 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Certified Training: Towards Better Accuracy-Robustness Tradeoffs
Jul 24, 2023As deep learning models continue to advance and are increasingly utilized in real-world systems, the issue of robustness remains a major challenge. Existing certified training methods produce models that achieve high provable robustness guarantees at certain perturbation levels. However, the main problem of such models is a dramatically low standard accuracy, i.e. accuracy on clean unperturbed data, that makes them impractical. In this work, we consider a more realistic perspective of maximizing the robustness of a model at certain levels of (high) standard accuracy. To this end, we propose a novel certified training method based on a key insight that training with adaptive certified radii helps to improve both the accuracy and robustness of the model, advancing state-of-the-art accuracy-robustness tradeoffs. We demonstrate the effectiveness of the proposed method on MNIST, CIFAR-10, and TinyImageNet datasets. Particularly, on CIFAR-10 and TinyImageNet, our method yields models with up to two times higher robustness, measured as an average certified radius of a test set, at the same levels of standard accuracy compared to baseline approaches.
Non-Separable Multi-Dimensional Network Flows for Visual Computing
May 15, 2023


Flows in networks (or graphs) play a significant role in numerous computer vision tasks. The scalar-valued edges in these graphs often lead to a loss of information and thereby to limitations in terms of expressiveness. For example, oftentimes high-dimensional data (e.g. feature descriptors) are mapped to a single scalar value (e.g. the similarity between two feature descriptors). To overcome this limitation, we propose a novel formalism for non-separable multi-dimensional network flows. By doing so, we enable an automatic and adaptive feature selection strategy - since the flow is defined on a per-dimension basis, the maximizing flow automatically chooses the best matching feature dimensions. As a proof of concept, we apply our formalism to the multi-object tracking problem and demonstrate that our approach outperforms scalar formulations on the MOT16 benchmark in terms of robustness to noise.
Unsupervised Learning of Robust Spectral Shape Matching
Apr 27, 2023We propose a novel learning-based approach for robust 3D shape matching. Our method builds upon deep functional maps and can be trained in a fully unsupervised manner. Previous deep functional map methods mainly focus on predicting optimised functional maps alone, and then rely on off-the-shelf post-processing to obtain accurate point-wise maps during inference. However, this two-stage procedure for obtaining point-wise maps often yields sub-optimal performance. In contrast, building upon recent insights about the relation between functional maps and point-wise maps, we propose a novel unsupervised loss to couple the functional maps and point-wise maps, and thereby directly obtain point-wise maps without any post-processing. Our approach obtains accurate correspondences not only for near-isometric shapes, but also for more challenging non-isometric shapes and partial shapes, as well as shapes with different discretisation or topological noise. Using a total of nine diverse datasets, we extensively evaluate the performance and demonstrate that our method substantially outperforms previous state-of-the-art methods, even compared to recent supervised methods. Our code is available at https://github.com/dongliangcao/Unsupervised-Learning-of-Robust-Spectral-Shape-Matching.
Self-Supervised Learning for Multimodal Non-Rigid 3D Shape Matching
Mar 20, 2023The matching of 3D shapes has been extensively studied for shapes represented as surface meshes, as well as for shapes represented as point clouds. While point clouds are a common representation of raw real-world 3D data (e.g. from laser scanners), meshes encode rich and expressive topological information, but their creation typically requires some form of (often manual) curation. In turn, methods that purely rely on point clouds are unable to meet the matching quality of mesh-based methods that utilise the additional topological structure. In this work we close this gap by introducing a self-supervised multimodal learning strategy that combines mesh-based functional map regularisation with a contrastive loss that couples mesh and point cloud data. Our shape matching approach allows to obtain intramodal correspondences for triangle meshes, complete point clouds, and partially observed point clouds, as well as correspondences across these data modalities. We demonstrate that our method achieves state-of-the-art results on several challenging benchmark datasets even in comparison to recent supervised methods, and that our method reaches previously unseen cross-dataset generalisation ability.
