 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanatory Model Monitoring to Understand the Effects of Feature Shifts on Performance
Aug 24, 2024



Monitoring and maintaining machine learning models are among the most critical challenges in translating recent advances in the field into real-world applications. However, current monitoring methods lack the capability of provide actionable insights answering the question of why the performance of a particular model really degraded. In this work, we propose a novel approach to explain the behavior of a black-box model under feature shifts by attributing an estimated performance change to interpretable input characteristics. We refer to our method that combines concepts from Optimal Transport and Shapley Values as Explanatory Performance Estimation (XPE). We analyze the underlying assumptions and demonstrate the superiority of our approach over several baselines on different data sets across various data modalities such as images, audio, and tabular data. We also indicate how the generated results can lead to valuable insights, enabling explanatory model monitoring by revealing potential root causes for model deterioration and guiding toward actionable countermeasures.
How to Leverage Predictive Uncertainty Estimates for Reducing Catastrophic Forgetting in Online Continual Learning
Jul 10, 2024



Many real-world applications require machine-learning models to be able to deal with non-stationary data distributions and thus learn autonomously over an extended period of time, often in an online setting. One of the main challenges in this scenario is the so-called catastrophic forgetting (CF) for which the learning model tends to focus on the most recent tasks while experiencing predictive degradation on older ones. In the online setting, the most effective solutions employ a fixed-size memory buffer to store old samples used for replay when training on new tasks. Many approaches have been presented to tackle this problem. However, it is not clear how predictive uncertainty information for memory management can be leveraged in the most effective manner and conflicting strategies are proposed to populate the memory. Are the easiest-to-forget or the easiest-to-remember samples more effective in combating CF? Starting from the intuition that predictive uncertainty provides an idea of the samples' location in the decision space, this work presents an in-depth analysis of different uncertainty estimates and strategies for populating the memory. The investigation provides a better understanding of the characteristics data points should have for alleviating CF. Then, we propose an alternative method for estimating predictive uncertainty via the generalised variance induced by the negative log-likelihood. Finally, we demonstrate that the use of predictive uncertainty measures helps in reducing CF in different settings.
Provably Better Explanations with Optimized Aggregation of Feature Attributions
Jun 07, 2024Using feature attributions for post-hoc explanations is a common practice to understand and verify the predictions of opaque machine learning models. Despite the numerous techniques available, individual methods often produce inconsistent and unstable results, putting their overall reliability into question. In this work, we aim to systematically improve the quality of feature attributions by combining multiple explanations across distinct methods or their variations. For this purpose, we propose a novel approach to derive optimal convex combinations of feature attributions that yield provable improvements of desired quality criteria such as robustness or faithfulness to the model behavior. Through extensive experiments involving various model architectures and popular feature attribution techniques, we demonstrate that our combination strategy consistently outperforms individual methods and existing baselines.
Federated Continual Learning Goes Online: Leveraging Uncertainty for Modality-Agnostic Class-Incremental Learning
May 29, 2024



Given the ability to model more realistic and dynamic problems, Federated Continual Learning (FCL) has been increasingly investigated recently. A well-known problem encountered in this setting is the so-called catastrophic forgetting, for which the learning model is inclined to focus on more recent tasks while forgetting the previously learned knowledge. The majority of the current approaches in FCL propose generative-based solutions to solve said problem. However, this setting requires multiple training epochs over the data, implying an offline setting where datasets are stored locally and remain unchanged over time. Furthermore, the proposed solutions are tailored for vision tasks solely. To overcome these limitations, we propose a new modality-agnostic approach to deal with the online scenario where new data arrive in streams of mini-batches that can only be processed once. To solve catastrophic forgetting, we propose an uncertainty-aware memory-based approach. In particular, we suggest using an estimator based on the Bregman Information (BI) to compute the model's variance at the sample level. Through measures of predictive uncertainty, we retrieve samples with specific characteristics, and - by retraining the model on such samples - we demonstrate the potential of this approach to reduce the forgetting effect in realistic settings.
