 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Minimization of Polarization and Disagreement via Low-Rank Matrix Bandits
Oct 01, 2025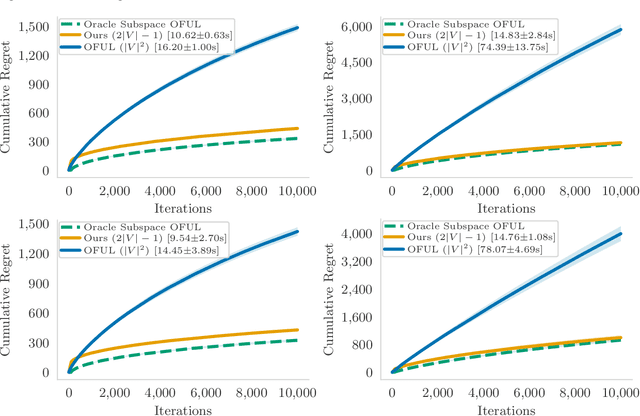

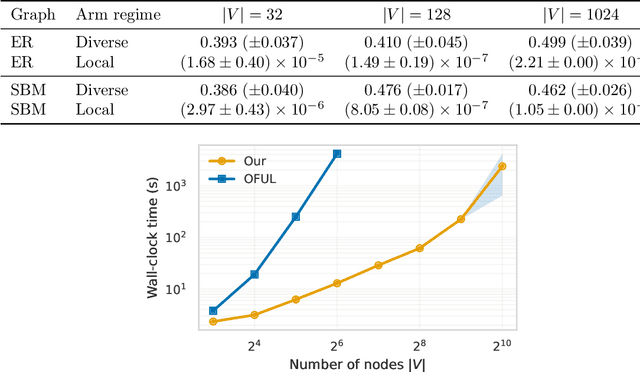
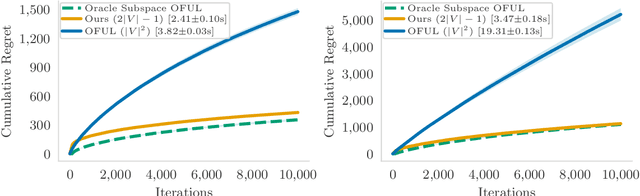
We study the problem of minimizing polarization and disagreement in the Friedkin-Johnsen opinion dynamics model under incomplete information. Unlike prior work that assumes a static setting with full knowledge of users' innate opinions, we address the more realistic online setting where innate opinions are unknown and must be learned through sequential observations. This novel setting, which naturally mirrors periodic interventions on social media platforms, is formulated as a regret minimization problem, establishing a key connection between algorithmic interventions on social media platforms and theory of multi-armed bandits. In our formulation, a learner observes only a scalar feedback of the overall polarization and disagreement after an intervention. For this novel bandit problem, we propose a two-stage algorithm based on low-rank matrix bandits. The algorithm first performs subspace estimation to identify an underlying low-dimensional structure, and then employs a linear bandit algorithm within the compact dimensional representation derived from the estimated subspace. We prove that our algorithm achieves an $ \widetilde{O}(\sqrt{T}) $ cumulative regret over any time horizon $T$. Empirical results validate that our algorithm significantly outperforms a linear bandit baseline in terms of both cumulative regret and running time.
Size-adaptive Hypothesis Testing for Fairness
Jun 12, 2025Determining whether an algorithmic decision-making system discriminates against a specific demographic typically involves comparing a single point estimate of a fairness metric against a predefined threshold. This practice is statistically brittle: it ignores sampling error and treats small demographic subgroups the same as large ones. The problem intensifies in intersectional analyses, where multiple sensitive attributes are considered jointly, giving rise to a larger number of smaller groups. As these groups become more granular, the data representing them becomes too sparse for reliable estimation, and fairness metrics yield excessively wide confidence intervals, precluding meaningful conclusions about potential unfair treatments. In this paper, we introduce a unified, size-adaptive, hypothesis-testing framework that turns fairness assessment into an evidence-based statistical decision. Our contribution is twofold. (i) For sufficiently large subgroups, we prove a Central-Limit result for the statistical parity difference, leading to analytic confidence intervals and a Wald test whose type-I (false positive) error is guaranteed at level $\alpha$. (ii) For the long tail of small intersectional groups, we derive a fully Bayesian Dirichlet-multinomial estimator; Monte-Carlo credible intervals are calibrated for any sample size and naturally converge to Wald intervals as more data becomes available. We validate our approach empirically on benchmark datasets, demonstrating how our tests provide interpretable, statistically rigorous decisions under varying degrees of data availability and intersectionality.
Bounded-Abstention Pairwise Learning to Rank
May 29, 2025Ranking systems influence decision-making in high-stakes domains like health, education, and employment, where they can have substantial economic and social impacts. This makes the integration of safety mechanisms essential. One such mechanism is $\textit{abstention}$, which enables algorithmic decision-making system to defer uncertain or low-confidence decisions to human experts. While abstention have been predominantly explored in the context of classification tasks, its application to other machine learning paradigms remains underexplored. In this paper, we introduce a novel method for abstention in pairwise learning-to-rank tasks. Our approach is based on thresholding the ranker's conditional risk: the system abstains from making a decision when the estimated risk exceeds a predefined threshold. Our contributions are threefold: a theoretical characterization of the optimal abstention strategy, a model-agnostic, plug-in algorithm for constructing abstaining ranking models, and a comprehensive empirical evaluations across multiple datasets, demonstrating the effectiveness of our approach.
Finding Counterfactual Evidences for Node Classification
May 16, 2025Counterfactual learning is emerging as an important paradigm, rooted in causality, which promises to alleviate common issues of graph neural networks (GNNs), such as fairness and interpretability. However, as in many real-world application domains where conducting randomized controlled trials is impractical, one has to rely on available observational (factual) data to detect counterfactuals. In this paper, we introduce and tackle the problem of searching for counterfactual evidences for the GNN-based node classification task. A counterfactual evidence is a pair of nodes such that, regardless they exhibit great similarity both in the features and in their neighborhood subgraph structures, they are classified differently by the GNN. We develop effective and efficient search algorithms and a novel indexing solution that leverages both node features and structural information to identify counterfactual evidences, and generalizes beyond any specific GNN. Through various downstream applications, we demonstrate the potential of counterfactual evidences to enhance fairness and accuracy of GNNs.
Engagement-Driven Content Generation with Large Language Models
Nov 21, 2024



