 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA PAC-Bayesian Perspective on the Interpolating Information Criterion
Nov 13, 2023Deep learning is renowned for its theory-practice gap, whereby principled theory typically fails to provide much beneficial guidance for implementation in practice. This has been highlighted recently by the benign overfitting phenomenon: when neural networks become sufficiently large to interpolate the dataset perfectly, model performance appears to improve with increasing model size, in apparent contradiction with the well-known bias-variance tradeoff. While such phenomena have proven challenging to theoretically study for general models, the recently proposed Interpolating Information Criterion (IIC) provides a valuable theoretical framework to examine performance for overparameterized models. Using the IIC, a PAC-Bayes bound is obtained for a general class of models, characterizing factors which influence generalization performance in the interpolating regime. From the provided bound, we quantify how the test error for overparameterized models achieving effectively zero training error depends on the quality of the implicit regularization imposed by e.g. the combination of model, optimizer, and parameter-initialization scheme; the spectrum of the empirical neural tangent kernel; curvature of the loss landscape; and noise present in the data.
The Interpolating Information Criterion for Overparameterized Models
Jul 15, 2023

The problem of model selection is considered for the setting of interpolating estimators, where the number of model parameters exceeds the size of the dataset. Classical information criteria typically consider the large-data limit, penalizing model size. However, these criteria are not appropriate in modern settings where overparameterized models tend to perform well. For any overparameterized model, we show that there exists a dual underparameterized model that possesses the same marginal likelihood, thus establishing a form of Bayesian duality. This enables more classical methods to be used in the overparameterized setting, revealing the Interpolating Information Criterion, a measure of model quality that naturally incorporates the choice of prior into the model selection. Our new information criterion accounts for prior misspecification, geometric and spectral properties of the model, and is numerically consistent with known empirical and theoretical behavior in this regime.
Monotonicity and Double Descent in Uncertainty Estimation with Gaussian Processes
Oct 14, 2022
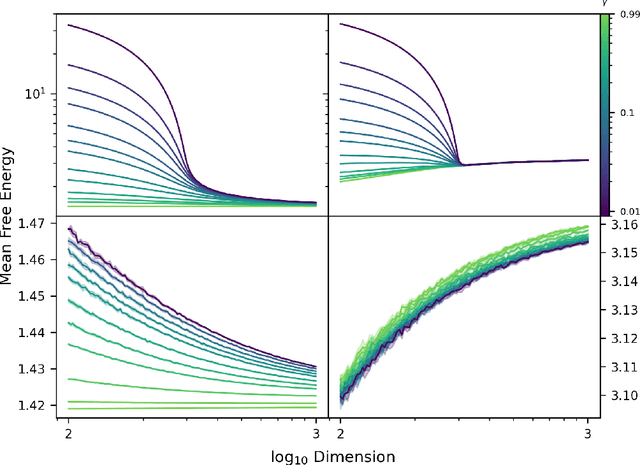
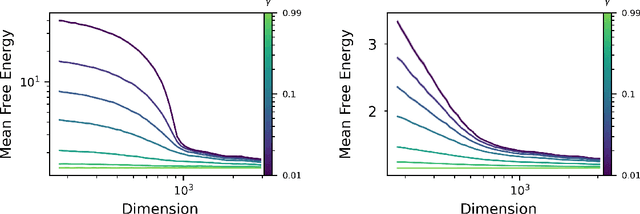
The quality of many modern machine learning models improves as model complexity increases, an effect that has been quantified, for predictive performance, with the non-monotonic double descent learning curve. Here, we address the overarching question: is there an analogous theory of double descent for models which estimate uncertainty? We provide a partially affirmative and partially negative answer in the setting of Gaussian processes (GP). Under standard assumptions, we prove that higher model quality for optimally-tuned GPs (including uncertainty prediction) under marginal likelihood is realized for larger input dimensions, and therefore exhibits a monotone error curve. After showing that marginal likelihood does not naturally exhibit double descent in the input dimension, we highlight related forms of posterior predictive loss that do exhibit non-monotonicity. Finally, we verify empirically that our results hold for real data, beyond our considered assumptions, and we explore consequences involving synthetic covariates.