Universe Points Representation Learning for Partial Multi-Graph Matching
Dec 07, 2022



Many challenges from natural world can be formulated as a graph matching problem. Previous deep learning-based methods mainly consider a full two-graph matching setting. In this work, we study the more general partial matching problem with multi-graph cycle consistency guarantees. Building on a recent progress in deep learning on graphs, we propose a novel data-driven method (URL) for partial multi-graph matching, which uses an object-to-universe formulation and learns latent representations of abstract universe points. The proposed approach advances the state of the art in semantic keypoint matching problem, evaluated on Pascal VOC, CUB, and Willow datasets. Moreover, the set of controlled experiments on a synthetic graph matching dataset demonstrates the scalability of our method to graphs with large number of nodes and its robustness to high partiality.
Conjugate Product Graphs for Globally Optimal 2D-3D Shape Matching
Nov 21, 2022We consider the problem of finding a continuous and non-rigid matching between a 2D contour and a 3D mesh. While such problems can be solved to global optimality by finding a shortest path in the product graph between both shapes, existing solutions heavily rely on unrealistic prior assumptions to avoid degenerate solutions (e.g. knowledge to which region of the 3D shape each point of the 2D contour is matched). To address this, we propose a novel 2D-3D shape matching formalism based on the conjugate product graph between the 2D contour and the 3D shape. Doing so allows us for the first time to consider higher-order costs, i.e. defined for edge chains, as opposed to costs defined for single edges. This offers substantially more flexibility, which we utilise to incorporate a local rigidity prior. By doing so, we effectively circumvent degenerate solutions and thereby obtain smoother and more realistic matchings, even when using only a one-dimensional feature descriptor. Overall, our method finds globally optimal and continuous 2D-3D matchings, has the same asymptotic complexity as previous solutions, produces state-of-the-art results for shape matching and is even capable of matching partial shapes.
HandFlow: Quantifying View-Dependent 3D Ambiguity in Two-Hand Reconstruction with Normalizing Flow
Oct 04, 2022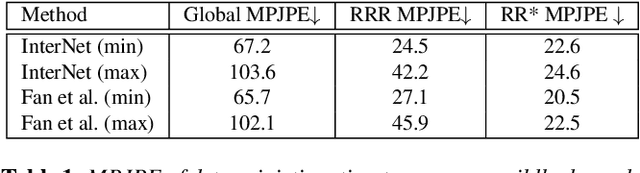
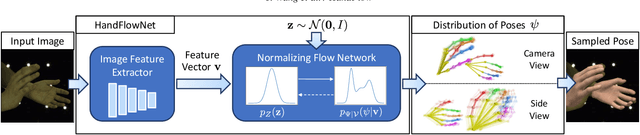
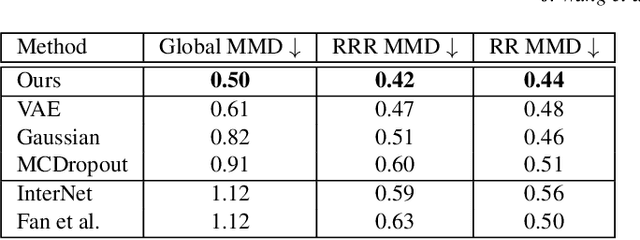
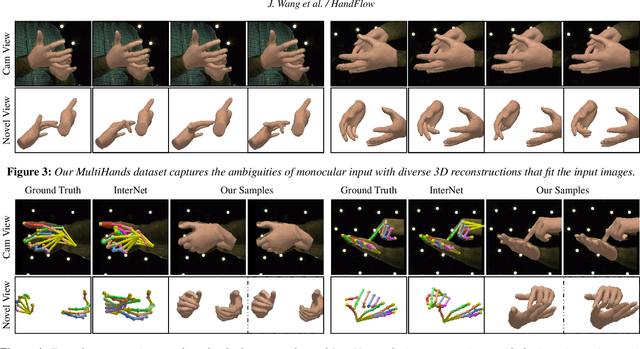
Reconstructing two-hand interactions from a single image is a challenging problem due to ambiguities that stem from projective geometry and heavy occlusions. Existing methods are designed to estimate only a single pose, despite the fact that there exist other valid reconstructions that fit the image evidence equally well. In this paper we propose to address this issue by explicitly modeling the distribution of plausible reconstructions in a conditional normalizing flow framework. This allows us to directly supervise the posterior distribution through a novel determinant magnitude regularization, which is key to varied 3D hand pose samples that project well into the input image. We also demonstrate that metrics commonly used to assess reconstruction quality are insufficient to evaluate pose predictions under such severe ambiguity. To address this, we release the first dataset with multiple plausible annotations per image called MultiHands. The additional annotations enable us to evaluate the estimated distribution using the maximum mean discrepancy metric. Through this, we demonstrate the quality of our probabilistic reconstruction and show that explicit ambiguity modeling is better-suited for this challenging problem.
