 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuxiliary Learning as an Asymmetric Bargaining Game
Jan 31, 2023



Auxiliary learning is an effective method for enhancing the generalization capabilities of trained models, particularly when dealing with small datasets. However, this approach may present several difficulties: (i) optimizing multiple objectives can be more challenging, and (ii) how to balance the auxiliary tasks to best assist the main task is unclear. In this work, we propose a novel approach, named AuxiNash, for balancing tasks in auxiliary learning by formalizing the problem as generalized bargaining game with asymmetric task bargaining power. Furthermore, we describe an efficient procedure for learning the bargaining power of tasks based on their contribution to the performance of the main task and derive theoretical guarantees for its convergence. Finally, we evaluate AuxiNash on multiple multi-task benchmarks and find that it consistently outperforms competing methods.
SoftTreeMax: Exponential Variance Reduction in Policy Gradient via Tree Search
Jan 30, 2023



Despite the popularity of policy gradient methods, they are known to suffer from large variance and high sample complexity. To mitigate this, we introduce SoftTreeMax -- a generalization of softmax that takes planning into account. In SoftTreeMax, we extend the traditional logits with the multi-step discounted cumulative reward, topped with the logits of future states. We consider two variants of SoftTreeMax, one for cumulative reward and one for exponentiated reward. For both, we analyze the gradient variance and reveal for the first time the role of a tree expansion policy in mitigating this variance. We prove that the resulting variance decays exponentially with the planning horizon as a function of the expansion policy. Specifically, we show that the closer the resulting state transitions are to uniform, the faster the decay. In a practical implementation, we utilize a parallelized GPU-based simulator for fast and efficient tree search. Our differentiable tree-based policy leverages all gradients at the tree leaves in each environment step instead of the traditional single-sample-based gradient. We then show in simulation how the variance of the gradient is reduced by three orders of magnitude, leading to better sample complexity compared to the standard policy gradient. On Atari, SoftTreeMax demonstrates up to 5x better performance in a faster run time compared to distributed PPO. Lastly, we demonstrate that high reward correlates with lower variance.
Equivariant Architectures for Learning in Deep Weight Spaces
Jan 30, 2023



Designing machine learning architectures for processing neural networks in their raw weight matrix form is a newly introduced research direction. Unfortunately, the unique symmetry structure of deep weight spaces makes this design very challenging. If successful, such architectures would be capable of performing a wide range of intriguing tasks, from adapting a pre-trained network to a new domain to editing objects represented as functions (INRs or NeRFs). As a first step towards this goal, we present here a novel network architecture for learning in deep weight spaces. It takes as input a concatenation of weights and biases of a pre-trained MLP and processes it using a composition of layers that are equivariant to the natural permutation symmetry of the MLP's weights: Changing the order of neurons in intermediate layers of the MLP does not affect the function it represents. We provide a full characterization of all affine equivariant and invariant layers for these symmetries and show how these layers can be implemented using three basic operations: pooling, broadcasting, and fully connected layers applied to the input in an appropriate manner. We demonstrate the effectiveness of our architecture and its advantages over natural baselines in a variety of learning tasks.
Train Hard, Fight Easy: Robust Meta Reinforcement Learning
Jan 26, 2023



A major challenge of reinforcement learning (RL) in real-world applications is the variation between environments, tasks or clients. Meta-RL (MRL) addresses this issue by learning a meta-policy that adapts to new tasks. Standard MRL methods optimize the average return over tasks, but often suffer from poor results in tasks of high risk or difficulty. This limits system reliability whenever test tasks are not known in advance. In this work, we propose a robust MRL objective with a controlled robustness level. Optimization of analogous robust objectives in RL often leads to both biased gradients and data inefficiency. We prove that the former disappears in MRL, and address the latter via the novel Robust Meta RL algorithm (RoML). RoML is a meta-algorithm that generates a robust version of any given MRL algorithm, by identifying and over-sampling harder tasks throughout training. We demonstrate that RoML learns substantially different meta-policies and achieves robust returns on several navigation and continuous control benchmarks.