Non-PSD Matrix Sketching with Applications to Regression and Optimization
Jun 16, 2021
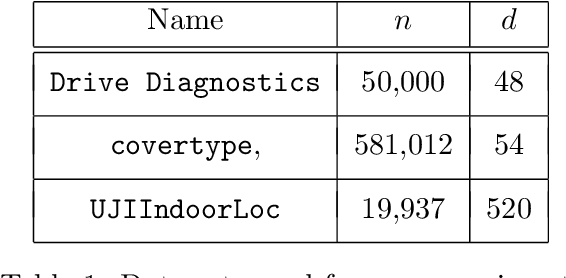
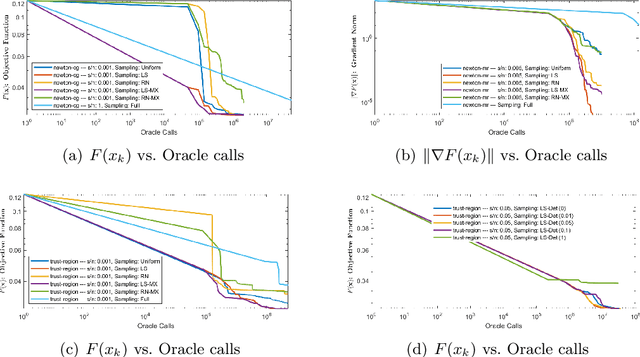
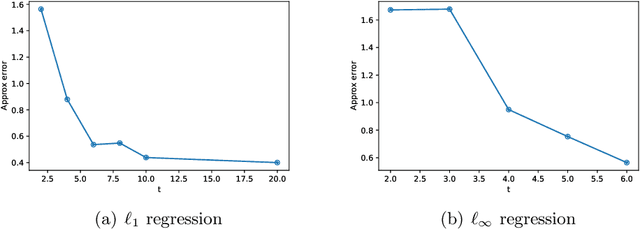
A variety of dimensionality reduction techniques have been applied for computations involving large matrices. The underlying matrix is randomly compressed into a smaller one, while approximately retaining many of its original properties. As a result, much of the expensive computation can be performed on the small matrix. The sketching of positive semidefinite (PSD) matrices is well understood, but there are many applications where the related matrices are not PSD, including Hessian matrices in non-convex optimization and covariance matrices in regression applications involving complex numbers. In this paper, we present novel dimensionality reduction methods for non-PSD matrices, as well as their ``square-roots", which involve matrices with complex entries. We show how these techniques can be used for multiple downstream tasks. In particular, we show how to use the proposed matrix sketching techniques for both convex and non-convex optimization, $\ell_p$-regression for every $1 \leq p \leq \infty$, and vector-matrix-vector queries.
Average-reward model-free reinforcement learning: a systematic review and literature mapping
Oct 18, 2020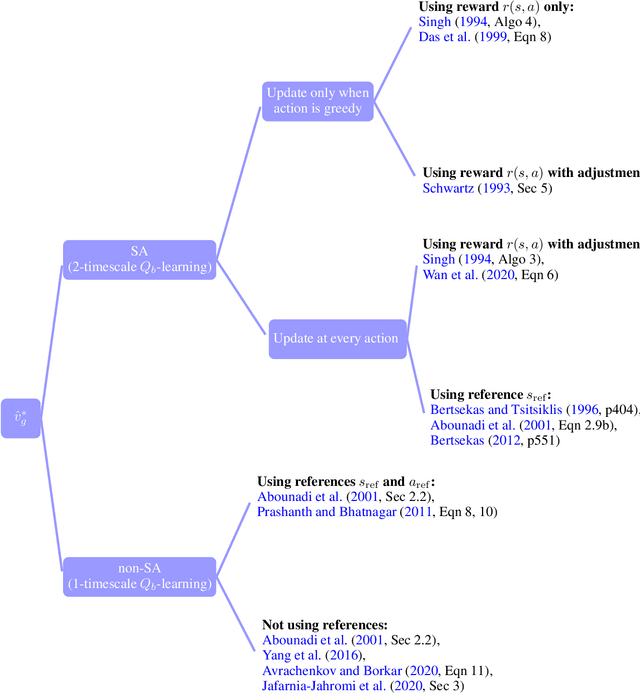

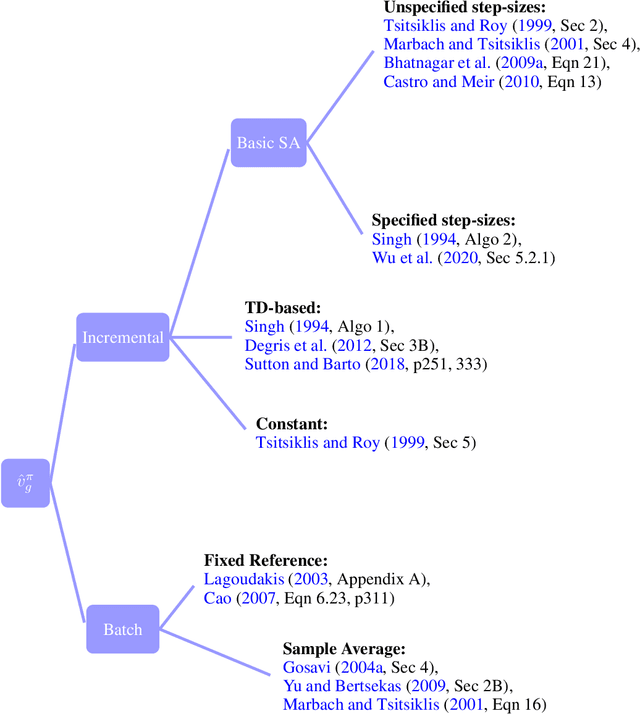
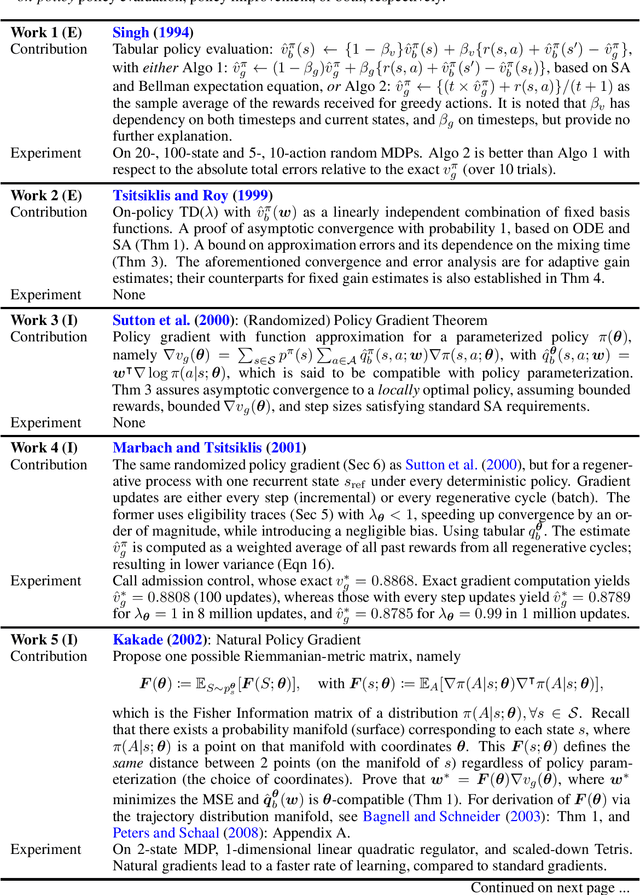
