 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWellDunn: On the Robustness and Explainability of Language Models and Large Language Models in Identifying Wellness Dimensions
Jun 17, 2024



Language Models (LMs) are being proposed for mental health applications where the heightened risk of adverse outcomes means predictive performance may not be a sufficient litmus test of a model's utility in clinical practice. A model that can be trusted for practice should have a correspondence between explanation and clinical determination, yet no prior research has examined the attention fidelity of these models and their effect on ground truth explanations. We introduce an evaluation design that focuses on the robustness and explainability of LMs in identifying Wellness Dimensions (WD). We focus on two mental health and well-being datasets: (a) Multi-label Classification-based MultiWD, and (b) WellXplain for evaluating attention mechanism veracity against expert-labeled explanations. The labels are based on Halbert Dunn's theory of wellness, which gives grounding to our evaluation. We reveal four surprising results about LMs/LLMs: (1) Despite their human-like capabilities, GPT-3.5/4 lag behind RoBERTa, and MedAlpaca, a fine-tuned LLM fails to deliver any remarkable improvements in performance or explanations. (2) Re-examining LMs' predictions based on a confidence-oriented loss function reveals a significant performance drop. (3) Across all LMs/LLMs, the alignment between attention and explanations remains low, with LLMs scoring a dismal 0.0. (4) Most mental health-specific LMs/LLMs overlook domain-specific knowledge and undervalue explanations, causing these discrepancies. This study highlights the need for further research into their consistency and explanations in mental health and well-being.
Optimizing the Optimal Weighted Average: Efficient Distributed Sparse Classification
Jun 03, 2024While distributed training is often viewed as a solution to optimizing linear models on increasingly large datasets, inter-machine communication costs of popular distributed approaches can dominate as data dimensionality increases. Recent work on non-interactive algorithms shows that approximate solutions for linear models can be obtained efficiently with only a single round of communication among machines. However, this approximation often degenerates as the number of machines increases. In this paper, building on the recent optimal weighted average method, we introduce a new technique, ACOWA, that allows an extra round of communication to achieve noticeably better approximation quality with minor runtime increases. Results show that for sparse distributed logistic regression, ACOWA obtains solutions that are more faithful to the empirical risk minimizer and attain substantially higher accuracy than other distributed algorithms.
InteractiveIE: Towards Assessing the Strength of Human-AI Collaboration in Improving the Performance of Information Extraction
May 24, 2023



Learning template based information extraction from documents is a crucial yet difficult task. Prior template-based IE approaches assume foreknowledge of the domain templates; however, real-world IE do not have pre-defined schemas and it is a figure-out-as you go phenomena. To quickly bootstrap templates in a real-world setting, we need to induce template slots from documents with zero or minimal supervision. Since the purpose of question answering intersect with the goal of information extraction, we use automatic question generation to induce template slots from the documents and investigate how a tiny amount of a proxy human-supervision on-the-fly (termed as InteractiveIE) can further boost the performance. Extensive experiments on biomedical and legal documents, where obtaining training data is expensive, reveal encouraging trends of performance improvement using InteractiveIE over AI-only baseline.
POQue: Asking Participant-specific Outcome Questions for a Deeper Understanding of Complex Events
Dec 05, 2022



Knowledge about outcomes is critical for complex event understanding but is hard to acquire. We show that by pre-identifying a participant in a complex event, crowd workers are able to (1) infer the collective impact of salient events that make up the situation, (2) annotate the volitional engagement of participants in causing the situation, and (3) ground the outcome of the situation in state changes of the participants. By creating a multi-step interface and a careful quality control strategy, we collect a high quality annotated dataset of 8K short newswire narratives and ROCStories with high inter-annotator agreement (0.74-0.96 weighted Fleiss Kappa). Our dataset, POQue (Participant Outcome Questions), enables the exploration and development of models that address multiple aspects of semantic understanding. Experimentally, we show that current language models lag behind human performance in subtle ways through our task formulations that target abstract and specific comprehension of a complex event, its outcome, and a participant's influence over the event culmination.
