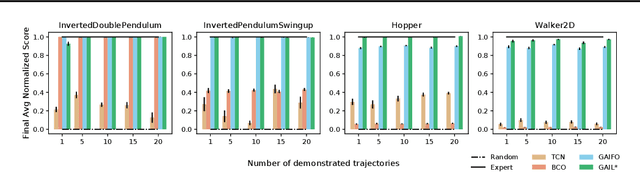
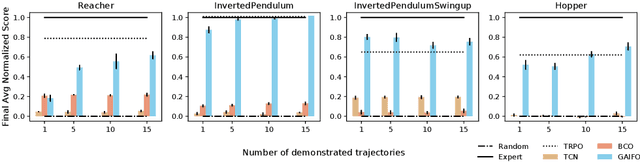
Imitation from observation (IfO) is the problem of learning directly from state-only demonstrations without having access to the demonstrator's actions. The lack of action information both distinguishes IfO from most of the literature in imitation learning, and also sets it apart as a method that may enable agents to learn from large set of previously inapplicable resources such as internet videos. In this paper, we propose both a general framework for IfO approaches and propose a new IfO approach based on generative adversarial networks called generative adversarial imitation from observation (GAIfO). We demonstrate that this approach performs comparably to classical imitation learning approaches (which have access to the demonstrator's actions) and significantly outperforms existing imitation from observation methods in high-dimensional simulation environments.