 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecting software monitors for control-flow anomaly detection through large language models and conformance checking
Nov 14, 2025Context: Ensuring high levels of dependability in modern computer-based systems has become increasingly challenging due to their complexity. Although systems are validated at design time, their behavior can be different at run-time, possibly showing control-flow anomalies due to "unknown unknowns". Objective: We aim to detect control-flow anomalies through software monitoring, which verifies run-time behavior by logging software execution and detecting deviations from expected control flow. Methods: We propose a methodology to develop software monitors for control-flow anomaly detection through Large Language Models (LLMs) and conformance checking. The methodology builds on existing software development practices to maintain traditional V&V while providing an additional level of robustness and trustworthiness. It leverages LLMs to link design-time models and implementation code, automating source-code instrumentation. The resulting event logs are analyzed via conformance checking, an explainable and effective technique for control-flow anomaly detection. Results: We test the methodology on a case-study scenario from the European Railway Traffic Management System / European Train Control System (ERTMS/ETCS), which is a railway standard for modern interoperable railways. The results obtained from the ERTMS/ETCS case study demonstrate that LLM-based source-code instrumentation can achieve up to 84.775% control-flow coverage of the reference design-time process model, while the subsequent conformance checking-based anomaly detection reaches a peak performance of 96.610% F1-score and 93.515% AUC. Conclusion: Incorporating domain-specific knowledge to guide LLMs in source-code instrumentation significantly allowed obtaining reliable and quality software logs and enabled effective control-flow anomaly detection through conformance checking.
Towards explainable decision support using hybrid neural models for logistic terminal automation
Sep 10, 2025The integration of Deep Learning (DL) in System Dynamics (SD) modeling for transportation logistics offers significant advantages in scalability and predictive accuracy. However, these gains are often offset by the loss of explainability and causal reliability $-$ key requirements in critical decision-making systems. This paper presents a novel framework for interpretable-by-design neural system dynamics modeling that synergizes DL with techniques from Concept-Based Interpretability, Mechanistic Interpretability, and Causal Machine Learning. The proposed hybrid approach enables the construction of neural network models that operate on semantically meaningful and actionable variables, while retaining the causal grounding and transparency typical of traditional SD models. The framework is conceived to be applied to real-world case-studies from the EU-funded project AutoMoTIF, focusing on data-driven decision support, automation, and optimization of multimodal logistic terminals. We aim at showing how neuro-symbolic methods can bridge the gap between black-box predictive models and the need for critical decision support in complex dynamical environments within cyber-physical systems enabled by the industrial Internet-of-Things.
EFU: Enforcing Federated Unlearning via Functional Encryption
Aug 11, 2025Federated unlearning (FU) algorithms allow clients in federated settings to exercise their ''right to be forgotten'' by removing the influence of their data from a collaboratively trained model. Existing FU methods maintain data privacy by performing unlearning locally on the client-side and sending targeted updates to the server without exposing forgotten data; yet they often rely on server-side cooperation, revealing the client's intent and identity without enforcement guarantees - compromising autonomy and unlearning privacy. In this work, we propose EFU (Enforced Federated Unlearning), a cryptographically enforced FU framework that enables clients to initiate unlearning while concealing its occurrence from the server. Specifically, EFU leverages functional encryption to bind encrypted updates to specific aggregation functions, ensuring the server can neither perform unauthorized computations nor detect or skip unlearning requests. To further mask behavioral and parameter shifts in the aggregated model, we incorporate auxiliary unlearning losses based on adversarial examples and parameter importance regularization. Extensive experiments show that EFU achieves near-random accuracy on forgotten data while maintaining performance comparable to full retraining across datasets and neural architectures - all while concealing unlearning intent from the server. Furthermore, we demonstrate that EFU is agnostic to the underlying unlearning algorithm, enabling secure, function-hiding, and verifiable unlearning for any client-side FU mechanism that issues targeted updates.
Empirical Analysis of Asynchronous Federated Learning on Heterogeneous Devices: Efficiency, Fairness, and Privacy Trade-offs
May 11, 2025Device heterogeneity poses major challenges in Federated Learning (FL), where resource-constrained clients slow down synchronous schemes that wait for all updates before aggregation. Asynchronous FL addresses this by incorporating updates as they arrive, substantially improving efficiency. While its efficiency gains are well recognized, its privacy costs remain largely unexplored, particularly for high-end devices that contribute updates more frequently, increasing their cumulative privacy exposure. This paper presents the first comprehensive analysis of the efficiency-fairness-privacy trade-off in synchronous vs. asynchronous FL under realistic device heterogeneity. We empirically compare FedAvg and staleness-aware FedAsync using a physical testbed of five edge devices spanning diverse hardware tiers, integrating Local Differential Privacy (LDP) and the Moments Accountant to quantify per-client privacy loss. Using Speech Emotion Recognition (SER) as a privacy-critical benchmark, we show that FedAsync achieves up to 10x faster convergence but exacerbates fairness and privacy disparities: high-end devices contribute 6-10x more updates and incur up to 5x higher privacy loss, while low-end devices suffer amplified accuracy degradation due to infrequent, stale, and noise-perturbed updates. These findings motivate the need for adaptive FL protocols that jointly optimize aggregation and privacy mechanisms based on client capacity and participation dynamics, moving beyond static, one-size-fits-all solutions.