Unsupervised Deep Multi-Shape Matching
Jul 20, 2022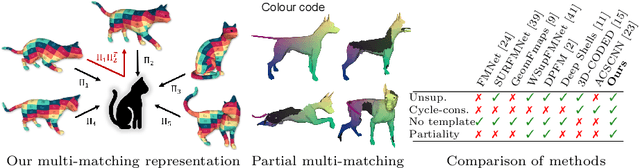
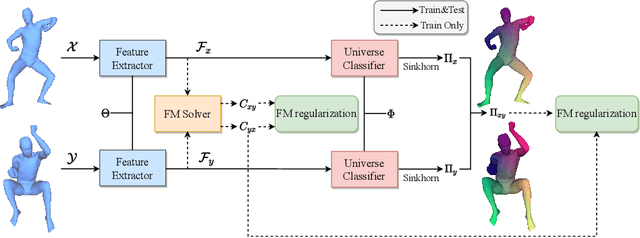
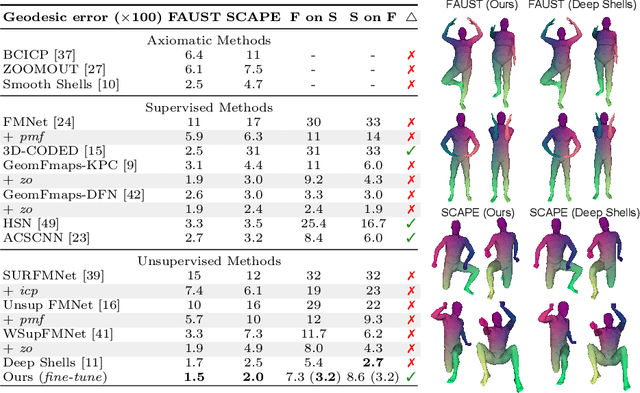
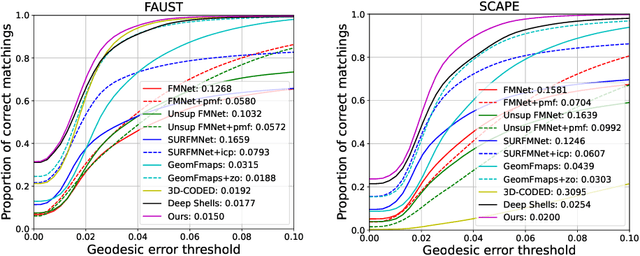
3D shape matching is a long-standing problem in computer vision and computer graphics. While deep neural networks were shown to lead to state-of-the-art results in shape matching, existing learning-based approaches are limited in the context of multi-shape matching: (i) either they focus on matching pairs of shapes only and thus suffer from cycle-inconsistent multi-matchings, or (ii) they require an explicit template shape to address the matching of a collection of shapes. In this paper, we present a novel approach for deep multi-shape matching that ensures cycle-consistent multi-matchings while not depending on an explicit template shape. To this end, we utilise a shape-to-universe multi-matching representation that we combine with powerful functional map regularisation, so that our multi-shape matching neural network can be trained in a fully unsupervised manner. While the functional map regularisation is only considered during training time, functional maps are not computed for predicting correspondences, thereby allowing for fast inference. We demonstrate that our method achieves state-of-the-art results on several challenging benchmark datasets, and, most remarkably, that our unsupervised method even outperforms recent supervised methods.
