 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Implicit Sinkhorn Differentiation
May 13, 2022
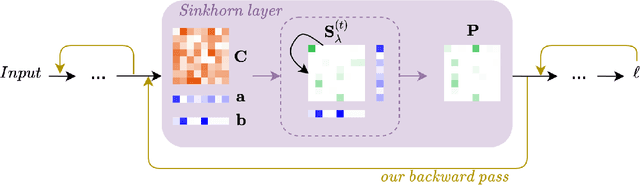
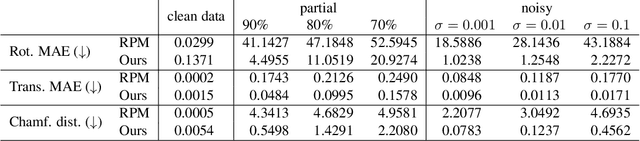
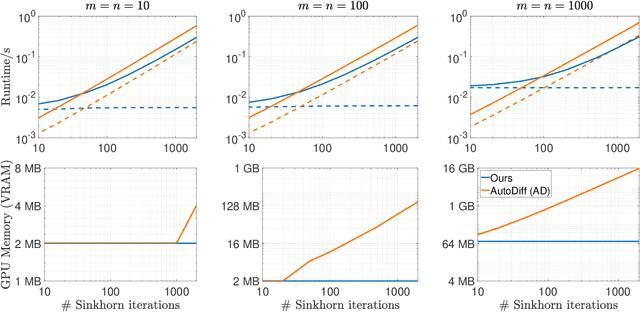
The Sinkhorn operator has recently experienced a surge of popularity in computer vision and related fields. One major reason is its ease of integration into deep learning frameworks. To allow for an efficient training of respective neural networks, we propose an algorithm that obtains analytical gradients of a Sinkhorn layer via implicit differentiation. In comparison to prior work, our framework is based on the most general formulation of the Sinkhorn operator. It allows for any type of loss function, while both the target capacities and cost matrices are differentiated jointly. We further construct error bounds of the resulting algorithm for approximate inputs. Finally, we demonstrate that for a number of applications, simply replacing automatic differentiation with our algorithm directly improves the stability and accuracy of the obtained gradients. Moreover, we show that it is computationally more efficient, particularly when resources like GPU memory are scarce.
Neural Implicit Representations for Physical Parameter Inference from a Single Video
Apr 29, 2022
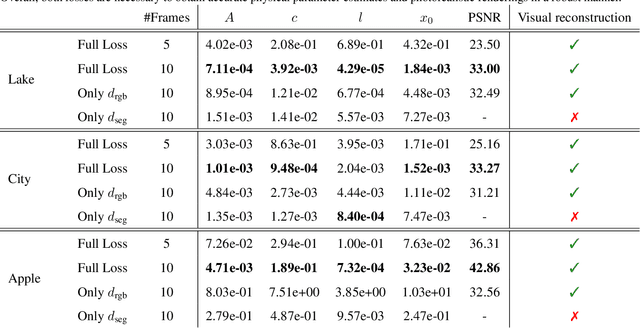
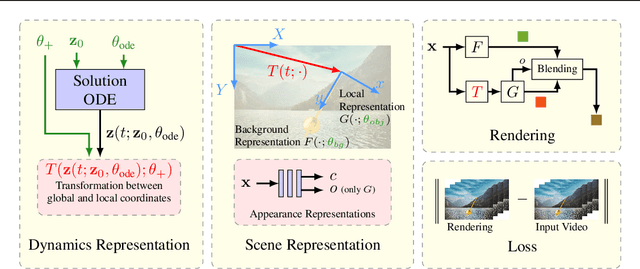

Neural networks have recently been used to analyze diverse physical systems and to identify the underlying dynamics. While existing methods achieve impressive results, they are limited by their strong demand for training data and their weak generalization abilities to out-of-distribution data. To overcome these limitations, in this work we propose to combine neural implicit representations for appearance modeling with neural ordinary differential equations (ODEs) for modelling physical phenomena to obtain a dynamic scene representation that can be identified directly from visual observations. Our proposed model combines several unique advantages: (i) Contrary to existing approaches that require large training datasets, we are able to identify physical parameters from only a single video. (ii) The use of neural implicit representations enables the processing of high-resolution videos and the synthesis of photo-realistic images. (iii) The embedded neural ODE has a known parametric form that allows for the identification of interpretable physical parameters, and (iv) long-term prediction in state space. (v) Furthermore, the photo-realistic rendering of novel scenes with modified physical parameters becomes possible.
