 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Clicks to Conversions: Recommendation for long-term reward
Sep 01, 2020Recommender systems are often optimised for short-term reward: a recommendation is considered successful if a reward (e.g. a click) can be observed immediately after the recommendation. The advantage of this framework is that with some reasonable (although questionable) assumptions, it allows familiar supervised learning tools to be used for the recommendation task. However, it means that long-term business metrics, e.g. sales or retention are ignored. In this paper we introduce a framework for modeling long-term rewards in the RecoGym simulation environment. We use this newly introduced functionality to showcase problems introduced by the last-click attribution scheme in the case of conversion-optimized recommendations and propose a simple extension that leads to state-of-the-art results.
BLOB : A Probabilistic Model for Recommendation that Combines Organic and Bandit Signals
Aug 28, 2020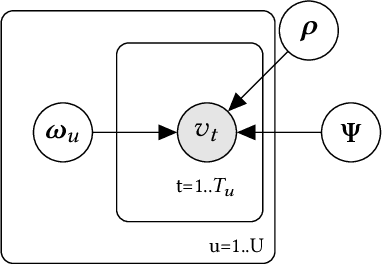
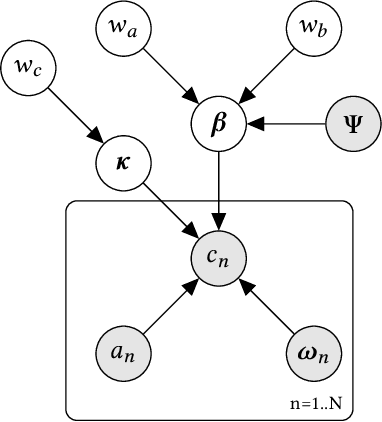
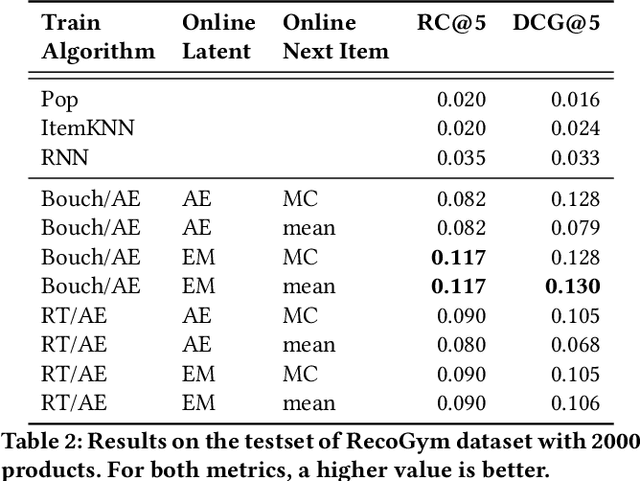
A common task for recommender systems is to build a pro le of the interests of a user from items in their browsing history and later to recommend items to the user from the same catalog. The users' behavior consists of two parts: the sequence of items that they viewed without intervention (the organic part) and the sequences of items recommended to them and their outcome (the bandit part). In this paper, we propose Bayesian Latent Organic Bandit model (BLOB), a probabilistic approach to combine the 'or-ganic' and 'bandit' signals in order to improve the estimation of recommendation quality. The bandit signal is valuable as it gives direct feedback of recommendation performance, but the signal quality is very uneven, as it is highly concentrated on the recommendations deemed optimal by the past version of the recom-mender system. In contrast, the organic signal is typically strong and covers most items, but is not always relevant to the recommendation task. In order to leverage the organic signal to e ciently learn the bandit signal in a Bayesian model we identify three fundamental types of distances, namely action-history, action-action and history-history distances. We implement a scalable approximation of the full model using variational auto-encoders and the local re-paramerization trick. We show using extensive simulation studies that our method out-performs or matches the value of both state-of-the-art organic-based recommendation algorithms, and of bandit-based methods (both value and policy-based) both in organic and bandit-rich environments.
