 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSig-DEG for Distillation: Making Diffusion Models Faster and Lighter
Aug 23, 2025Diffusion models have achieved state-of-the-art results in generative modelling but remain computationally intensive at inference time, often requiring thousands of discretization steps. To this end, we propose Sig-DEG (Signature-based Differential Equation Generator), a novel generator for distilling pre-trained diffusion models, which can universally approximate the backward diffusion process at a coarse temporal resolution. Inspired by high-order approximations of stochastic differential equations (SDEs), Sig-DEG leverages partial signatures to efficiently summarize Brownian motion over sub-intervals and adopts a recurrent structure to enable accurate global approximation of the SDE solution. Distillation is formulated as a supervised learning task, where Sig-DEG is trained to match the outputs of a fine-resolution diffusion model on a coarse time grid. During inference, Sig-DEG enables fast generation, as the partial signature terms can be simulated exactly without requiring fine-grained Brownian paths. Experiments demonstrate that Sig-DEG achieves competitive generation quality while reducing the number of inference steps by an order of magnitude. Our results highlight the effectiveness of signature-based approximations for efficient generative modeling.
A Comprehensive Sustainable Framework for Machine Learning and Artificial Intelligence
Jul 17, 2024



In financial applications, regulations or best practices often lead to specific requirements in machine learning relating to four key pillars: fairness, privacy, interpretability and greenhouse gas emissions. These all sit in the broader context of sustainability in AI, an emerging practical AI topic. However, although these pillars have been individually addressed by past literature, none of these works have considered all the pillars. There are inherent trade-offs between each of the pillars (for example, accuracy vs fairness or accuracy vs privacy), making it even more important to consider them together. This paper outlines a new framework for Sustainable Machine Learning and proposes FPIG, a general AI pipeline that allows for these critical topics to be considered simultaneously to learn the trade-offs between the pillars better. Based on the FPIG framework, we propose a meta-learning algorithm to estimate the four key pillars given a dataset summary, model architecture, and hyperparameters before model training. This algorithm allows users to select the optimal model architecture for a given dataset and a given set of user requirements on the pillars. We illustrate the trade-offs under the FPIG model on three classical datasets and demonstrate the meta-learning approach with an example of real-world datasets and models with different interpretability, showcasing how it can aid model selection.
Online Personalizing White-box LLMs Generation with Neural Bandits
Apr 24, 2024



The advent of personalized content generation by LLMs presents a novel challenge: how to efficiently adapt text to meet individual preferences without the unsustainable demand of creating a unique model for each user. This study introduces an innovative online method that employs neural bandit algorithms to dynamically optimize soft instruction embeddings based on user feedback, enhancing the personalization of open-ended text generation by white-box LLMs. Through rigorous experimentation on various tasks, we demonstrate significant performance improvements over baseline strategies. NeuralTS, in particular, leads to substantial enhancements in personalized news headline generation, achieving up to a 62.9% improvement in terms of best ROUGE scores and up to 2.76% increase in LLM-agent evaluation against the baseline.
Debiasing classifiers: is reality at variance with expectation?
Nov 04, 2020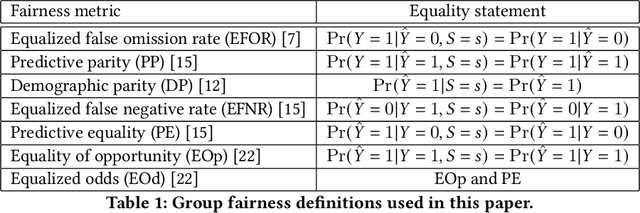
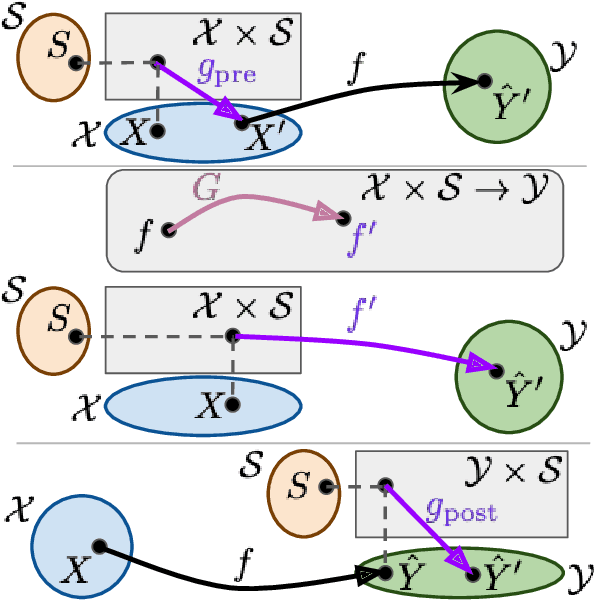
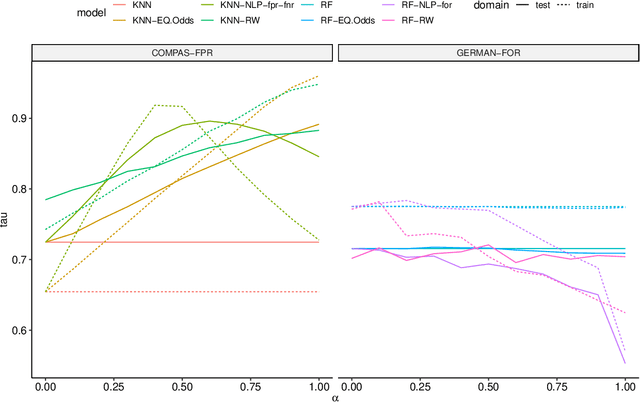
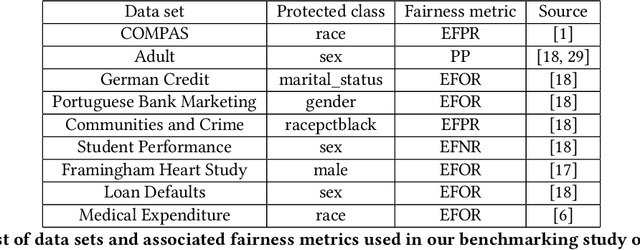
Many methods for debiasing classifiers have been proposed, but their effectiveness in practice remains unclear. We evaluate the performance of pre-processing and post-processing debiasers for improving fairness in random forest classifiers trained on a suite of data sets. Specifically, we study how these debiasers generalize with respect to both out-of-sample test error for computing fairness -- performance and fairness -- fairness trade-offs, and on the change in other fairness metrics that were not explicitly optimised. Our results demonstrate that out-of-sample performance on fairness and performance can vary substantially and unexpectedly. Moreover, the variance in estimation arises from class imbalances with respect to both the outcome and the protected classes. Our results highlight the importance of evaluating out-of-sample performance in practical usage.