 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Image De-Identification Benchmark Challenge
Jul 31, 2025



The de-identification (deID) of protected health information (PHI) and personally identifiable information (PII) is a fundamental requirement for sharing medical images, particularly through public repositories, to ensure compliance with patient privacy laws. In addition, preservation of non-PHI metadata to inform and enable downstream development of imaging artificial intelligence (AI) is an important consideration in biomedical research. The goal of MIDI-B was to provide a standardized platform for benchmarking of DICOM image deID tools based on a set of rules conformant to the HIPAA Safe Harbor regulation, the DICOM Attribute Confidentiality Profiles, and best practices in preservation of research-critical metadata, as defined by The Cancer Imaging Archive (TCIA). The challenge employed a large, diverse, multi-center, and multi-modality set of real de-identified radiology images with synthetic PHI/PII inserted. The MIDI-B Challenge consisted of three phases: training, validation, and test. Eighty individuals registered for the challenge. In the training phase, we encouraged participants to tune their algorithms using their in-house or public data. The validation and test phases utilized the DICOM images containing synthetic identifiers (of 216 and 322 subjects, respectively). Ten teams successfully completed the test phase of the challenge. To measure success of a rule-based approach to image deID, scores were computed as the percentage of correct actions from the total number of required actions. The scores ranged from 97.91% to 99.93%. Participants employed a variety of open-source and proprietary tools with customized configurations, large language models, and optical character recognition (OCR). In this paper we provide a comprehensive report on the MIDI-B Challenge's design, implementation, results, and lessons learned.
Field Study in Deploying Restless Multi-Armed Bandits: Assisting Non-Profits in Improving Maternal and Child Health
Sep 16, 2021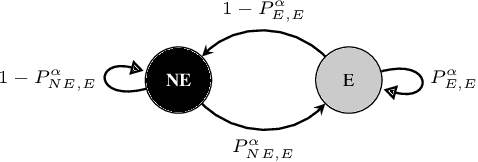
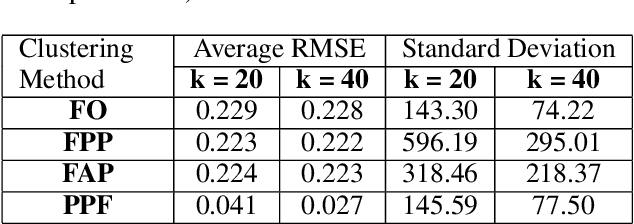
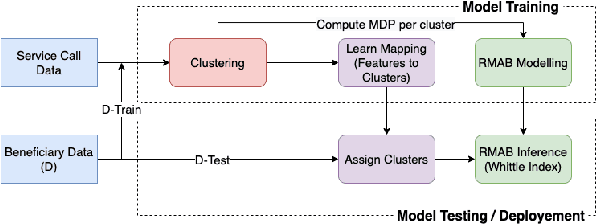
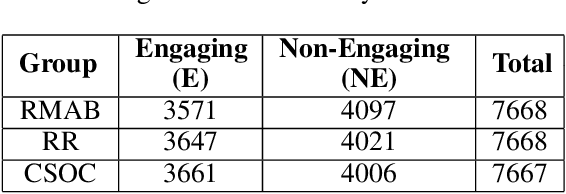
The widespread availability of cell phones has enabled non-profits to deliver critical health information to their beneficiaries in a timely manner. This paper describes our work to assist non-profits that employ automated messaging programs to deliver timely preventive care information to beneficiaries (new and expecting mothers) during pregnancy and after delivery. Unfortunately, a key challenge in such information delivery programs is that a significant fraction of beneficiaries drop out of the program. Yet, non-profits often have limited health-worker resources (time) to place crucial service calls for live interaction with beneficiaries to prevent such engagement drops. To assist non-profits in optimizing this limited resource, we developed a Restless Multi-Armed Bandits (RMABs) system. One key technical contribution in this system is a novel clustering method of offline historical data to infer unknown RMAB parameters. Our second major contribution is evaluation of our RMAB system in collaboration with an NGO, via a real-world service quality improvement study. The study compared strategies for optimizing service calls to 23003 participants over a period of 7 weeks to reduce engagement drops. We show that the RMAB group provides statistically significant improvement over other comparison groups, reducing ~ 30% engagement drops. To the best of our knowledge, this is the first study demonstrating the utility of RMABs in real world public health settings. We are transitioning our RMAB system to the NGO for real-world use.