A General Framework for Auditing Differentially Private Machine Learning
Oct 16, 2022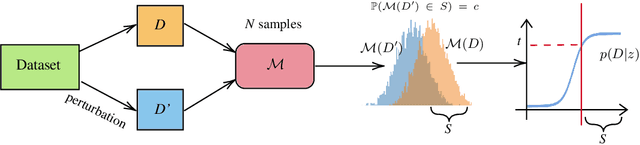

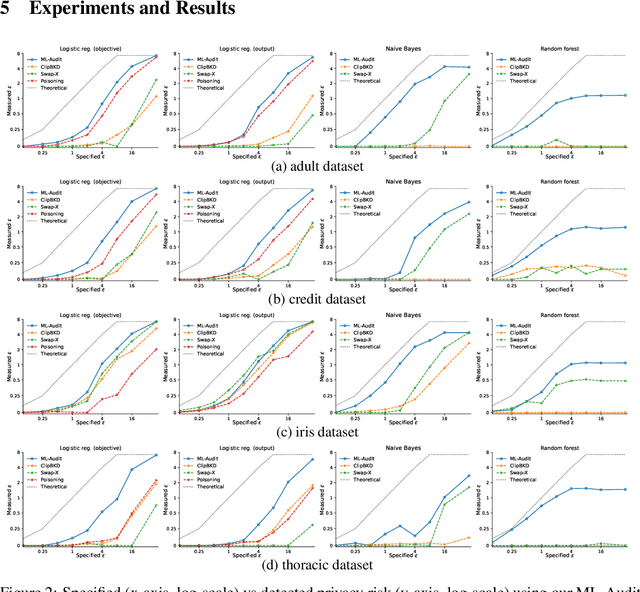
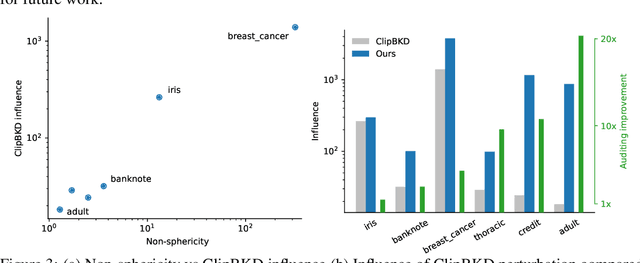
We present a framework to statistically audit the privacy guarantee conferred by a differentially private machine learner in practice. While previous works have taken steps toward evaluating privacy loss through poisoning attacks or membership inference, they have been tailored to specific models or have demonstrated low statistical power. Our work develops a general methodology to empirically evaluate the privacy of differentially private machine learning implementations, combining improved privacy search and verification methods with a toolkit of influence-based poisoning attacks. We demonstrate significantly improved auditing power over previous approaches on a variety of models including logistic regression, Naive Bayes, and random forest. Our method can be used to detect privacy violations due to implementation errors or misuse. When violations are not present, it can aid in understanding the amount of information that can be leaked from a given dataset, algorithm, and privacy specification.
PASTA: A Dataset for Modeling Participant States in Narratives
Jul 31, 2022
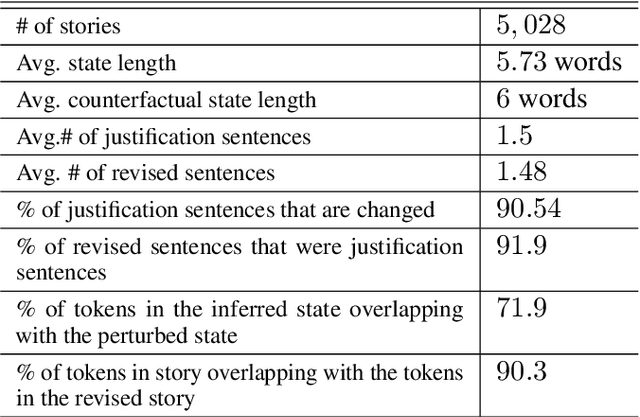
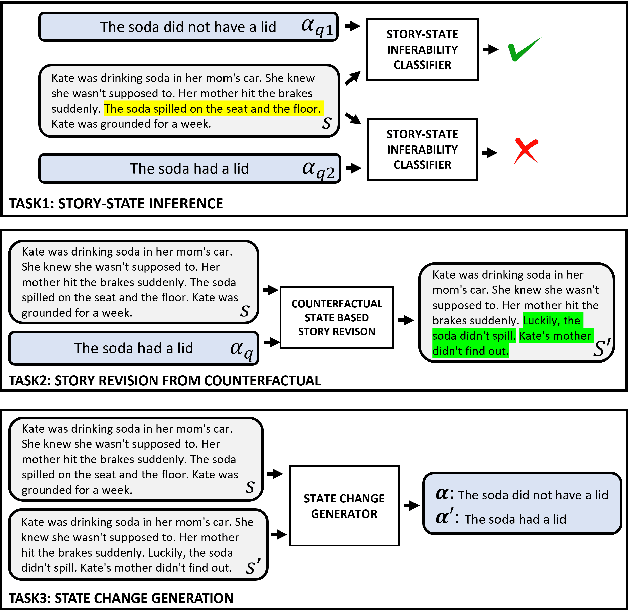
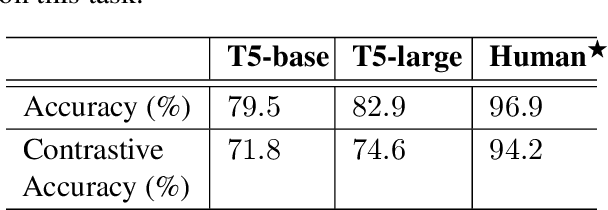
The events in a narrative can be understood as a coherent whole via the underlying states of its participants. Often, these participant states are not explicitly mentioned in the narrative, left to be filled in via common-sense or inference. A model that understands narratives should be able to infer these implicit participant states and reason about the impact of changes to these states on the narrative. To facilitate this goal, we introduce a new crowdsourced Participants States dataset, PASTA. This dataset contains valid, inferable participant states; a counterfactual perturbation to the state; and the changes to the story that would be necessary if the counterfactual was true. We introduce three state-based reasoning tasks that test for the ability to infer when a state is entailed by a story, revise a story for a counterfactual state, and to explain the most likely state change given a revised story. Our benchmarking experiments show that while today's LLMs are able to reason about states to some degree, there is a large room for improvement, suggesting potential avenues for future research.