Model-free reinforcement learning (RL) has been an active area of research and provides a fundamental framework for agent-based learning and decision-making in artificial intelligence. In this paper, we review a specific subset of this literature, namely work that utilizes optimization criteria based on average rewards, in the infinite horizon setting. Average reward RL has the advantage of being the most selective criterion in recurrent (ergodic) Markov decision processes. In comparison to widely-used discounted reward criterion, it also requires no discount factor, which is a critical hyperparameter, and properly aligns the optimization and performance metrics. Motivated by the solo survey by Mahadevan (1996a), we provide an updated review of work in this area and extend it to cover policy-iteration and function approximation methods (in addition to the value-iteration and tabular counterparts). We also identify and discuss opportunities for future work.
Stochastic Normalizing Flows
Feb 25, 2020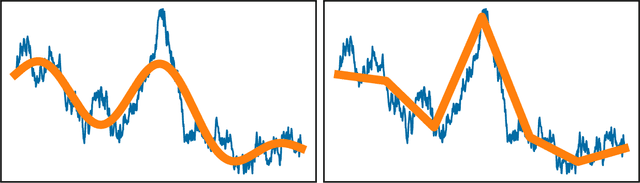
We introduce stochastic normalizing flows, an extension of continuous normalizing flows for maximum likelihood estimation and variational inference (VI) using stochastic differential equations (SDEs). Using the theory of rough paths, the underlying Brownian motion is treated as a latent variable and approximated, enabling efficient training of neural SDEs as random neural ordinary differential equations. These SDEs can be used for constructing efficient Markov chains to sample from the underlying distribution of a given dataset. Furthermore, by considering families of targeted SDEs with prescribed stationary distribution, we can apply VI to the optimization of hyperparameters in stochastic MCMC.