A Scalable Combinatorial Solver for Elastic Geometrically Consistent 3D Shape Matching
Apr 27, 2022
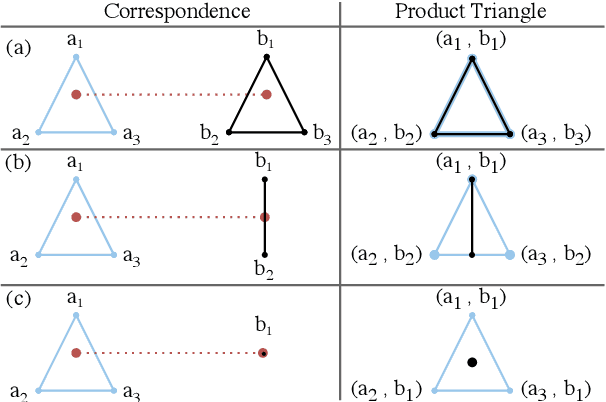
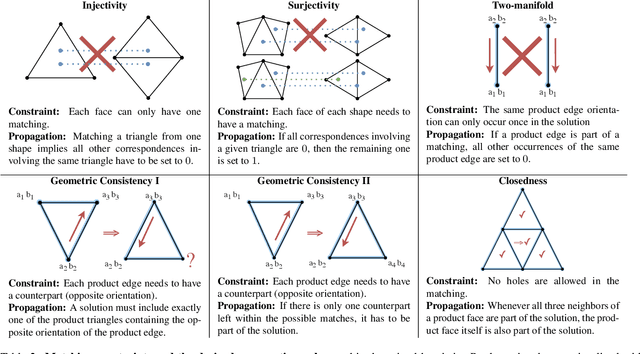
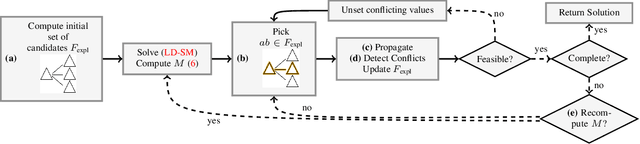
We present a scalable combinatorial algorithm for globally optimizing over the space of geometrically consistent mappings between 3D shapes. We use the mathematically elegant formalism proposed by Windheuser et al. (ICCV 2011) where 3D shape matching was formulated as an integer linear program over the space of orientation-preserving diffeomorphisms. Until now, the resulting formulation had limited practical applicability due to its complicated constraint structure and its large size. We propose a novel primal heuristic coupled with a Lagrange dual problem that is several orders of magnitudes faster compared to previous solvers. This allows us to handle shapes with substantially more triangles than previously solvable. We demonstrate compelling results on diverse datasets, and, even showcase that we can address the challenging setting of matching two partial shapes without availability of complete shapes. Our code is publicly available at http://github.com/paul0noah/sm-comb .