Large Language Models (LLMs) exhibit significant persuasion capabilities in one-on-one interactions, but their influence within social networks remains underexplored. This study investigates the potential social impact of LLMs in these environments, where interconnected users and complex opinion dynamics pose unique challenges. In particular, we address the following research question: can LLMs learn to generate meaningful content that maximizes user engagement on social networks? To answer this question, we define a pipeline to guide the LLM-based content generation which employs reinforcement learning with simulated feedback. In our framework, the reward is based on an engagement model borrowed from the literature on opinion dynamics and information propagation. Moreover, we force the text generated by the LLM to be aligned with a given topic and to satisfy a minimum fluency requirement. Using our framework, we analyze the capabilities and limitations of LLMs in tackling the given task, specifically considering the relative positions of the LLM as an agent within the social network and the distribution of opinions in the network on the given topic. Our findings show the full potential of LLMs in creating social engagement. Notable properties of our approach are that the learning procedure is adaptive to the opinion distribution of the underlying network and agnostic to the specifics of the engagement model, which is embedded as a plug-and-play component. In this regard, our approach can be easily refined for more complex engagement tasks and interventions in computational social science. The code used for the experiments is publicly available at https://anonymous.4open.science/r/EDCG/.
Algorithmic Drift: A Simulation Framework to Study the Effects of Recommender Systems on User Preferences
Sep 24, 2024



Digital platforms such as social media and e-commerce websites adopt Recommender Systems to provide value to the user. However, the social consequences deriving from their adoption are still unclear. Many scholars argue that recommenders may lead to detrimental effects, such as bias-amplification deriving from the feedback loop between algorithmic suggestions and users' choices. Nonetheless, the extent to which recommenders influence changes in users leaning remains uncertain. In this context, it is important to provide a controlled environment for evaluating the recommendation algorithm before deployment. To address this, we propose a stochastic simulation framework that mimics user-recommender system interactions in a long-term scenario. In particular, we simulate the user choices by formalizing a user model, which comprises behavioral aspects, such as the user resistance towards the recommendation algorithm and their inertia in relying on the received suggestions. Additionally, we introduce two novel metrics for quantifying the algorithm's impact on user preferences, specifically in terms of drift over time. We conduct an extensive evaluation on multiple synthetic datasets, aiming at testing the robustness of our framework when considering different scenarios and hyper-parameters setting. The experimental results prove that the proposed methodology is effective in detecting and quantifying the drift over the users preferences by means of the simulation. All the code and data used to perform the experiments are publicly available.
Link Polarity Prediction from Sparse and Noisy Labels via Multiscale Social Balance
Jul 22, 2024