DomainLab: A modular Python package for domain generalization in deep learning
Mar 21, 2024
Poor generalization performance caused by distribution shifts in unseen domains often hinders the trustworthy deployment of deep neural networks. Many domain generalization techniques address this problem by adding a domain invariant regularization loss terms during training. However, there is a lack of modular software that allows users to combine the advantages of different methods with minimal effort for reproducibility. DomainLab is a modular Python package for training user specified neural networks with composable regularization loss terms. Its decoupled design allows the separation of neural networks from regularization loss construction. Hierarchical combinations of neural networks, different domain generalization methods, and associated hyperparameters, can all be specified together with other experimental setup in a single configuration file. Hierarchical combinations of neural networks, different domain generalization methods, and associated hyperparameters, can all be specified together with other experimental setup in a single configuration file. In addition, DomainLab offers powerful benchmarking functionality to evaluate the generalization performance of neural networks in out-of-distribution data. The package supports running the specified benchmark on an HPC cluster or on a standalone machine. The package is well tested with over 95 percent coverage and well documented. From the user perspective, it is closed to modification but open to extension. The package is under the MIT license, and its source code, tutorial and documentation can be found at https://github.com/marrlab/DomainLab.
Consistent and Asymptotically Unbiased Estimation of Proper Calibration Errors
Dec 14, 2023



Proper scoring rules evaluate the quality of probabilistic predictions, playing an essential role in the pursuit of accurate and well-calibrated models. Every proper score decomposes into two fundamental components -- proper calibration error and refinement -- utilizing a Bregman divergence. While uncertainty calibration has gained significant attention, current literature lacks a general estimator for these quantities with known statistical properties. To address this gap, we propose a method that allows consistent, and asymptotically unbiased estimation of all proper calibration errors and refinement terms. In particular, we introduce Kullback--Leibler calibration error, induced by the commonly used cross-entropy loss. As part of our results, we prove the relation between refinement and f-divergences, which implies information monotonicity in neural networks, regardless of which proper scoring rule is optimized. Our experiments validate empirically the claimed properties of the proposed estimator and suggest that the selection of a post-hoc calibration method should be determined by the particular calibration error of interest.
A Bias-Variance-Covariance Decomposition of Kernel Scores for Generative Models
Oct 09, 2023



Generative models, like large language models, are becoming increasingly relevant in our daily lives, yet a theoretical framework to assess their generalization behavior and uncertainty does not exist. Particularly, the problem of uncertainty estimation is commonly solved in an ad-hoc manner and task dependent. For example, natural language approaches cannot be transferred to image generation. In this paper we introduce the first bias-variance-covariance decomposition for kernel scores and their associated entropy. We propose unbiased and consistent estimators for each quantity which only require generated samples but not the underlying model itself. As an application, we offer a generalization evaluation of diffusion models and discover how mode collapse of minority groups is a contrary phenomenon to overfitting. Further, we demonstrate that variance and predictive kernel entropy are viable measures of uncertainty for image, audio, and language generation. Specifically, our approach for uncertainty estimation is more predictive of performance on CoQA and TriviaQA question answering datasets than existing baselines and can also be applied to closed-source models.
Application-driven Validation of Posteriors in Inverse Problems
Sep 18, 2023



Current deep learning-based solutions for image analysis tasks are commonly incapable of handling problems to which multiple different plausible solutions exist. In response, posterior-based methods such as conditional Diffusion Models and Invertible Neural Networks have emerged; however, their translation is hampered by a lack of research on adequate validation. In other words, the way progress is measured often does not reflect the needs of the driving practical application. Closing this gap in the literature, we present the first systematic framework for the application-driven validation of posterior-based methods in inverse problems. As a methodological novelty, it adopts key principles from the field of object detection validation, which has a long history of addressing the question of how to locate and match multiple object instances in an image. Treating modes as instances enables us to perform mode-centric validation, using well-interpretable metrics from the application perspective. We demonstrate the value of our framework through instantiations for a synthetic toy example and two medical vision use cases: pose estimation in surgery and imaging-based quantification of functional tissue parameters for diagnostics. Our framework offers key advantages over common approaches to posterior validation in all three examples and could thus revolutionize performance assessment in inverse problems.