Text2Model: Model Induction for Zero-shot Generalization Using Task Descriptions
Oct 27, 2022



We study the problem of generating a training-free task-dependent visual classifier from text descriptions without visual samples. This \textit{Text-to-Model} (T2M) problem is closely related to zero-shot learning, but unlike previous work, a T2M model infers a model tailored to a task, taking into account all classes in the task. We analyze the symmetries of T2M, and characterize the equivariance and invariance properties of corresponding models. In light of these properties, we design an architecture based on hypernetworks that given a set of new class descriptions predicts the weights for an object recognition model which classifies images from those zero-shot classes. We demonstrate the benefits of our approach compared to zero-shot learning from text descriptions in image and point-cloud classification using various types of text descriptions: From single words to rich text descriptions.
SoftTreeMax: Policy Gradient with Tree Search
Sep 28, 2022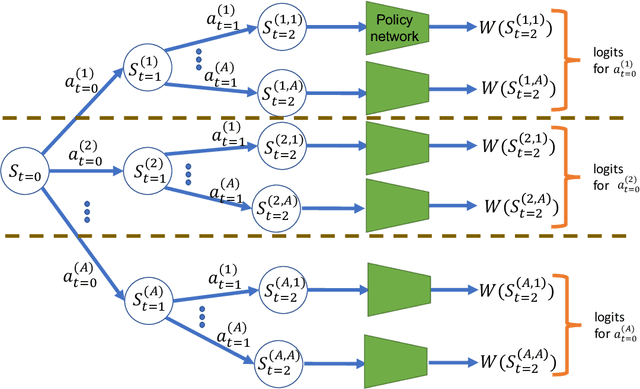
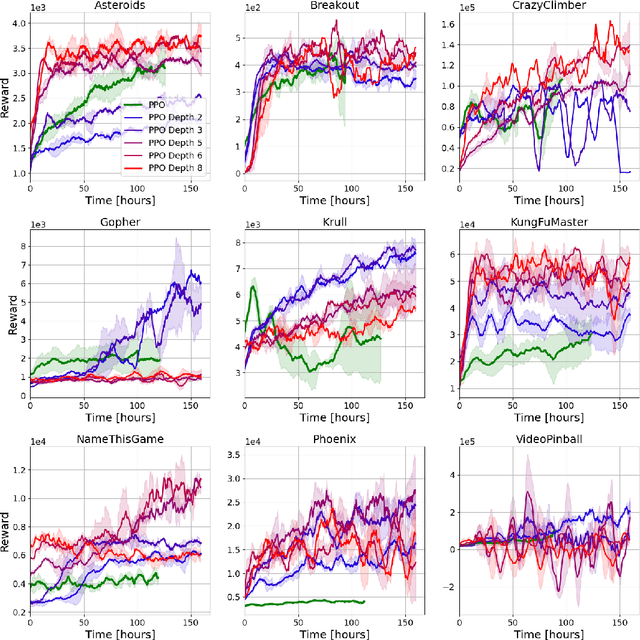
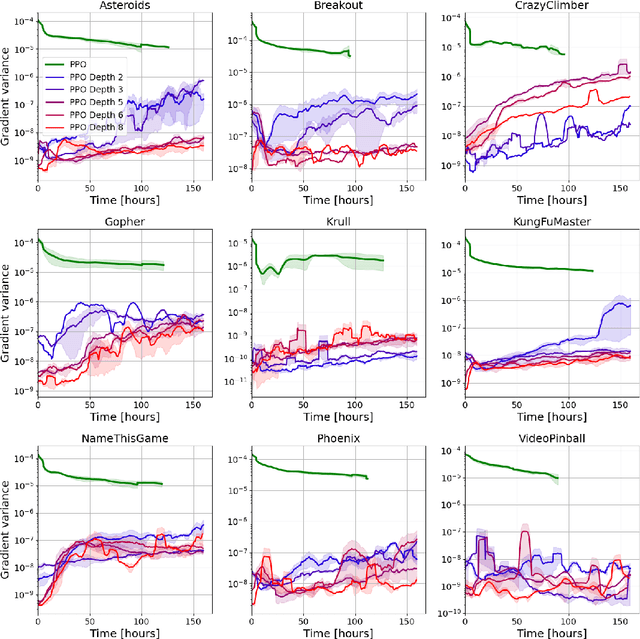
Policy-gradient methods are widely used for learning control policies. They can be easily distributed to multiple workers and reach state-of-the-art results in many domains. Unfortunately, they exhibit large variance and subsequently suffer from high-sample complexity since they aggregate gradients over entire trajectories. At the other extreme, planning methods, like tree search, optimize the policy using single-step transitions that consider future lookahead. These approaches have been mainly considered for value-based algorithms. Planning-based algorithms require a forward model and are computationally intensive at each step, but are more sample efficient. In this work, we introduce SoftTreeMax, the first approach that integrates tree-search into policy gradient. Traditionally, gradients are computed for single state-action pairs. Instead, our tree-based policy structure leverages all gradients at the tree leaves in each environment step. This allows us to reduce the variance of gradients by three orders of magnitude and to benefit from better sample complexity compared with standard policy gradient. On Atari, SoftTreeMax demonstrates up to 5x better performance in faster run-time compared with distributed PPO.