The Probabilistic Normal Epipolar Constraint for Frame-To-Frame Rotation Optimization under Uncertain Feature Positions
Apr 05, 2022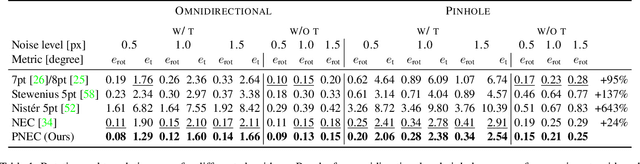

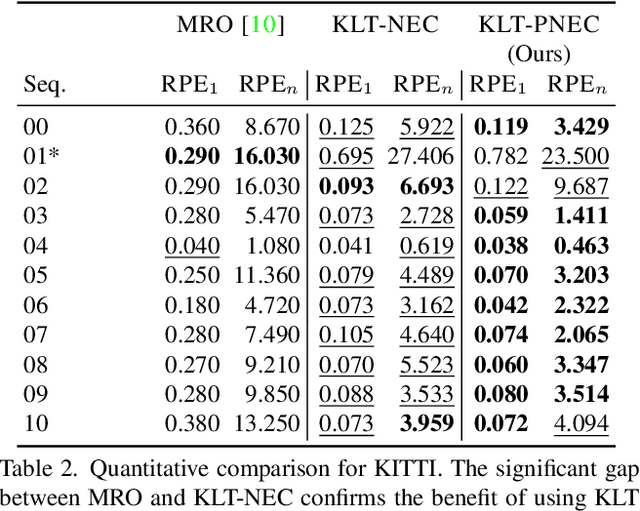
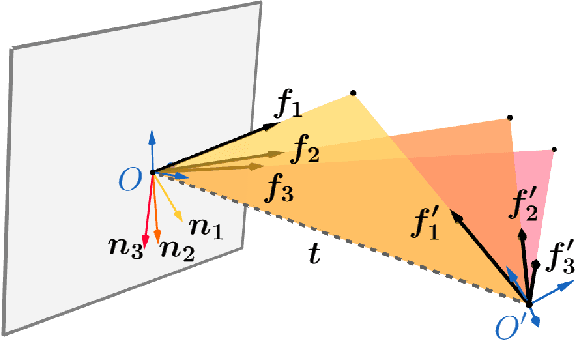
The estimation of the relative pose of two camera views is a fundamental problem in computer vision. Kneip et al. proposed to solve this problem by introducing the normal epipolar constraint (NEC). However, their approach does not take into account uncertainties, so that the accuracy of the estimated relative pose is highly dependent on accurate feature positions in the target frame. In this work, we introduce the probabilistic normal epipolar constraint (PNEC) that overcomes this limitation by accounting for anisotropic and inhomogeneous uncertainties in the feature positions. To this end, we propose a novel objective function, along with an efficient optimization scheme that effectively minimizes our objective while maintaining real-time performance. In experiments on synthetic data, we demonstrate that the novel PNEC yields more accurate rotation estimates than the original NEC and several popular relative rotation estimation algorithms. Furthermore, we integrate the proposed method into a state-of-the-art monocular rotation-only odometry system and achieve consistently improved results for the real-world KITTI dataset.
HDSDF: Hybrid Directional and Signed Distance Functions for Fast Inverse Rendering
Mar 30, 2022

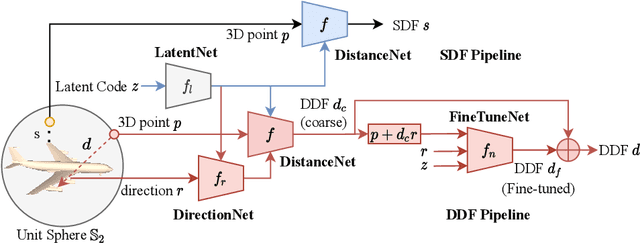
Implicit neural representations of 3D shapes form strong priors that are useful for various applications, such as single and multiple view 3D reconstruction. A downside of existing neural representations is that they require multiple network evaluations for rendering, which leads to high computational costs. This limitation forms a bottleneck particularly in the context of inverse problems, such as image-based 3D reconstruction. To address this issue, in this paper (i) we propose a novel hybrid 3D object representation based on a signed distance function (SDF) that we augment with a directional distance function (DDF), so that we can predict distances to the object surface from any point on a sphere enclosing the object. Moreover, (ii) using the proposed hybrid representation we address the multi-view consistency problem common in existing DDF representations. We evaluate our novel hybrid representation on the task of single-view depth reconstruction and show that our method is several times faster compared to competing methods, while at the same time achieving better reconstruction accuracy.