Encoding Domain Knowledge in Multi-view Latent Variable Models: A Bayesian Approach with Structured Sparsity
Apr 13, 2022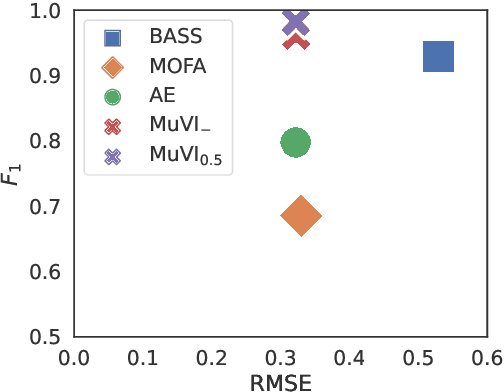
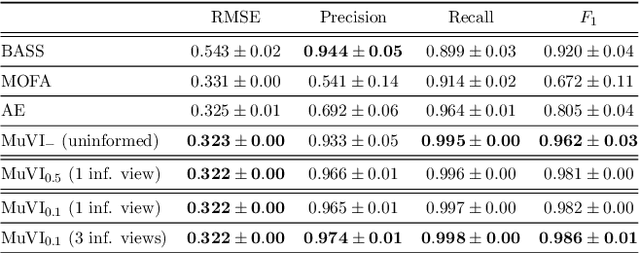
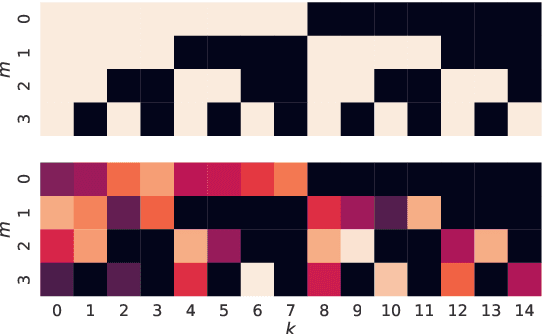
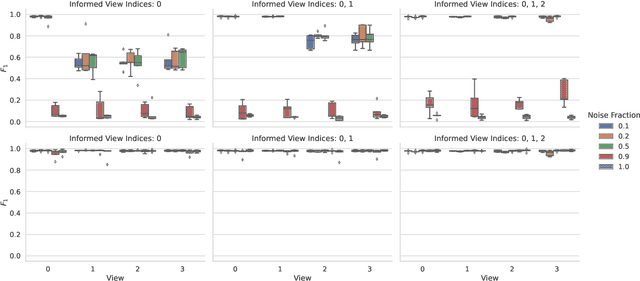
Many real-world systems are described not only by data from a single source but via multiple data views. For example, in genomic medicine, a patient can be described by data from different molecular layers. This raises the need for multi-view models that are able to disentangle variation within and across data views in an interpretable manner. Latent variable models with structured sparsity are a commonly used tool to address this modeling task but interpretability is cumbersome since it requires a direct inspection and interpretation of each factor via a specialized domain expert. Here, we propose MuVI, a novel approach for domain-informed multi-view latent variable models, facilitating the analysis of multi-view data in an inherently explainable manner. We demonstrate that our model (i) is able to integrate noisy domain expertise in form of feature sets, (ii) is robust to noise in the encoded domain knowledge, (iii) results in identifiable factors and (iv) is able to infer interpretable and biologically meaningful axes of variation in a real-world multi-view dataset of cancer patients.