Signed Graph Neural Networks (SGNNs) have recently gained attention as an effective tool for several learning tasks on signed networks, i.e., graphs where edges have an associated polarity. One of these tasks is to predict the polarity of the links for which this information is missing, starting from the network structure and the other available polarities. However, when the available polarities are few and potentially noisy, such a task becomes challenging. In this work, we devise a semi-supervised learning framework that builds around the novel concept of \emph{multiscale social balance} to improve the prediction of link polarities in settings characterized by limited data quantity and quality. Our model-agnostic approach can seamlessly integrate with any SGNN architecture, dynamically reweighting the importance of each data sample while making strategic use of the structural information from unlabeled edges combined with social balance theory. Empirical validation demonstrates that our approach outperforms established baseline models, effectively addressing the limitations imposed by noisy and sparse data. This result underlines the benefits of incorporating multiscale social balance into SGNNs, opening new avenues for robust and accurate predictions in signed network analysis.
Multilayer Correlation Clustering
Apr 25, 2024


In this paper, we establish Multilayer Correlation Clustering, a novel generalization of Correlation Clustering (Bansal et al., FOCS '02) to the multilayer setting. In this model, we are given a series of inputs of Correlation Clustering (called layers) over the common set $V$. The goal is then to find a clustering of $V$ that minimizes the $\ell_p$-norm ($p\geq 1$) of the disagreements vector, which is defined as the vector (with dimension equal to the number of layers), each element of which represents the disagreements of the clustering on the corresponding layer. For this generalization, we first design an $O(L\log n)$-approximation algorithm, where $L$ is the number of layers, based on the well-known region growing technique. We then study an important special case of our problem, namely the problem with the probability constraint. For this case, we first give an $(\alpha+2)$-approximation algorithm, where $\alpha$ is any possible approximation ratio for the single-layer counterpart. For instance, we can take $\alpha=2.5$ in general (Ailon et al., JACM '08) and $\alpha=1.73+\epsilon$ for the unweighted case (Cohen-Addad et al., FOCS '23). Furthermore, we design a $4$-approximation algorithm, which improves the above approximation ratio of $\alpha+2=4.5$ for the general probability-constraint case. Computational experiments using real-world datasets demonstrate the effectiveness of our proposed algorithms.
Query-Efficient Correlation Clustering with Noisy Oracle
Feb 02, 2024



We study a general clustering setting in which we have $n$ elements to be clustered, and we aim to perform as few queries as possible to an oracle that returns a noisy sample of the similarity between two elements. Our setting encompasses many application domains in which the similarity function is costly to compute and inherently noisy. We propose two novel formulations of online learning problems rooted in the paradigm of Pure Exploration in Combinatorial Multi-Armed Bandits (PE-CMAB): fixed confidence and fixed budget settings. For both settings, we design algorithms that combine a sampling strategy with a classic approximation algorithm for correlation clustering and study their theoretical guarantees. Our results are the first examples of polynomial-time algorithms that work for the case of PE-CMAB in which the underlying offline optimization problem is NP-hard.
Fairness in Algorithmic Recourse Through the Lens of Substantive Equality of Opportunity
Jan 29, 2024



Algorithmic recourse -- providing recommendations to those affected negatively by the outcome of an algorithmic system on how they can take action and change that outcome -- has gained attention as a means of giving persons agency in their interactions with artificial intelligence (AI) systems. Recent work has shown that even if an AI decision-making classifier is ``fair'' (according to some reasonable criteria), recourse itself may be unfair due to differences in the initial circumstances of individuals, compounding disparities for marginalized populations and requiring them to exert more effort than others. There is a need to define more methods and metrics for evaluating fairness in recourse that span a range of normative views of the world, and specifically those that take into account time. Time is a critical element in recourse because the longer it takes an individual to act, the more the setting may change due to model or data drift. This paper seeks to close this research gap by proposing two notions of fairness in recourse that are in normative alignment with substantive equality of opportunity, and that consider time. The first considers the (often repeated) effort individuals exert per successful recourse event, and the second considers time per successful recourse event. Building upon an agent-based framework for simulating recourse, this paper demonstrates how much effort is needed to overcome disparities in initial circumstances. We then proposes an intervention to improve the fairness of recourse by rewarding effort, and compare it to existing strategies.