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Aug 02, 2022
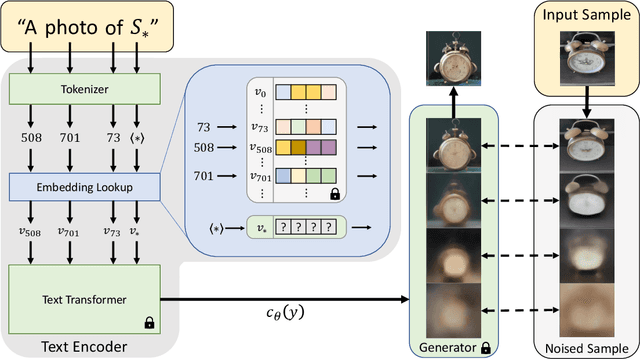

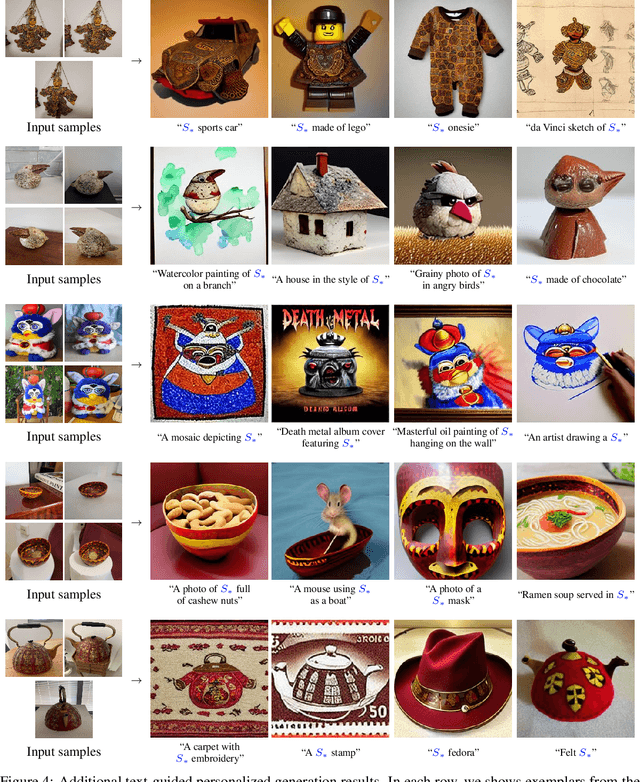
Text-to-image models offer unprecedented freedom to guide creation through natural language. Yet, it is unclear how such freedom can be exercised to generate images of specific unique concepts, modify their appearance, or compose them in new roles and novel scenes. In other words, we ask: how can we use language-guided models to turn our cat into a painting, or imagine a new product based on our favorite toy? Here we present a simple approach that allows such creative freedom. Using only 3-5 images of a user-provided concept, like an object or a style, we learn to represent it through new "words" in the embedding space of a frozen text-to-image model. These "words" can be composed into natural language sentences, guiding personalized creation in an intuitive way. Notably, we find evidence that a single word embedding is sufficient for capturing unique and varied concepts. We compare our approach to a wide range of baselines, and demonstrate that it can more faithfully portray the concepts across a range of applications and tasks. Our code, data and new words will be available at: https://textual-inversion.github.io