Neural Bregman Divergences for Distance Learning
Jun 09, 2022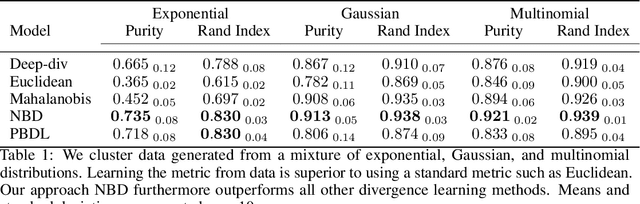
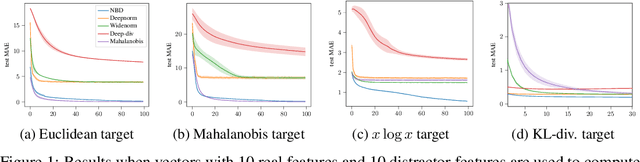
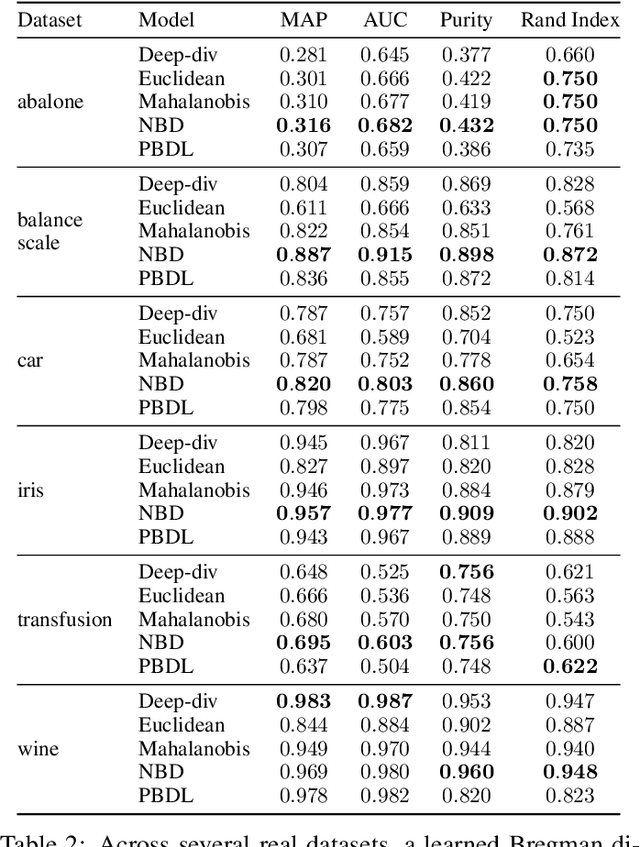
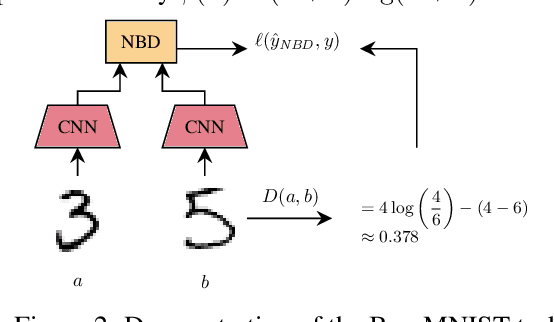
Many metric learning tasks, such as triplet learning, nearest neighbor retrieval, and visualization, are treated primarily as embedding tasks where the ultimate metric is some variant of the Euclidean distance (e.g., cosine or Mahalanobis), and the algorithm must learn to embed points into the pre-chosen space. The study of non-Euclidean geometries or appropriateness is often not explored, which we believe is due to a lack of tools for learning non-Euclidean measures of distance. Under the belief that the use of asymmetric methods in particular have lacked sufficient study, we propose a new approach to learning arbitrary Bergman divergences in a differentiable manner via input convex neural networks. Over a set of both new and previously studied tasks, including asymmetric regression, ranking, and clustering, we demonstrate that our method more faithfully learns divergences than prior Bregman learning approaches. In doing so we obtain the first method for learning neural Bregman divergences and with it inherit the many nice mathematical properties of Bregman divergences, providing the foundation and tooling for better developing and studying asymmetric distance learning.
