 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Software Kernels and Hardware Extensions for Efficient Sparse Deep Neural Networks on Microcontrollers
Mar 08, 2025The acceleration of pruned Deep Neural Networks (DNNs) on edge devices such as Microcontrollers (MCUs) is a challenging task, given the tight area- and power-constraints of these devices. In this work, we propose a three-fold contribution to address this problem. First, we design a set of optimized software kernels for N:M pruned layers, targeting ultra-low-power, multicore RISC-V MCUs, which are up to 2.1x and 3.4x faster than their dense counterparts at 1:8 and 1:16 sparsity, respectively. Then, we implement a lightweight Instruction-Set Architecture (ISA) extension to accelerate the indirect load and non-zero indices decompression operations required by our kernels, obtaining up to 1.9x extra speedup, at the cost of a 5% area overhead. Lastly, we extend an open-source DNN compiler to utilize our sparse kernels for complete networks, showing speedups of 3.21x and 1.81x on a ResNet18 and a Vision Transformer (ViT), with less than 1.5% accuracy drop compared to a dense baseline.
MATCH: Model-Aware TVM-based Compilation for Heterogeneous Edge Devices
Oct 11, 2024



Streamlining the deployment of Deep Neural Networks (DNNs) on heterogeneous edge platforms, coupling within the same micro-controller unit (MCU) instruction processors and hardware accelerators for tensor computations, is becoming one of the crucial challenges of the TinyML field. The best-performing DNN compilation toolchains are usually deeply customized for a single MCU family, and porting to a different heterogeneous MCU family implies labor-intensive re-development of almost the entire compiler. On the opposite side, retargetable toolchains, such as TVM, fail to exploit the capabilities of custom accelerators, resulting in the generation of general but unoptimized code. To overcome this duality, we introduce MATCH, a novel TVM-based DNN deployment framework designed for easy agile retargeting across different MCU processors and accelerators, thanks to a customizable model-based hardware abstraction. We show that a general and retargetable mapping framework enhanced with hardware cost models can compete with and even outperform custom toolchains on diverse targets while only needing the definition of an abstract hardware model and a SoC-specific API. We tested MATCH on two state-of-the-art heterogeneous MCUs, GAP9 and DIANA. On the four DNN models of the MLPerf Tiny suite MATCH reduces inference latency by up to 60.88 times on DIANA, compared to using the plain TVM, thanks to the exploitation of the on-board HW accelerator. Compared to HTVM, a fully customized toolchain for DIANA, we still reduce the latency by 16.94%. On GAP9, using the same benchmarks, we improve the latency by 2.15 times compared to the dedicated DORY compiler, thanks to our heterogeneous DNN mapping approach that synergically exploits the DNN accelerator and the eight-cores cluster available on board.
Machine Learning-based feasibility estimation of digital blocks in BCD technology
Oct 10, 2024



Analog-on-Top Mixed Signal (AMS) Integrated Circuit (IC) design is a time-consuming process predominantly carried out by hand. Within this flow, usually, some area is reserved by the top-level integrator for the placement of digital blocks. Specific features of the area, such as size and shape, have a relevant impact on the possibility of implementing the digital logic with the required functionality. We present a Machine Learning (ML)-based evaluation methodology for predicting the feasibility of digital implementation using a set of high-level features. This approach aims to avoid time-consuming Place-and-Route trials, enabling rapid feedback between Digital and Analog Back-End designers during top-level placement.
Accelerating Depthwise Separable Convolutions on Ultra-Low-Power Devices
Jun 18, 2024Depthwise separable convolutions are a fundamental component in efficient Deep Neural Networks, as they reduce the number of parameters and operations compared to traditional convolutions while maintaining comparable accuracy. However, their low data reuse opportunities make deploying them notoriously difficult. In this work, we perform an extensive exploration of alternatives to fuse the depthwise and pointwise kernels that constitute the separable convolutional block. Our approach aims to minimize time-consuming memory transfers by combining different data layouts. When targeting a commercial ultra-low-power device with a three-level memory hierarchy, the GreenWaves GAP8 SoC, we reduce the latency of end-to-end network execution by up to 11.40%. Furthermore, our kernels reduce activation data movements between L2 and L1 memories by up to 52.97%.
Optimized Deployment of Deep Neural Networks for Visual Pose Estimation on Nano-drones
Feb 23, 2024Miniaturized autonomous unmanned aerial vehicles (UAVs) are gaining popularity due to their small size, enabling new tasks such as indoor navigation or people monitoring. Nonetheless, their size and simple electronics pose severe challenges in implementing advanced onboard intelligence. This work proposes a new automatic optimization pipeline for visual pose estimation tasks using Deep Neural Networks (DNNs). The pipeline leverages two different Neural Architecture Search (NAS) algorithms to pursue a vast complexity-driven exploration in the DNNs' architectural space. The obtained networks are then deployed on an off-the-shelf nano-drone equipped with a parallel ultra-low power System-on-Chip leveraging a set of novel software kernels for the efficient fused execution of critical DNN layer sequences. Our results improve the state-of-the-art reducing inference latency by up to 3.22x at iso-error.
HW-SW Optimization of DNNs for Privacy-preserving People Counting on Low-resolution Infrared Arrays
Feb 02, 2024