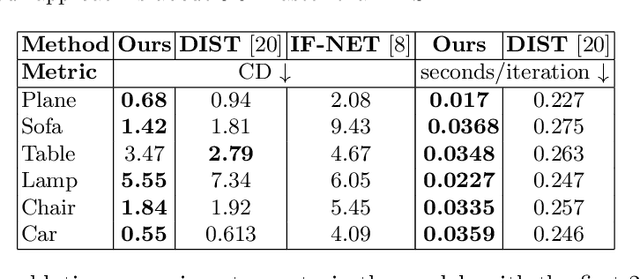
Shortest Paths in Graphs with Matrix-Valued Edges: Concepts, Algorithm and Application to 3D Multi-Shape Analysis
Dec 08, 2021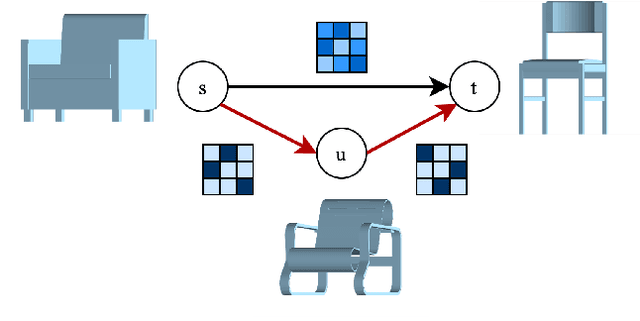
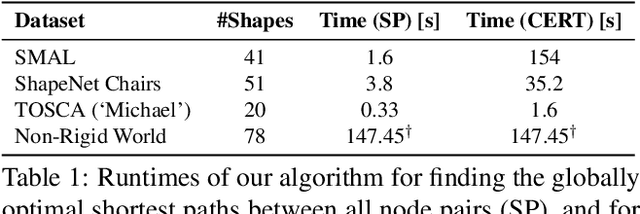
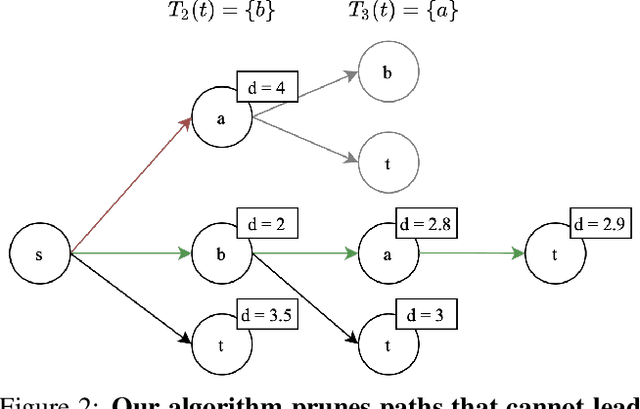
Finding shortest paths in a graph is relevant for numerous problems in computer vision and graphics, including image segmentation, shape matching, or the computation of geodesic distances on discrete surfaces. Traditionally, the concept of a shortest path is considered for graphs with scalar edge weights, which makes it possible to compute the length of a path by adding up the individual edge weights. Yet, graphs with scalar edge weights are severely limited in their expressivity, since oftentimes edges are used to encode significantly more complex interrelations. In this work we compensate for this modelling limitation and introduce the novel graph-theoretic concept of a shortest path in a graph with matrix-valued edges. To this end, we define a meaningful way for quantifying the path length for matrix-valued edges, and we propose a simple yet effective algorithm to compute the respective shortest path. While our formalism is universal and thus applicable to a wide range of settings in vision, graphics and beyond, we focus on demonstrating its merits in the context of 3D multi-shape analysis.