Reconsidering Analytical Variational Bounds for Output Layers of Deep Networks
Oct 03, 2019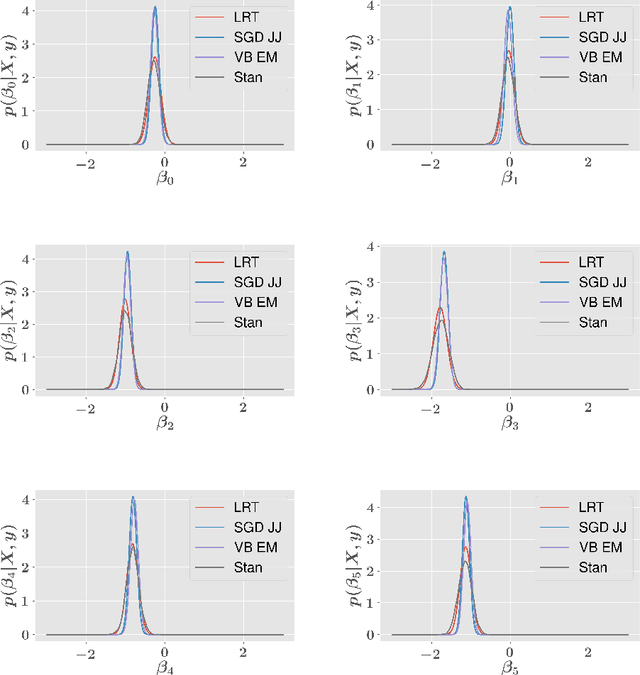
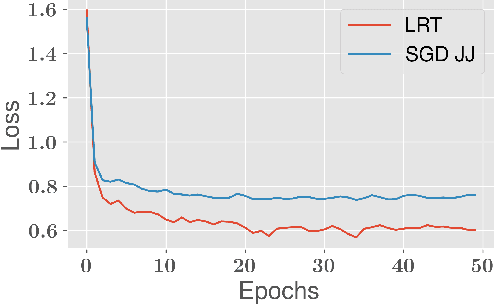
The combination of the re-parameterization trick with the use of variational auto-encoders has caused a sensation in Bayesian deep learning, allowing the training of realistic generative models of images and has considerably increased our ability to use scalable latent variable models. The re-parameterization trick is necessary for models in which no analytical variational bound is available and allows noisy gradients to be computed for arbitrary models. However, for certain standard output layers of a neural network, analytical bounds are available and the variational auto-encoder may be used both without the re-parameterization trick or the need for any Monte Carlo approximation. In this work, we show that using Jaakola and Jordan bound, we can produce a binary classification layer that allows a Bayesian output layer to be trained, using the standard stochastic gradient descent algorithm. We further demonstrate that a latent variable model utilizing the Bouchard bound for multi-class classification allows for fast training of a fully probabilistic latent factor model, even when the number of classes is very large.
Learning from Bandit Feedback: An Overview of the State-of-the-art
Sep 18, 2019
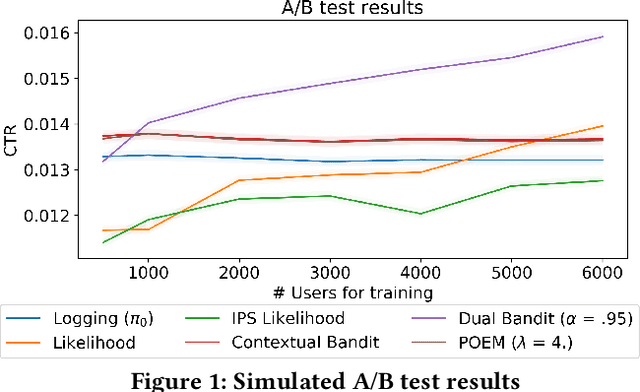
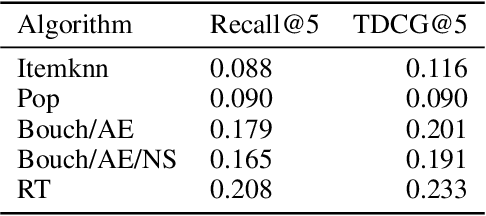
In machine learning we often try to optimise a decision rule that would have worked well over a historical dataset; this is the so called empirical risk minimisation principle. In the context of learning from recommender system logs, applying this principle becomes a problem because we do not have available the reward of decisions we did not do. In order to handle this "bandit-feedback" setting, several Counterfactual Risk Minimisation (CRM) methods have been proposed in recent years, that attempt to estimate the performance of different policies on historical data. Through importance sampling and various variance reduction techniques, these methods allow more robust learning and inference than classical approaches. It is difficult to accurately estimate the performance of policies that frequently perform actions that were infrequently done in the past and a number of different types of estimators have been proposed. In this paper, we review several methods, based on different off-policy estimators, for learning from bandit feedback. We discuss key differences and commonalities among existing approaches, and compare their empirical performance on the RecoGym simulation environment. To the best of our knowledge, this work is the first comparison study for bandit algorithms in a recommender system setting.