Low-resolution infrared (IR) array sensors enable people counting applications such as monitoring the occupancy of spaces and people flows while preserving privacy and minimizing energy consumption. Deep Neural Networks (DNNs) have been shown to be well-suited to process these sensor data in an accurate and efficient manner. Nevertheless, the space of DNNs' architectures is huge and its manual exploration is burdensome and often leads to sub-optimal solutions. To overcome this problem, in this work, we propose a highly automated full-stack optimization flow for DNNs that goes from neural architecture search, mixed-precision quantization, and post-processing, down to the realization of a new smart sensor prototype, including a Microcontroller with a customized instruction set. Integrating these cross-layer optimizations, we obtain a large set of Pareto-optimal solutions in the 3D-space of energy, memory, and accuracy. Deploying such solutions on our hardware platform, we improve the state-of-the-art achieving up to 4.2x model size reduction, 23.8x code size reduction, and 15.38x energy reduction at iso-accuracy.
Model-Driven Dataset Generation for Data-Driven Battery SOH Models
Jan 10, 2024



Estimating the State of Health (SOH) of batteries is crucial for ensuring the reliable operation of battery systems. Since there is no practical way to instantaneously measure it at run time, a model is required for its estimation. Recently, several data-driven SOH models have been proposed, whose accuracy heavily relies on the quality of the datasets used for their training. Since these datasets are obtained from measurements, they are limited in the variety of the charge/discharge profiles. To address this scarcity issue, we propose generating datasets by simulating a traditional battery model (e.g., a circuit-equivalent one). The primary advantage of this approach is the ability to use a simulatable battery model to evaluate a potentially infinite number of workload profiles for training the data-driven model. Furthermore, this general concept can be applied using any simulatable battery model, providing a fine spectrum of accuracy/complexity tradeoffs. Our results indicate that using simulated data achieves reasonable accuracy in SOH estimation, with a 7.2% error relative to the simulated model, in exchange for a 27X memory reduction and a =2000X speedup.
Dynamic Decision Tree Ensembles for Energy-Efficient Inference on IoT Edge Nodes
Jun 16, 2023



With the increasing popularity of Internet of Things (IoT) devices, there is a growing need for energy-efficient Machine Learning (ML) models that can run on constrained edge nodes. Decision tree ensembles, such as Random Forests (RFs) and Gradient Boosting (GBTs), are particularly suited for this task, given their relatively low complexity compared to other alternatives. However, their inference time and energy costs are still significant for edge hardware. Given that said costs grow linearly with the ensemble size, this paper proposes the use of dynamic ensembles, that adjust the number of executed trees based both on a latency/energy target and on the complexity of the processed input, to trade-off computational cost and accuracy. We focus on deploying these algorithms on multi-core low-power IoT devices, designing a tool that automatically converts a Python ensemble into optimized C code, and exploring several optimizations that account for the available parallelism and memory hierarchy. We extensively benchmark both static and dynamic RFs and GBTs on three state-of-the-art IoT-relevant datasets, using an 8-core ultra-lowpower System-on-Chip (SoC), GAP8, as the target platform. Thanks to the proposed early-stopping mechanisms, we achieve an energy reduction of up to 37.9% with respect to static GBTs (8.82 uJ vs 14.20 uJ per inference) and 41.7% with respect to static RFs (2.86 uJ vs 4.90 uJ per inference), without losing accuracy compared to the static model.
Efficient Deep Learning Models for Privacy-preserving People Counting on Low-resolution Infrared Arrays
Apr 12, 2023