Avoiding Kernel Fixed Points: Computing with ELU and GELU Infinite Networks
Feb 22, 2020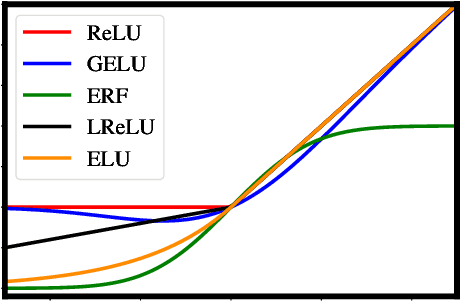
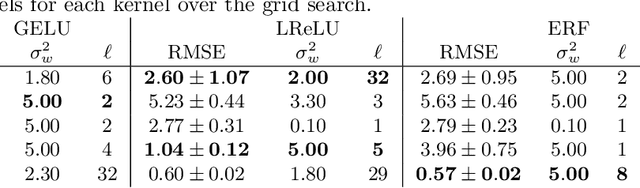
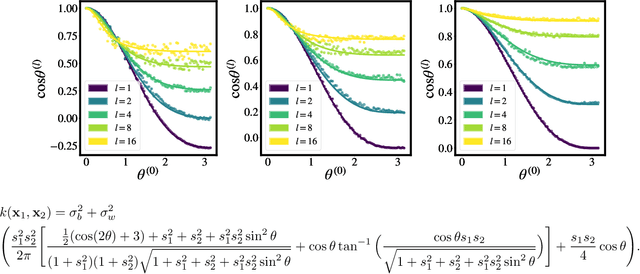
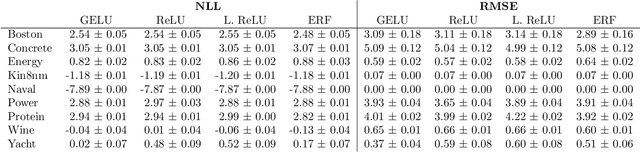
Analysing and computing with Gaussian processes arising from infinitely wide neural networks has recently seen a resurgence in popularity. Despite this, many explicit covariance functions of networks with activation functions used in modern networks remain unknown. Furthermore, while the kernels of deep networks can be computed iteratively, theoretical understanding of deep kernels is lacking, particularly with respect to fixed-point dynamics. Firstly, we derive the covariance functions of MLPs with exponential linear units and Gaussian error linear units and evaluate the performance of the limiting Gaussian processes on some benchmarks. Secondly, and more generally, we introduce a framework for analysing the fixed-point dynamics of iterated kernels corresponding to a broad range of activation functions. We find that unlike some previously studied neural network kernels, these new kernels exhibit non-trivial fixed-point dynamics which are mirrored in finite-width neural networks.
The reproducing Stein kernel approach for post-hoc corrected sampling
Jan 25, 2020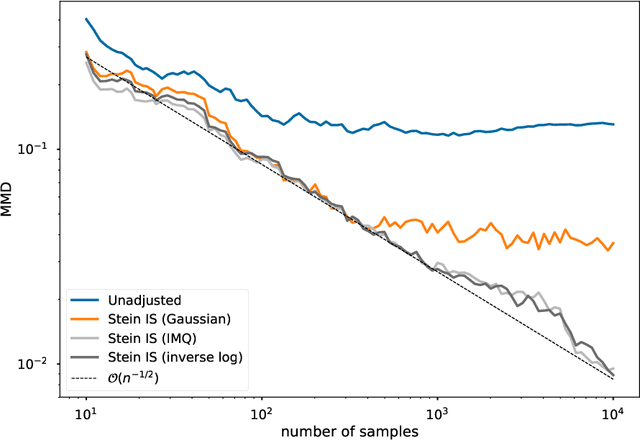
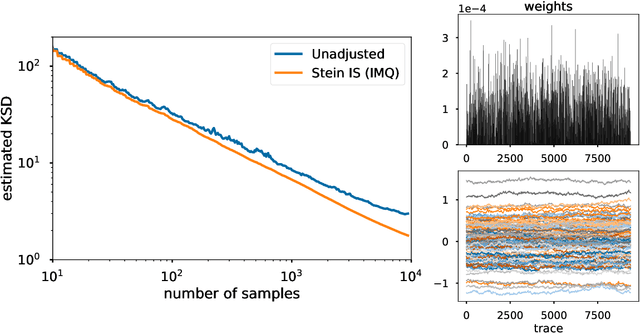
Stein importance sampling is a widely applicable technique based on kernelized Stein discrepancy, which corrects the output of approximate sampling algorithms by reweighting the empirical distribution of the samples. A general analysis of this technique is conducted for the previously unconsidered setting where samples are obtained via the simulation of a Markov chain, and applies to an arbitrary underlying Polish space. We prove that Stein importance sampling yields consistent estimators for quantities related to a target distribution of interest by using samples obtained from a geometrically ergodic Markov chain with a possibly unknown invariant measure that differs from the desired target. The approach is shown to be valid under conditions that are satisfied for a large number of unadjusted samplers, and is capable of retaining consistency when data subsampling is used. Along the way, a universal theory of reproducing Stein kernels is established, which enables the construction of kernelized Stein discrepancy on general Polish spaces, and provides sufficient conditions for kernels to be convergence-determining on such spaces. These results are of independent interest for the development of future methodology based on kernelized Stein discrepancies.