RevUp: Revise and Update Information Bottleneck for Event Representation
May 24, 2022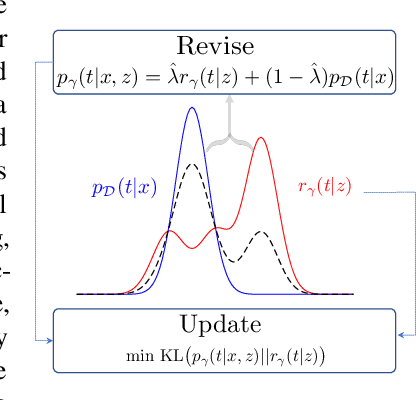

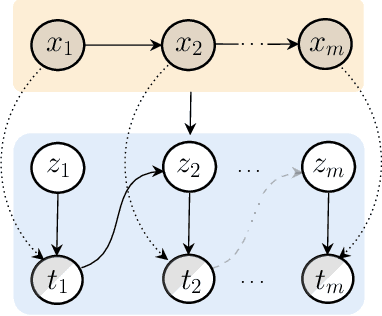
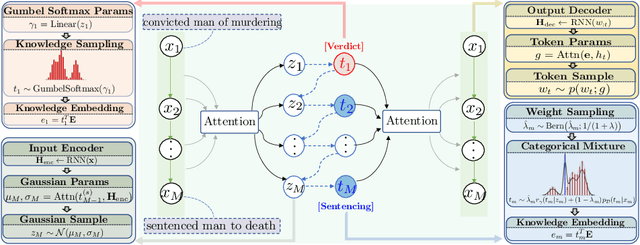
In machine learning, latent variables play a key role to capture the underlying structure of data, but they are often unsupervised. When we have side knowledge that already has high-level information about the input data, we can use that source to guide latent variables and capture the available background information in a process called "parameter injection." In that regard, we propose a semi-supervised information bottleneck-based model that enables the use of side knowledge, even if it is noisy and imperfect, to direct the learning of discrete latent variables. Fundamentally, we introduce an auxiliary continuous latent variable as a way to reparameterize the model's discrete variables with a light-weight hierarchical structure. With this reparameterization, the model's discrete latent variables are learned to minimize the mutual information between the observed data and optional side knowledge that is not already captured by the new, auxiliary variables. We theoretically show that our approach generalizes an existing method of parameter injection, and perform an empirical case study of our approach on language-based event modeling. We corroborate our theoretical results with strong empirical experiments, showing that the proposed method outperforms previous proposed approaches on multiple datasets.
Continuously Generalized Ordinal Regression for Linear and Deep Models
Feb 14, 2022

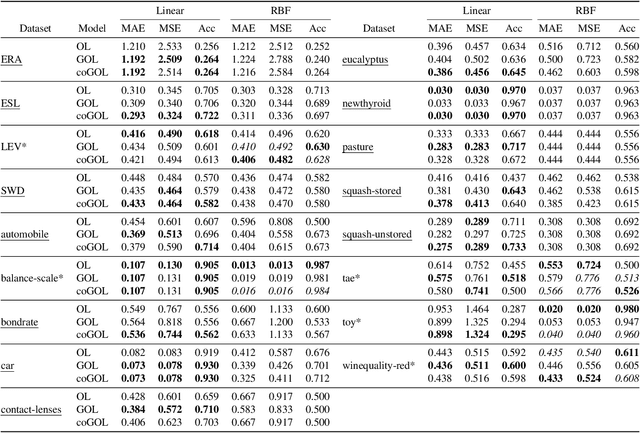
Ordinal regression is a classification task where classes have an order and prediction error increases the further the predicted class is from the true class. The standard approach for modeling ordinal data involves fitting parallel separating hyperplanes that optimize a certain loss function. This assumption offers sample efficient learning via inductive bias, but is often too restrictive in real-world datasets where features may have varying effects across different categories. Allowing class-specific hyperplane slopes creates generalized logistic ordinal regression, increasing the flexibility of the model at a cost to sample efficiency. We explore an extension of the generalized model to the all-thresholds logistic loss and propose a regularization approach that interpolates between these two extremes. Our method, which we term continuously generalized ordinal logistic, significantly outperforms the standard ordinal logistic model over a thorough set of ordinal regression benchmark datasets. We further extend this method to deep learning and show that it achieves competitive or lower prediction error compared to previous models over a range of datasets and modalities. Furthermore, two primary alternative models for deep learning ordinal regression are shown to be special cases of our framework.