Relaxed Softmax for learning from Positive and Unlabeled data
Sep 17, 2019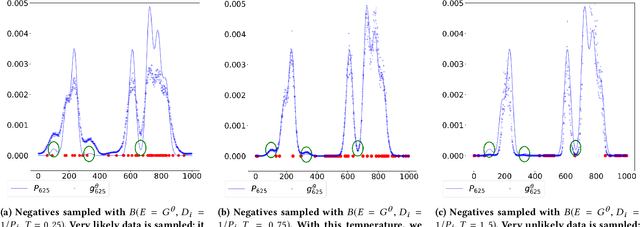
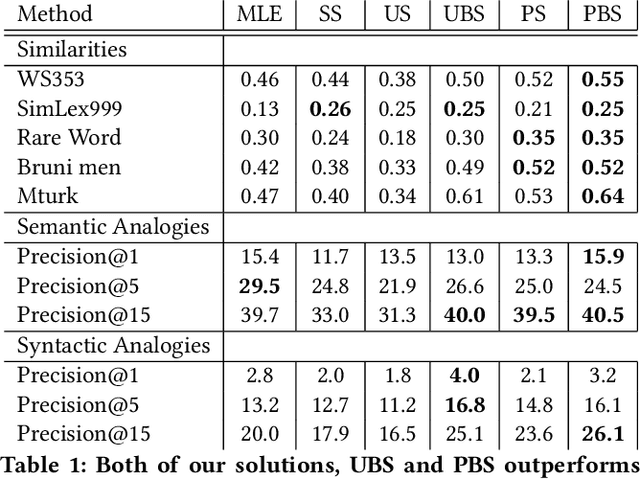
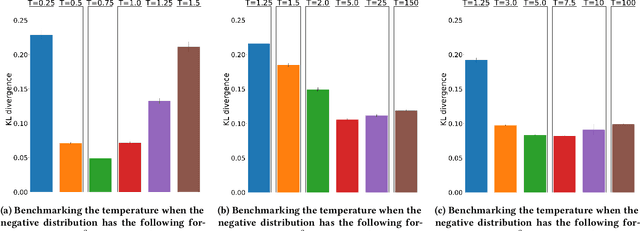
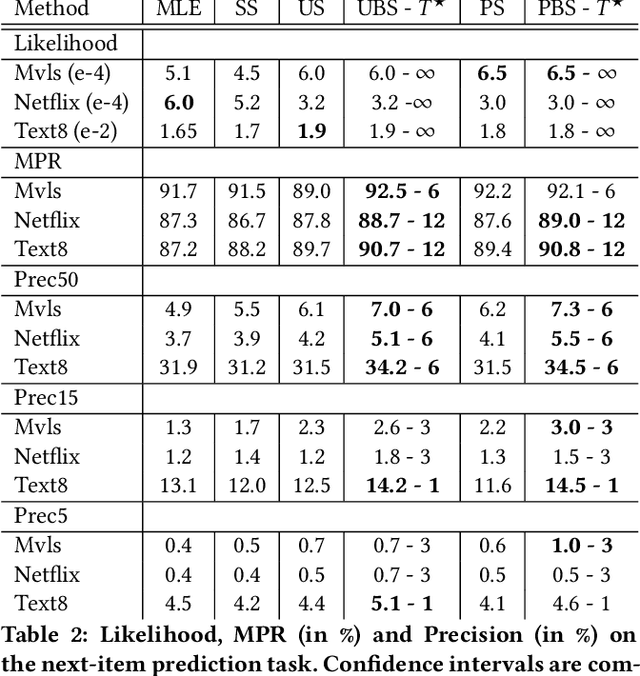
In recent years, the softmax model and its fast approximations have become the de-facto loss functions for deep neural networks when dealing with multi-class prediction. This loss has been extended to language modeling and recommendation, two fields that fall into the framework of learning from Positive and Unlabeled data. In this paper, we stress the different drawbacks of the current family of softmax losses and sampling schemes when applied in a Positive and Unlabeled learning setup. We propose both a Relaxed Softmax loss (RS) and a new negative sampling scheme based on Boltzmann formulation. We show that the new training objective is better suited for the tasks of density estimation, item similarity and next-event prediction by driving uplifts in performance on textual and recommendation datasets against classical softmax.