LSAR: Efficient Leverage Score Sampling Algorithm for the Analysis of Big Time Series Data
Dec 26, 2019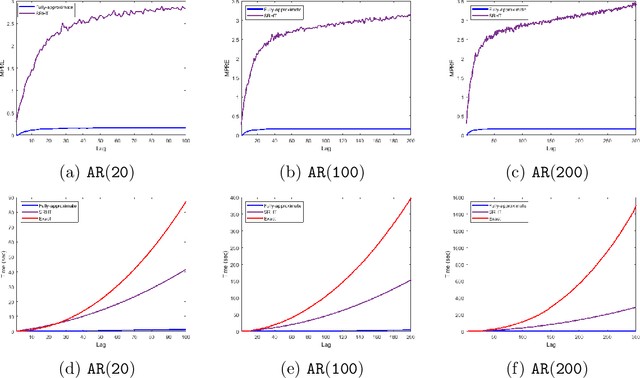
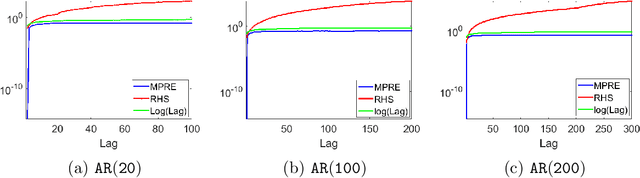
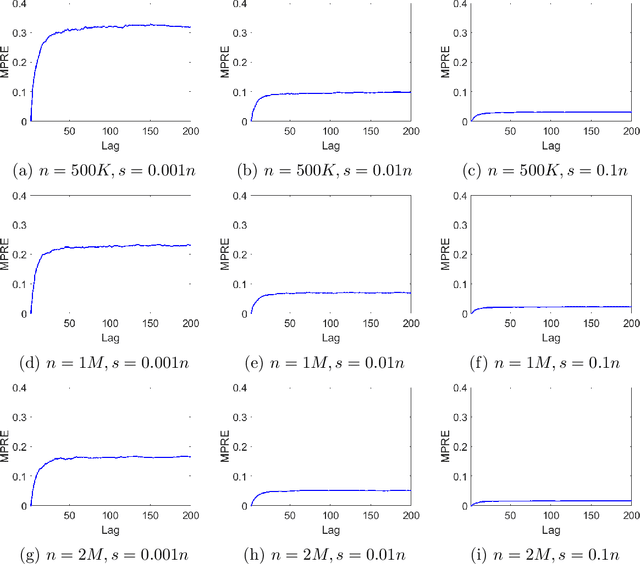
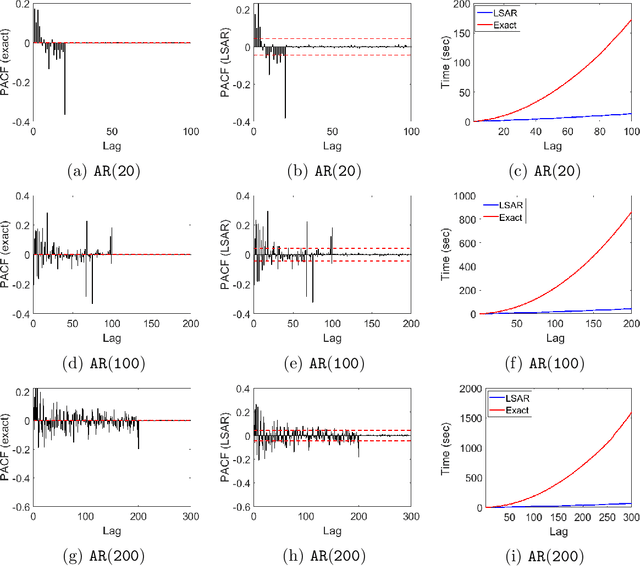
We apply methods from randomized numerical linear algebra (RandNLA) to develop improved algorithms for the analysis of large-scale time series data. We first develop a new fast algorithm to estimate the leverage scores of an autoregressive (AR) model in big data regimes. We show that the accuracy of approximations lies within $(1+\mathcal{O}(\varepsilon))$ of the true leverage scores with high probability. These theoretical results are subsequently exploited to develop an efficient algorithm, called LSAR, for fitting an appropriate AR model to big time series data. Our proposed algorithm is guaranteed, with high probability, to find the maximum likelihood estimates of the parameters of the underlying true AR model and has a worst case running time that significantly improves those of the state-of-the-art alternatives in big data regimes. Empirical results on large-scale synthetic as well as real data highly support the theoretical results and reveal the efficacy of this new approach.