A Comparative Study of Graph Matching Algorithms in Computer Vision
Jul 01, 2022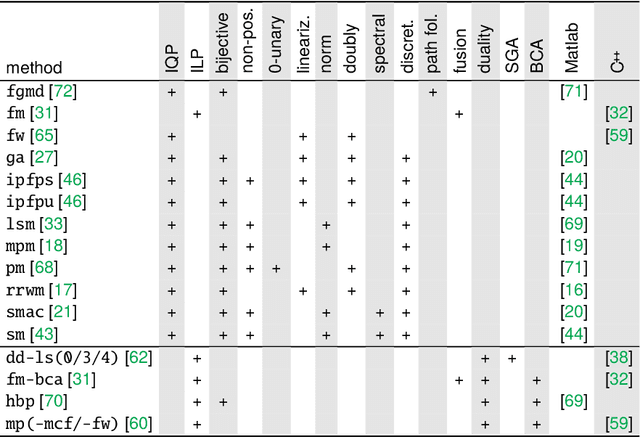
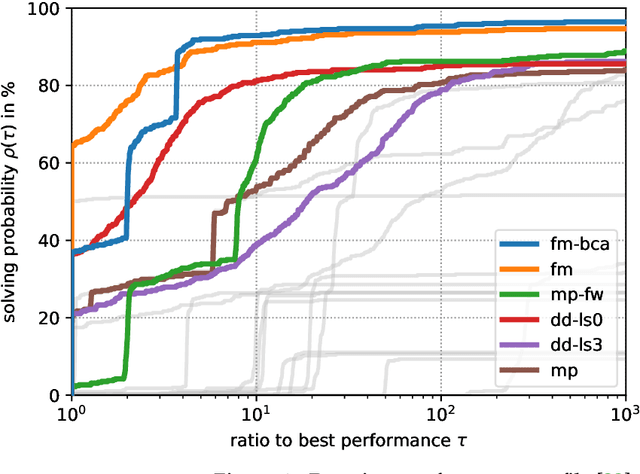

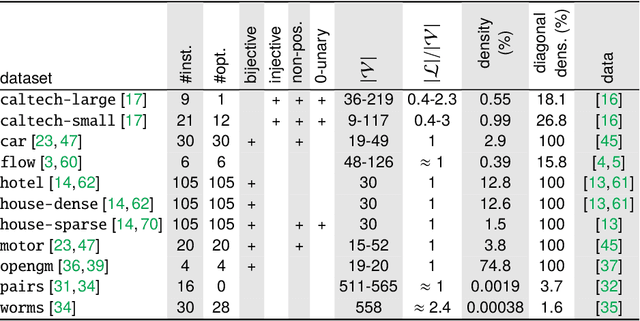
The graph matching optimization problem is an essential component for many tasks in computer vision, such as bringing two deformable objects in correspondence. Naturally, a wide range of applicable algorithms have been proposed in the last decades. Since a common standard benchmark has not been developed, their performance claims are often hard to verify as evaluation on differing problem instances and criteria make the results incomparable. To address these shortcomings, we present a comparative study of graph matching algorithms. We create a uniform benchmark where we collect and categorize a large set of existing and publicly available computer vision graph matching problems in a common format. At the same time we collect and categorize the most popular open-source implementations of graph matching algorithms. Their performance is evaluated in a way that is in line with the best practices for comparing optimization algorithms. The study is designed to be reproducible and extensible to serve as a valuable resource in the future. Our study provides three notable insights: 1.) popular problem instances are exactly solvable in substantially less than 1 second and, therefore, are insufficient for future empirical evaluations; 2.) the most popular baseline methods are highly inferior to the best available methods; 3.) despite the NP-hardness of the problem, instances coming from vision applications are often solvable in a few seconds even for graphs with more than 500 vertices.