* 9 pages, 5 figures, 2 tables, published at RecSys 2019
Recommendation System-based Upper Confidence Bound for Online Advertising
Sep 09, 2019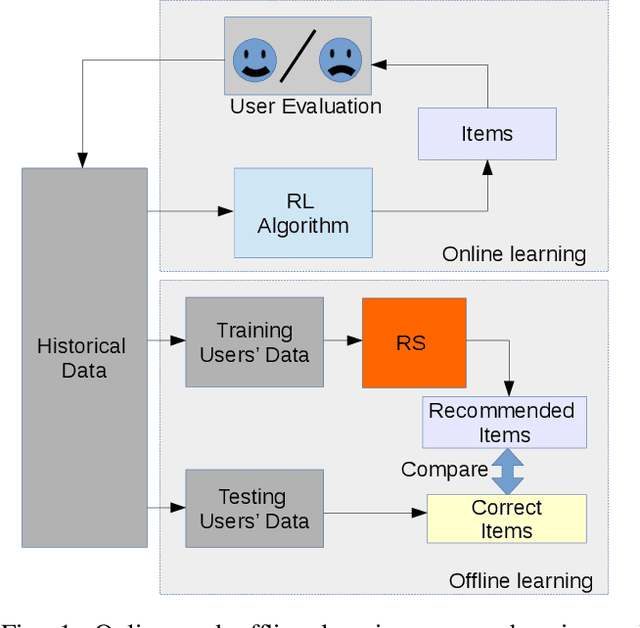
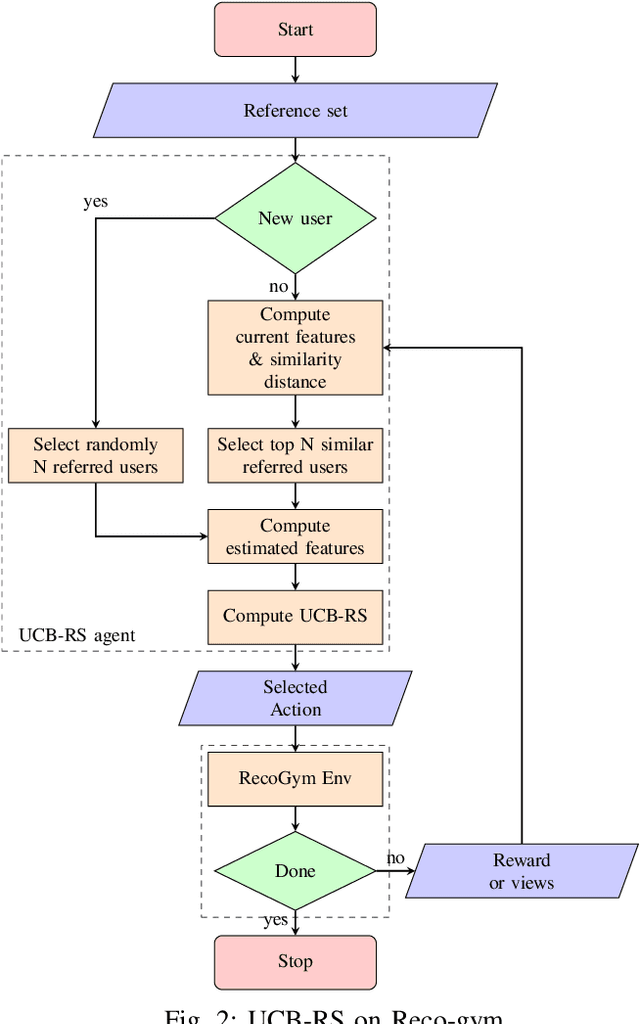
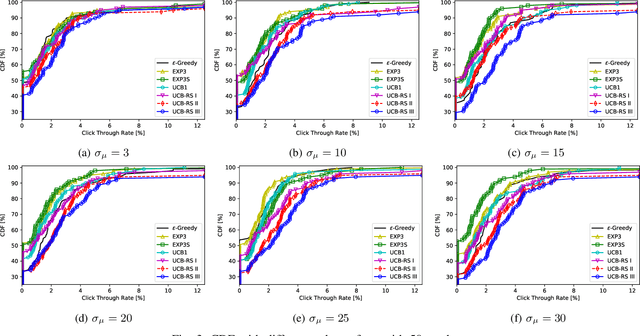
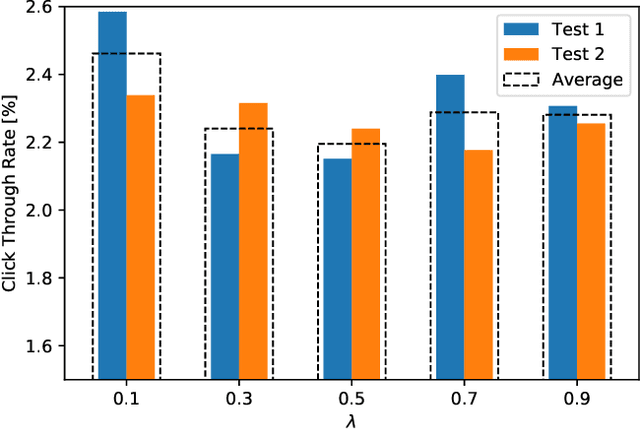
In this paper, the method UCB-RS, which resorts to recommendation system (RS) for enhancing the upper-confidence bound algorithm UCB, is presented. The proposed method is used for dealing with non-stationary and large-state spaces multi-armed bandit problems. The proposed method has been targeted to the problem of the product recommendation in the online advertising. Through extensive testing with RecoGym, an OpenAI Gym-based reinforcement learning environment for the product recommendation in online advertising, the proposed method outperforms the widespread reinforcement learning schemes such as $\epsilon$-Greedy, Upper Confidence (UCB1) and Exponential Weights for Exploration and Exploitation (EXP3).
On the Value of Bandit Feedback for Offline Recommender System Evaluation
Jul 26, 2019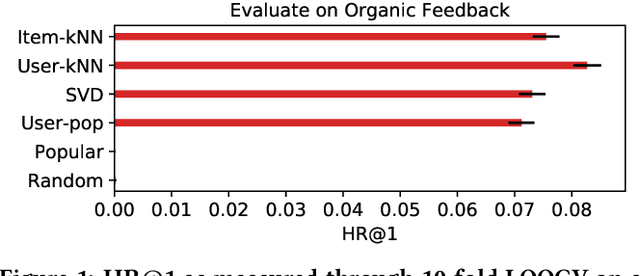
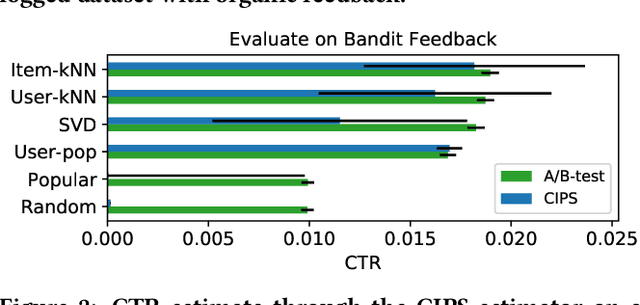
In academic literature, recommender systems are often evaluated on the task of next-item prediction. The procedure aims to give an answer to the question: "Given the natural sequence of user-item interactions up to time t, can we predict which item the user will interact with at time t+1?". Evaluation results obtained through said methodology are then used as a proxy to predict which system will perform better in an online setting. The online setting, however, poses a subtly different question: "Given the natural sequence of user-item interactions up to time t, can we get the user to interact with a recommended item at time t+1?". From a causal perspective, the system performs an intervention, and we want to measure its effect. Next-item prediction is often used as a fall-back objective when information about interventions and their effects (shown recommendations and whether they received a click) is unavailable. When this type of data is available, however, it can provide great value for reliably estimating online recommender system performance. Through a series of simulated experiments with the RecoGym environment, we show where traditional offline evaluation schemes fall short. Additionally, we show how so-called bandit feedback can be exploited for effective offline evaluation that more accurately reflects online performance.