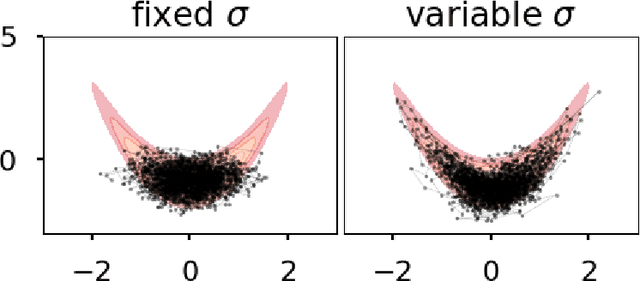
Richer priors for infinitely wide multi-layer perceptrons
Nov 29, 2019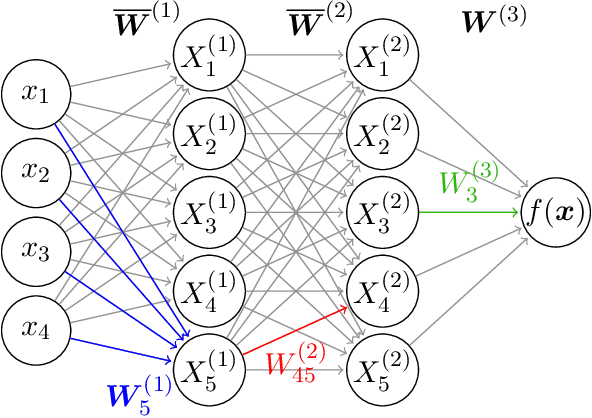
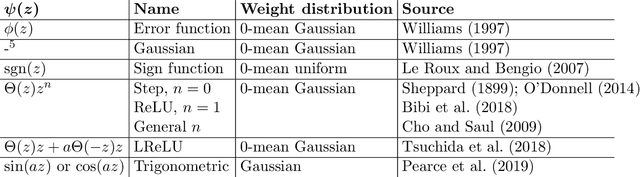
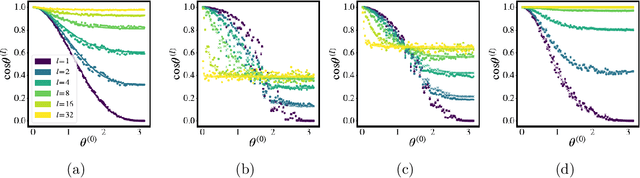

It is well-known that the distribution over functions induced through a zero-mean iid prior distribution over the parameters of a multi-layer perceptron (MLP) converges to a Gaussian process (GP), under mild conditions. We extend this result firstly to independent priors with general zero or non-zero means, and secondly to a family of partially exchangeable priors which generalise iid priors. We discuss how the second prior arises naturally when considering an equivalence class of functions in an MLP and through training processes such as stochastic gradient descent. The model resulting from partially exchangeable priors is a GP, with an additional level of inference in the sense that the prior and posterior predictive distributions require marginalisation over hyperparameters. We derive the kernels of the limiting GP in deep MLPs, and show empirically that these kernels avoid certain pathologies present in previously studied priors. We empirically evaluate our claims of convergence by measuring the maximum mean discrepancy between finite width models and limiting models. We compare the performance of our new limiting model to some previously discussed models on synthetic regression problems. We observe increasing ill-conditioning of the marginal likelihood and hyper-posterior as the depth of the model increases, drawing parallels with finite width networks which require notoriously involved optimisation tricks.