Implementing Reinforcement Learning Datacenter Congestion Control in NVIDIA NICs
Jul 05, 2022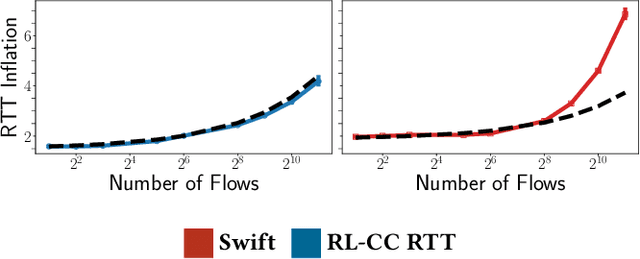

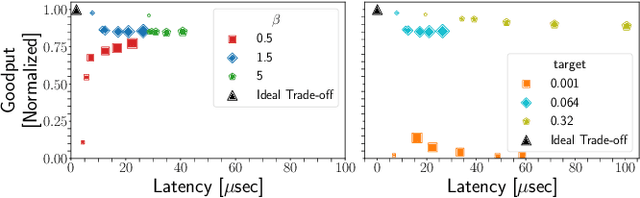
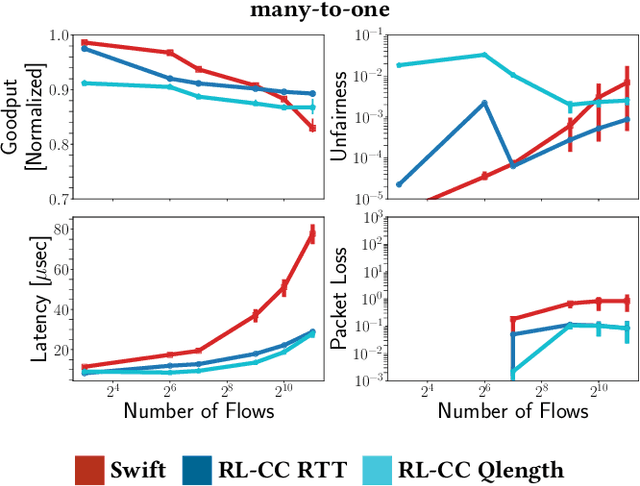
Cloud datacenters are exponentially growing both in numbers and size. This increase results in a network activity surge that warrants better congestion avoidance. The resulting challenge is two-fold: (i) designing algorithms that can be custom-tuned to the complex traffic patterns of a given datacenter; but, at the same time (ii) run on low-level hardware with the required low latency of effective Congestion Control (CC). In this work, we present a Reinforcement Learning (RL) based CC solution that learns from certain traffic scenarios and successfully generalizes to others. We then distill the RL neural network policy into binary decision trees to achieve the desired $\mu$sec decision latency required for real-time inference with RDMA. We deploy the distilled policy on NVIDIA NICs in a real network and demonstrate state-of-the-art performance, balancing all tested metrics simultaneously: bandwidth, latency, fairness, and packet drops.