Bridging the Gap: Using Deep Acoustic Representations to Learn Grounded Language from Percepts and Raw Speech
Dec 27, 2021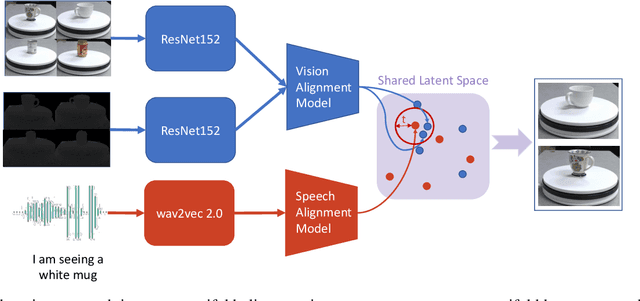
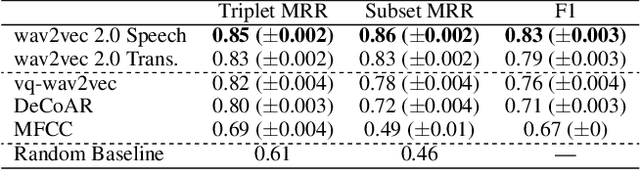
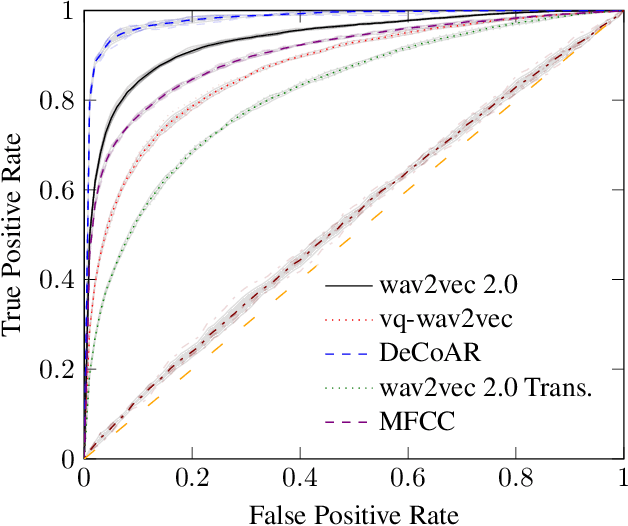
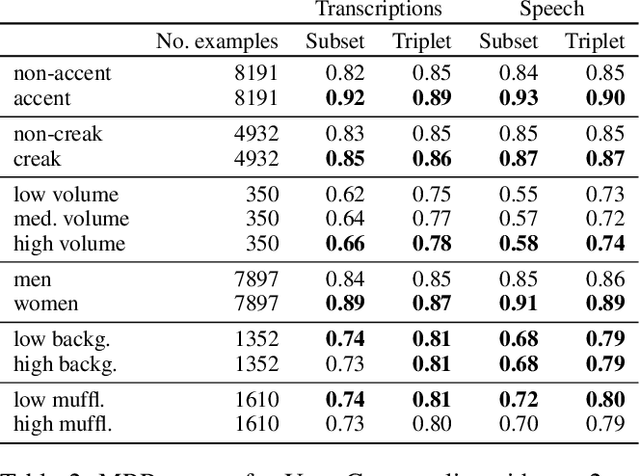
Learning to understand grounded language, which connects natural language to percepts, is a critical research area. Prior work in grounded language acquisition has focused primarily on textual inputs. In this work we demonstrate the feasibility of performing grounded language acquisition on paired visual percepts and raw speech inputs. This will allow interactions in which language about novel tasks and environments is learned from end users, reducing dependence on textual inputs and potentially mitigating the effects of demographic bias found in widely available speech recognition systems. We leverage recent work in self-supervised speech representation models and show that learned representations of speech can make language grounding systems more inclusive towards specific groups while maintaining or even increasing general performance.