Convex Joint Graph Matching and Clustering via Semidefinite Relaxations
Oct 21, 2021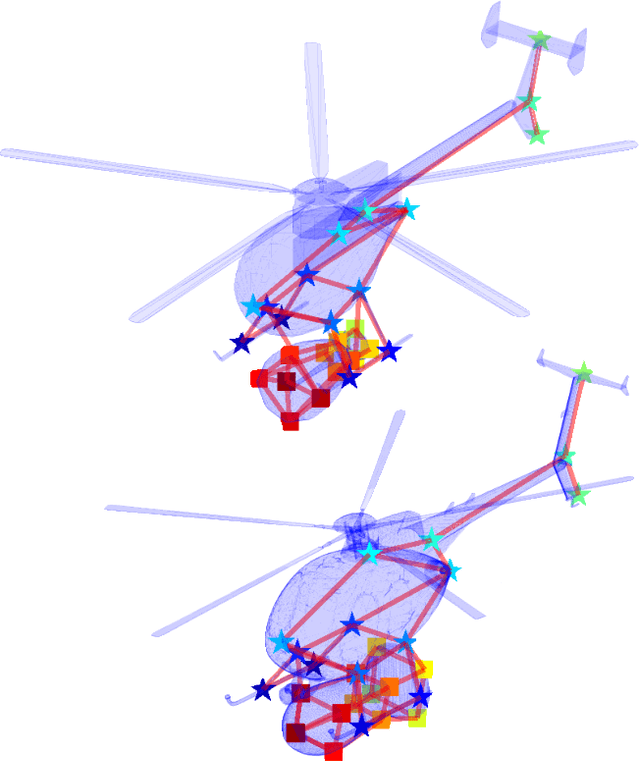
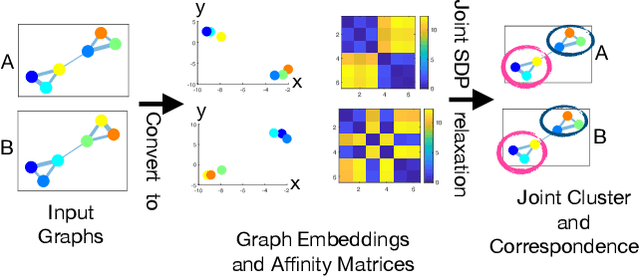
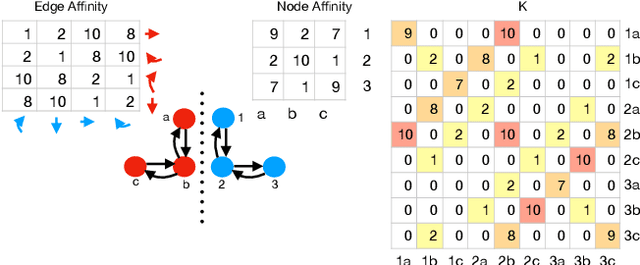
This paper proposes a new algorithm for simultaneous graph matching and clustering. For the first time in the literature, these two problems are solved jointly and synergetically without relying on any training data, which brings advantages for identifying similar arbitrary objects in compound 3D scenes and matching them. For joint reasoning, we first rephrase graph matching as a rigid point set registration problem operating on spectral graph embeddings. Consequently, we utilise efficient convex semidefinite program relaxations for aligning points in Hilbert spaces and add coupling constraints to model the mutual dependency and exploit synergies between both tasks. We outperform state of the art in challenging cases with non-perfectly matching and noisy graphs, and we show successful applications on real compound scenes with multiple 3D elements. Our source code and data are publicly available.