Reinforcement Learning with a Terminator
May 30, 2022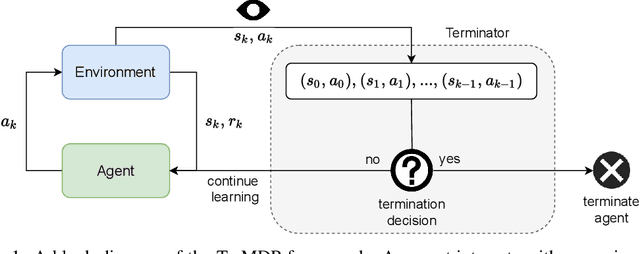
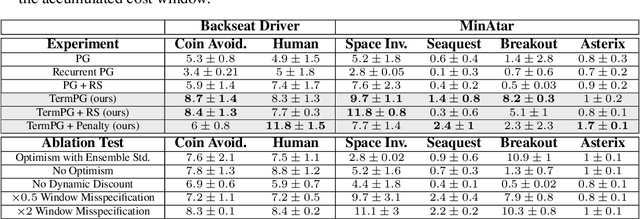
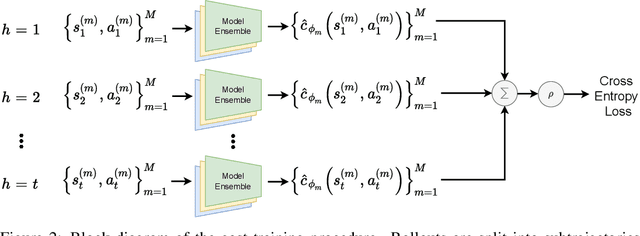
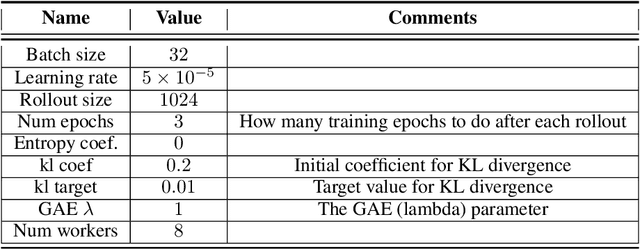
We present the problem of reinforcement learning with exogenous termination. We define the Termination Markov Decision Process (TerMDP), an extension of the MDP framework, in which episodes may be interrupted by an external non-Markovian observer. This formulation accounts for numerous real-world situations, such as a human interrupting an autonomous driving agent for reasons of discomfort. We learn the parameters of the TerMDP and leverage the structure of the estimation problem to provide state-wise confidence bounds. We use these to construct a provably-efficient algorithm, which accounts for termination, and bound its regret. Motivated by our theoretical analysis, we design and implement a scalable approach, which combines optimism (w.r.t. termination) and a dynamic discount factor, incorporating the termination probability. We deploy our method on high-dimensional driving and MinAtar benchmarks. Additionally, we test our approach on human data in a driving setting. Our results demonstrate fast convergence and significant improvement over various baseline approaches.
Optimizing Tensor Network Contraction Using Reinforcement Learning
Apr 18, 2022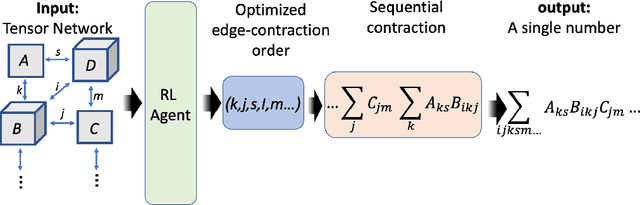
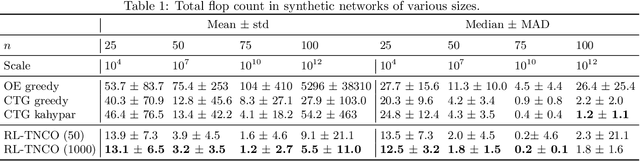
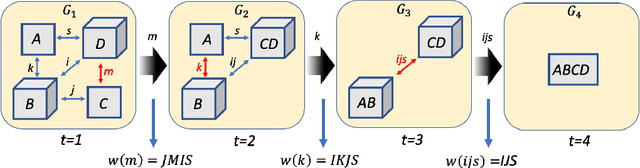

Quantum Computing (QC) stands to revolutionize computing, but is currently still limited. To develop and test quantum algorithms today, quantum circuits are often simulated on classical computers. Simulating a complex quantum circuit requires computing the contraction of a large network of tensors. The order (path) of contraction can have a drastic effect on the computing cost, but finding an efficient order is a challenging combinatorial optimization problem. We propose a Reinforcement Learning (RL) approach combined with Graph Neural Networks (GNN) to address the contraction ordering problem. The problem is extremely challenging due to the huge search space, the heavy-tailed reward distribution, and the challenging credit assignment. We show how a carefully implemented RL-agent that uses a GNN as the basic policy construct can address these challenges and obtain significant improvements over state-of-the-art techniques in three varieties of circuits, including the largest scale networks used in contemporary QC.