Trustworthy Deep Learning via Proper Calibration Errors: A Unifying Approach for Quantifying the Reliability of Predictive Uncertainty
Mar 15, 2022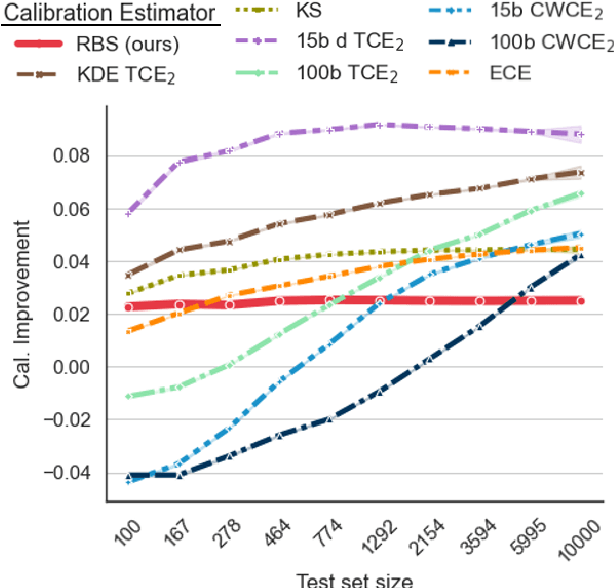
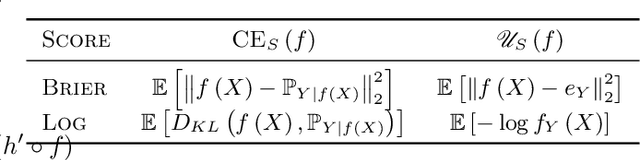
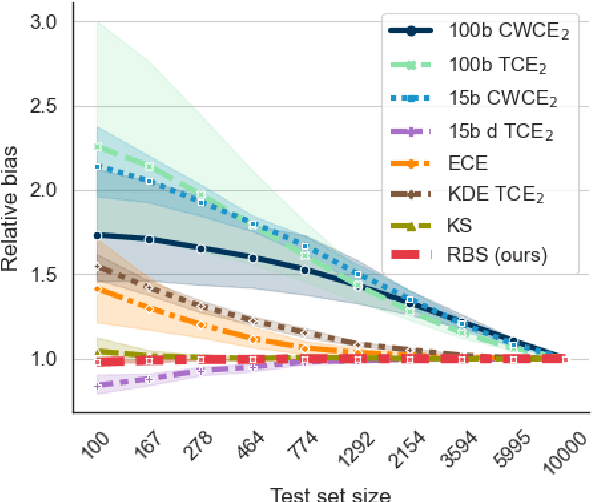
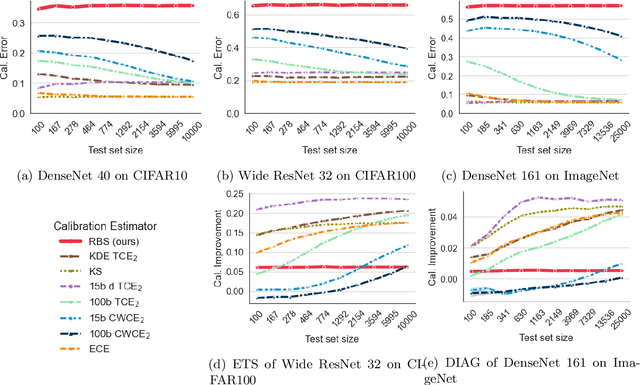
With model trustworthiness being crucial for sensitive real-world applications, practitioners are putting more and more focus on evaluating deep neural networks in terms of uncertainty calibration. Calibration errors are designed to quantify the reliability of probabilistic predictions but their estimators are usually biased and inconsistent. In this work, we introduce the framework of proper calibration errors, which relates every calibration error to a proper score and provides a respective upper bound with optimal estimation properties. This upper bound allows us to reliably estimate the calibration improvement of any injective recalibration method in an unbiased manner. We demonstrate that, in contrast to our approach, the most commonly used estimators are substantially biased with respect to the true improvement of recalibration methods.