* 12 pages, 8 figures; source code available; project webpage: https://4dqv.mpi-inf.mpg.de/JointGMC/
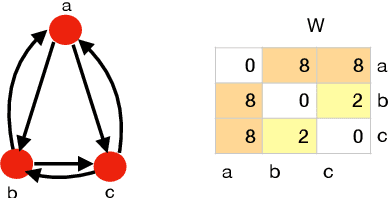
Sparse Quadratic Optimisation over the Stiefel Manifold with Application to Permutation Synchronisation
Sep 30, 2021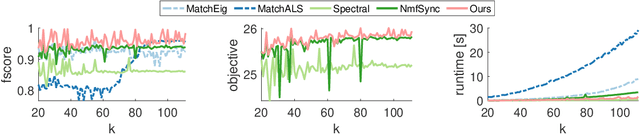
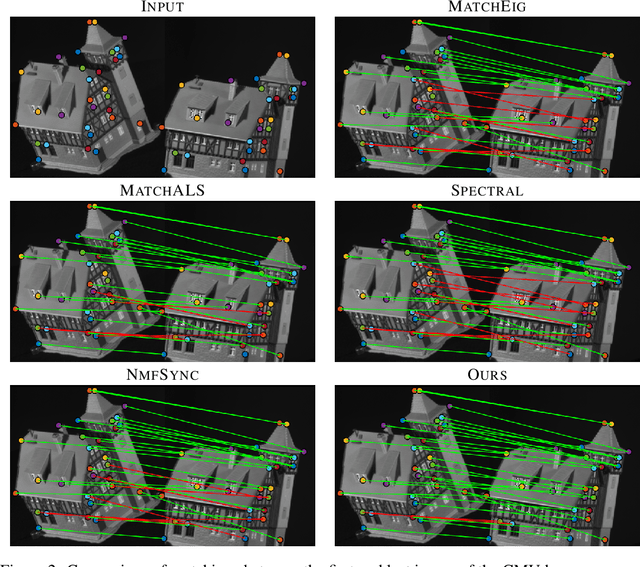
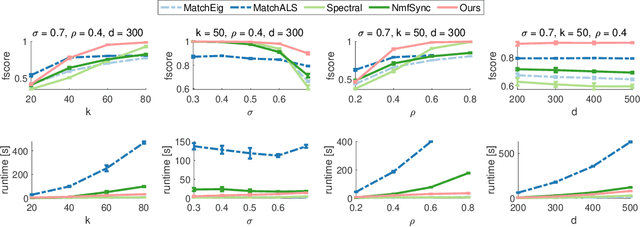
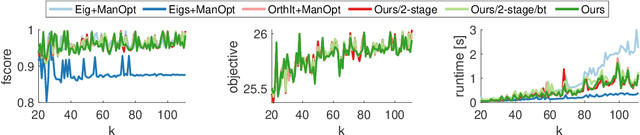
We address the non-convex optimisation problem of finding a sparse matrix on the Stiefel manifold (matrices with mutually orthogonal columns of unit length) that maximises (or minimises) a quadratic objective function. Optimisation problems on the Stiefel manifold occur for example in spectral relaxations of various combinatorial problems, such as graph matching, clustering, or permutation synchronisation. Although sparsity is a desirable property in such settings, it is mostly neglected in spectral formulations since existing solvers, e.g. based on eigenvalue decomposition, are unable to account for sparsity while at the same time maintaining global optimality guarantees. We fill this gap and propose a simple yet effective sparsity-promoting modification of the Orthogonal Iteration algorithm for finding the dominant eigenspace of a matrix. By doing so, we can guarantee that our method finds a Stiefel matrix that is globally optimal with respect to the quadratic objective function, while in addition being sparse. As a motivating application we consider the task of permutation synchronisation, which can be understood as a constrained clustering problem that has particular relevance for matching multiple images or 3D shapes in computer vision, computer graphics, and beyond. We demonstrate that the proposed approach outperforms previous methods in this domain.