EncCluster: Scalable Functional Encryption in Federated Learning through Weight Clustering and Probabilistic Filters
Jun 13, 2024Federated Learning (FL) enables model training across decentralized devices by communicating solely local model updates to an aggregation server. Although such limited data sharing makes FL more secure than centralized approached, FL remains vulnerable to inference attacks during model update transmissions. Existing secure aggregation approaches rely on differential privacy or cryptographic schemes like Functional Encryption (FE) to safeguard individual client data. However, such strategies can reduce performance or introduce unacceptable computational and communication overheads on clients running on edge devices with limited resources. In this work, we present EncCluster, a novel method that integrates model compression through weight clustering with recent decentralized FE and privacy-enhancing data encoding using probabilistic filters to deliver strong privacy guarantees in FL without affecting model performance or adding unnecessary burdens to clients. We performed a comprehensive evaluation, spanning various datasets and architectures, to demonstrate EncCluster's scalability across encryption levels. Our findings reveal that EncCluster significantly reduces communication costs - below even conventional FedAvg - and accelerates encryption by more than four times over all baselines; at the same time, it maintains high model accuracy and enhanced privacy assurances.
Safe Road-Crossing by Autonomous Wheelchairs: a Novel Dataset and its Experimental Evaluation
Mar 13, 2024Safe road-crossing by self-driving vehicles is a crucial problem to address in smart-cities. In this paper, we introduce a multi-sensor fusion approach to support road-crossing decisions in a system composed by an autonomous wheelchair and a flying drone featuring a robust sensory system made of diverse and redundant components. To that aim, we designed an analytical danger function based on explainable physical conditions evaluated by single sensors, including those using machine learning and artificial vision. As a proof-of-concept, we provide an experimental evaluation in a laboratory environment, showing the advantages of using multiple sensors, which can improve decision accuracy and effectively support safety assessment. We made the dataset available to the scientific community for further experimentation. The work has been developed in the context of an European project named REXASI-PRO, which aims to develop trustworthy artificial intelligence for social navigation of people with reduced mobility.
Obstacles in Fully Automatic Program Repair: A survey
Nov 05, 2020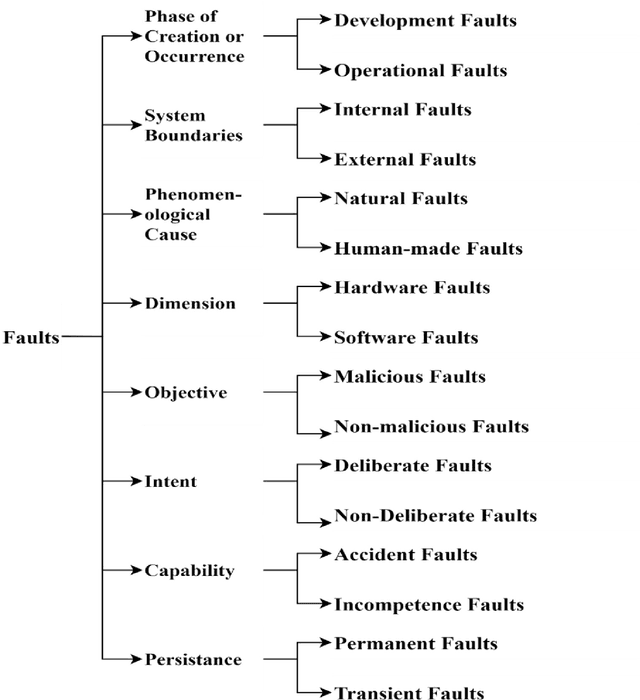

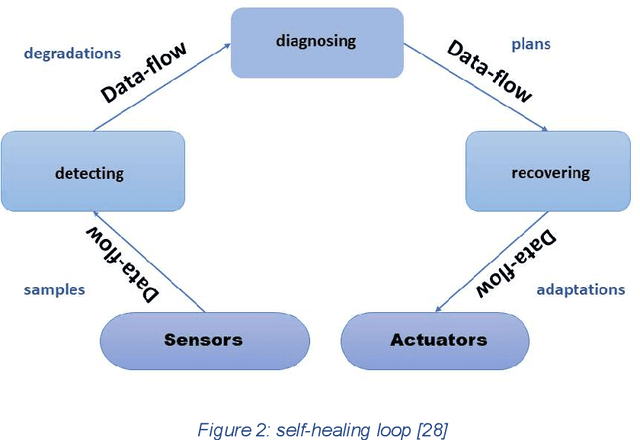
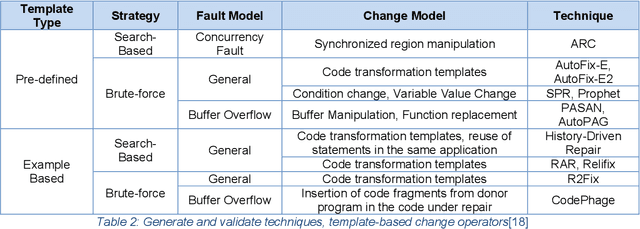
The current article is an interdisciplinary attempt to decipher automatic program repair processes. The review is done by the manner typical to human science known as diffraction. We attempt to spot a gap in the literature of self-healing and self-repair operations and further investigate the approaches that would enable us to tackle the problems we face. As a conclusion, we suggest a shift in the current approach to automatic program repair operations in order to attain our goals. The emphasis of this review is to achieve full automation. Several obstacles are shortly mentioned in the current essay but the main shortage that is covered is the overfitting obstacle, and this particular problem is investigated in the stream that is related to full automation of the repair process.