Efficient and Flexible Sublabel-Accurate Energy Minimization
Jun 20, 2022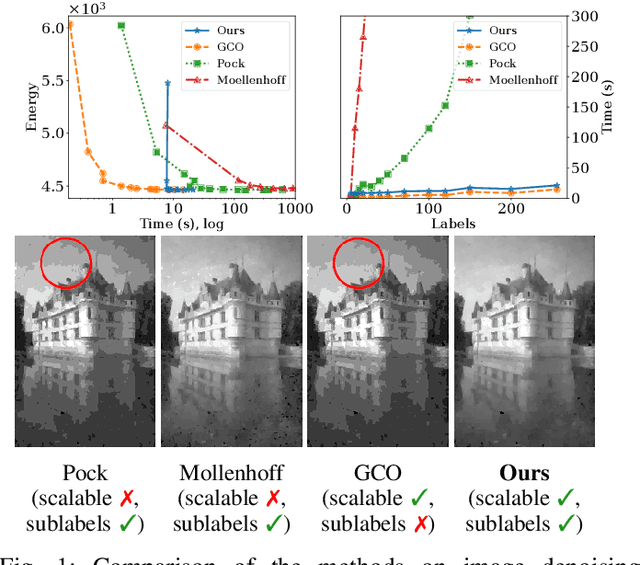

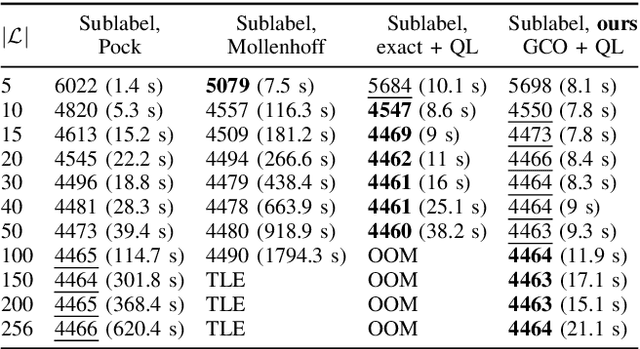
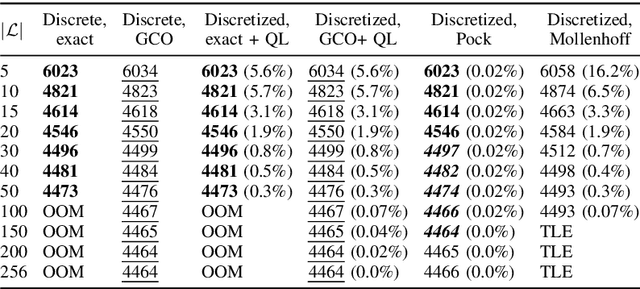
We address the problem of minimizing a class of energy functions consisting of data and smoothness terms that commonly occur in machine learning, computer vision, and pattern recognition. While discrete optimization methods are able to give theoretical optimality guarantees, they can only handle a finite number of labels and therefore suffer from label discretization bias. Existing continuous optimization methods can find sublabel-accurate solutions, but they are not efficient for large label spaces. In this work, we propose an efficient sublabel-accurate method that utilizes the best properties of both continuous and discrete models. We separate the problem into two sequential steps: (i) global discrete optimization for selecting the label range, and (ii) efficient continuous sublabel-accurate local refinement of a convex approximation of the energy function in the chosen range. Doing so allows us to achieve a boost in time and memory efficiency while practically keeping the accuracy at the same level as continuous convex relaxation methods, and in addition, providing theoretical optimality guarantees at the level of discrete methods. Finally, we show the flexibility of the proposed approach to general pairwise smoothness terms, so that it is applicable to a wide range of regularizations. Experiments on the illustrating example of the image denoising problem demonstrate the properties of the proposed method. The code reproducing experiments is available at \url{https://github.com/nurlanov-zh/sublabel-accurate-alpha-expansion}.