RGB2Hands: Real-Time Tracking of 3D Hand Interactions from Monocular RGB Video
Jun 22, 2021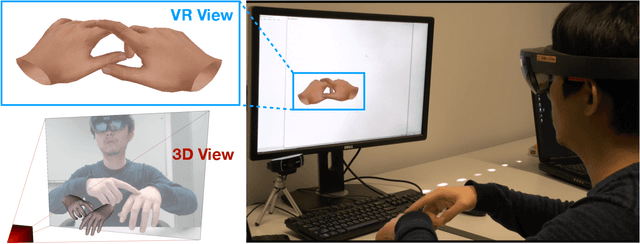

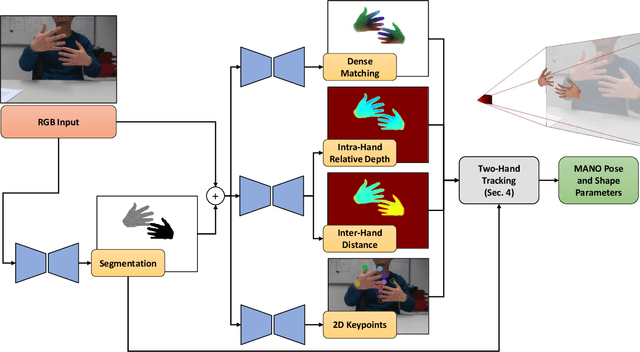
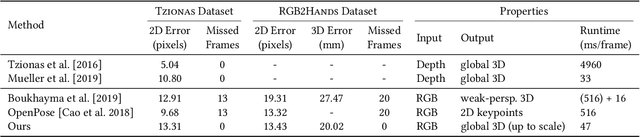
Tracking and reconstructing the 3D pose and geometry of two hands in interaction is a challenging problem that has a high relevance for several human-computer interaction applications, including AR/VR, robotics, or sign language recognition. Existing works are either limited to simpler tracking settings (e.g., considering only a single hand or two spatially separated hands), or rely on less ubiquitous sensors, such as depth cameras. In contrast, in this work we present the first real-time method for motion capture of skeletal pose and 3D surface geometry of hands from a single RGB camera that explicitly considers close interactions. In order to address the inherent depth ambiguities in RGB data, we propose a novel multi-task CNN that regresses multiple complementary pieces of information, including segmentation, dense matchings to a 3D hand model, and 2D keypoint positions, together with newly proposed intra-hand relative depth and inter-hand distance maps. These predictions are subsequently used in a generative model fitting framework in order to estimate pose and shape parameters of a 3D hand model for both hands. We experimentally verify the individual components of our RGB two-hand tracking and 3D reconstruction pipeline through an extensive ablation study. Moreover, we demonstrate that our approach offers previously unseen two-hand tracking performance from RGB, and quantitatively and qualitatively outperforms existing RGB-based methods that were not explicitly designed for two-hand interactions. Moreover, our method even performs on-par with depth-based real-time methods.
* SIGGRAPH Asia 2020
Real-time Pose and Shape Reconstruction of Two Interacting Hands With a Single Depth Camera
Jun 15, 2021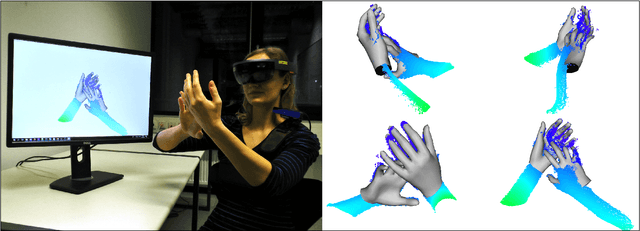

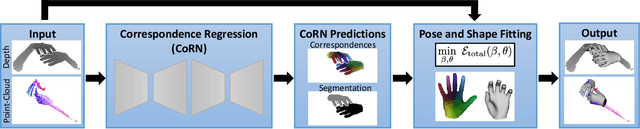

We present a novel method for real-time pose and shape reconstruction of two strongly interacting hands. Our approach is the first two-hand tracking solution that combines an extensive list of favorable properties, namely it is marker-less, uses a single consumer-level depth camera, runs in real time, handles inter- and intra-hand collisions, and automatically adjusts to the user's hand shape. In order to achieve this, we embed a recent parametric hand pose and shape model and a dense correspondence predictor based on a deep neural network into a suitable energy minimization framework. For training the correspondence prediction network, we synthesize a two-hand dataset based on physical simulations that includes both hand pose and shape annotations while at the same time avoiding inter-hand penetrations. To achieve real-time rates, we phrase the model fitting in terms of a nonlinear least-squares problem so that the energy can be optimized based on a highly efficient GPU-based Gauss-Newton optimizer. We show state-of-the-art results in scenes that exceed the complexity level demonstrated by previous work, including tight two-hand grasps, significant inter-hand occlusions, and gesture interaction.