Ultra-low-resolution Infrared (IR) array sensors offer a low-cost, energy-efficient, and privacy-preserving solution for people counting, with applications such as occupancy monitoring. Previous work has shown that Deep Learning (DL) can yield superior performance on this task. However, the literature was missing an extensive comparative analysis of various efficient DL architectures for IR array-based people counting, that considers not only their accuracy, but also the cost of deploying them on memory- and energy-constrained Internet of Things (IoT) edge nodes. In this work, we address this need by comparing 6 different DL architectures on a novel dataset composed of IR images collected from a commercial 8x8 array, which we made openly available. With a wide architectural exploration of each model type, we obtain a rich set of Pareto-optimal solutions, spanning cross-validated balanced accuracy scores in the 55.70-82.70% range. When deployed on a commercial Microcontroller (MCU) by STMicroelectronics, the STM32L4A6ZG, these models occupy 0.41-9.28kB of memory, and require 1.10-7.74ms per inference, while consuming 17.18-120.43 $\mu$J of energy. Our models are significantly more accurate than a previous deterministic method (up to +39.9%), while being up to 3.53x faster and more energy efficient. Further, our models' accuracy is comparable to state-of-the-art DL solutions on similar resolution sensors, despite a much lower complexity. All our models enable continuous, real-time inference on a MCU-based IoT node, with years of autonomous operation without battery recharging.
Human Activity Recognition on Microcontrollers with Quantized and Adaptive Deep Neural Networks
Sep 02, 2022
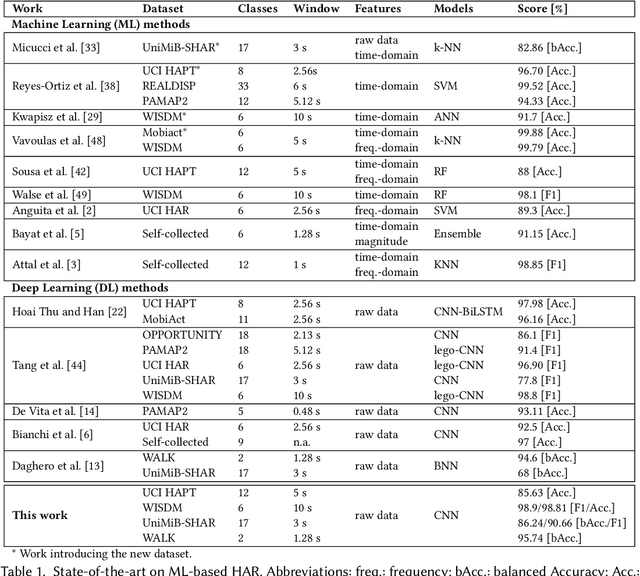
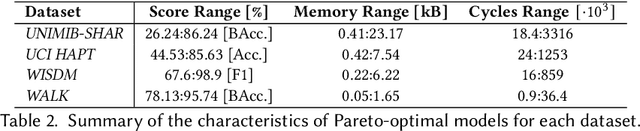
Human Activity Recognition (HAR) based on inertial data is an increasingly diffused task on embedded devices, from smartphones to ultra low-power sensors. Due to the high computational complexity of deep learning models, most embedded HAR systems are based on simple and not-so-accurate classic machine learning algorithms. This work bridges the gap between on-device HAR and deep learning, proposing a set of efficient one-dimensional Convolutional Neural Networks (CNNs) deployable on general purpose microcontrollers (MCUs). Our CNNs are obtained combining hyper-parameters optimization with sub-byte and mixed-precision quantization, to find good trade-offs between classification results and memory occupation. Moreover, we also leverage adaptive inference as an orthogonal optimization to tune the inference complexity at runtime based on the processed input, hence producing a more flexible HAR system. With experiments on four datasets, and targeting an ultra-low-power RISC-V MCU, we show that (i) We are able to obtain a rich set of Pareto-optimal CNNs for HAR, spanning more than 1 order of magnitude in terms of memory, latency and energy consumption; (ii) Thanks to adaptive inference, we can derive >20 runtime operating modes starting from a single CNN, differing by up to 10% in classification scores and by more than 3x in inference complexity, with a limited memory overhead; (iii) on three of the four benchmarks, we outperform all previous deep learning methods, reducing the memory occupation by more than 100x. The few methods that obtain better performance (both shallow and deep) are not compatible with MCU deployment. (iv) All our CNNs are compatible with real-time on-device HAR with an inference latency <16ms. Their memory occupation varies in 0.05-23.17 kB, and their energy consumption in 0.005 and 61.59 uJ, allowing years of continuous operation on a small battery supply.