Fine-Grained Emotion Prediction by Modeling Emotion Definitions
Jul 26, 2021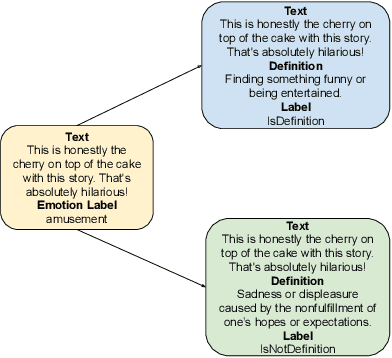
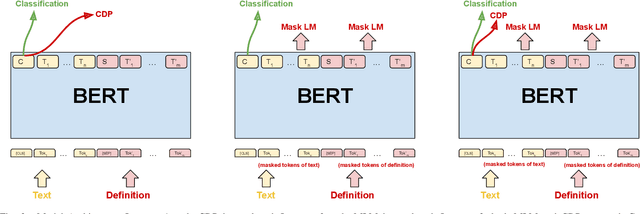
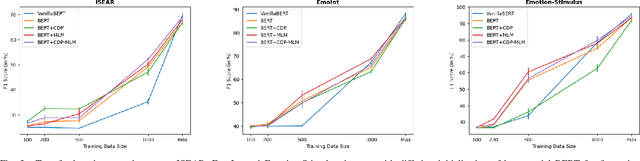

In this paper, we propose a new framework for fine-grained emotion prediction in the text through emotion definition modeling. Our approach involves a multi-task learning framework that models definitions of emotions as an auxiliary task while being trained on the primary task of emotion prediction. We model definitions using masked language modeling and class definition prediction tasks. Our models outperform existing state-of-the-art for fine-grained emotion dataset GoEmotions. We further show that this trained model can be used for transfer learning on other benchmark datasets in emotion prediction with varying emotion label sets, domains, and sizes. The proposed models outperform the baselines on transfer learning experiments demonstrating the generalization capability of the models.
Pre-trained Language Models as Prior Knowledge for Playing Text-based Games
Jul 18, 2021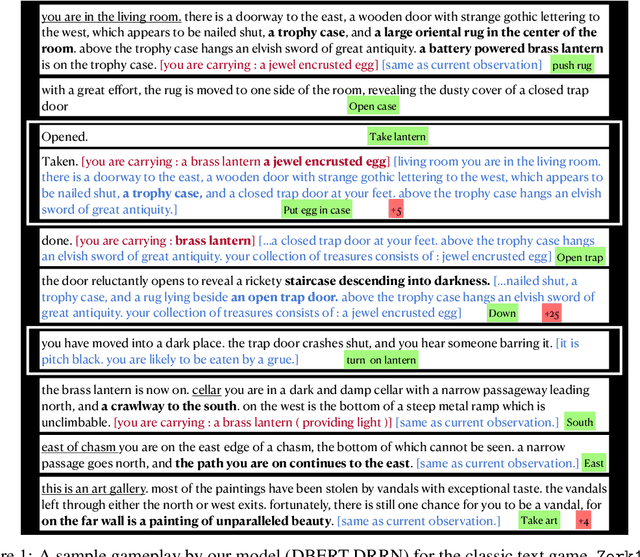
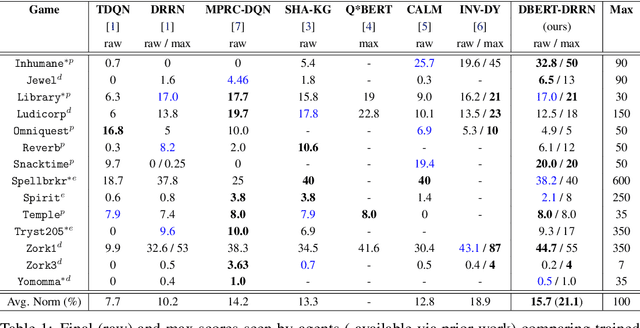
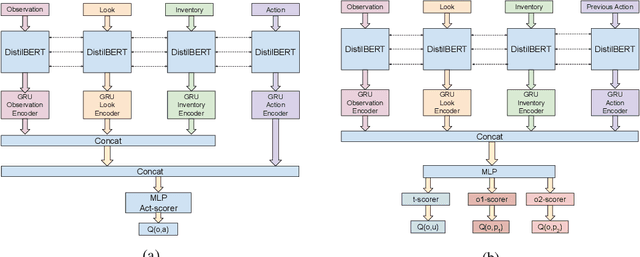
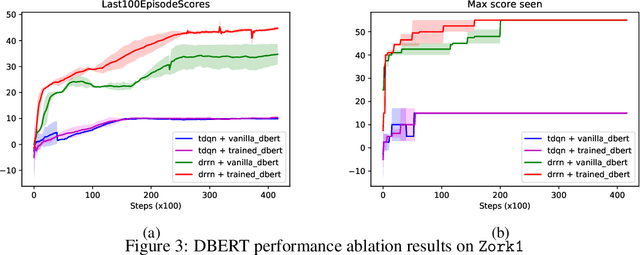
Recently, text world games have been proposed to enable artificial agents to understand and reason about real-world scenarios. These text-based games are challenging for artificial agents, as it requires understanding and interaction using natural language in a partially observable environment. In this paper, we improve the semantic understanding of the agent by proposing a simple RL with LM framework where we use transformer-based language models with Deep RL models. We perform a detailed study of our framework to demonstrate how our model outperforms all existing agents on the popular game, Zork1, to achieve a score of 44.7, which is 1.6 higher than the state-of-the-art model. Our proposed approach also performs comparably to the state-of-the-art models on the other set of text games.