Distributionally Robust Counterfactual Risk Minimization
Jun 14, 2019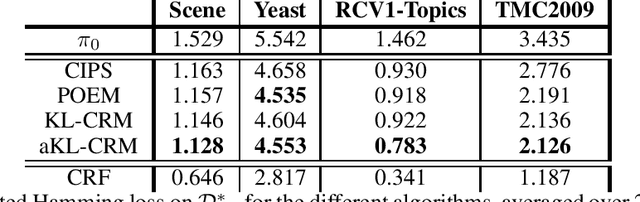
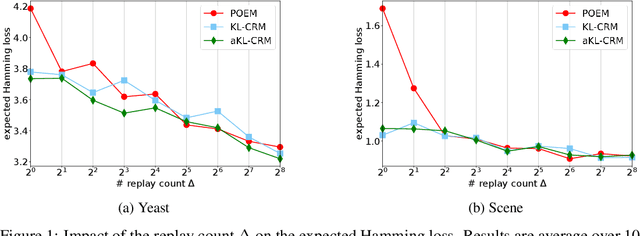
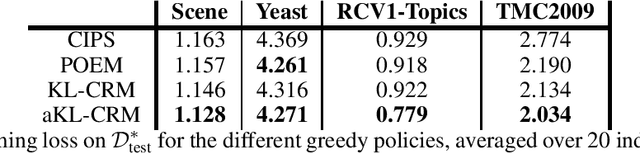
This manuscript introduces the idea of using Distributionally Robust Optimization (DRO) for the Counterfactual Risk Minimization (CRM) problem. Tapping into a rich existing literature, we show that DRO is a principled tool for counterfactual decision making. We also show that well-established solutions to the CRM problem like sample variance penalization schemes are special instances of a more general DRO problem. In this unifying framework, a variety of distributionally robust counterfactual risk estimators can be constructed using various probability distances and divergences as uncertainty measures. We propose the use of Kullback-Leibler divergence as an alternative way to model uncertainty in CRM and derive a new robust counterfactual objective. In our experiments, we show that this approach outperforms the state-of-the-art on four benchmark datasets, validating the relevance of using other uncertainty measures in practical applications.
Three Methods for Training on Bandit Feedback
Apr 24, 2019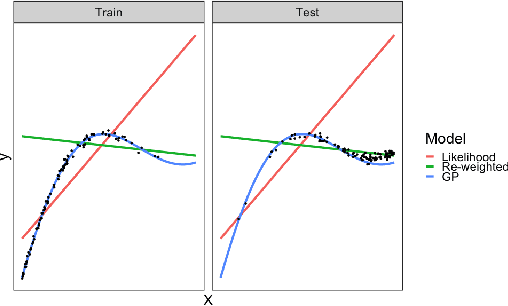
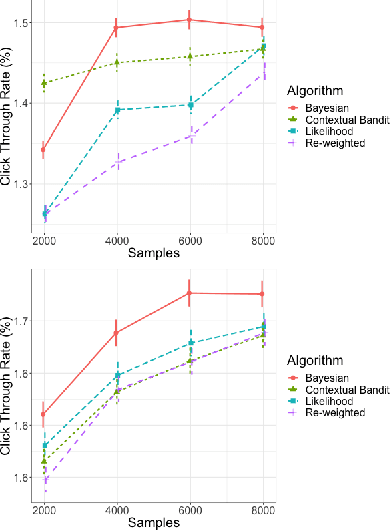
There are three quite distinct ways to train a machine learning model on recommender system logs. The first method is to model the reward prediction for each possible recommendation to the user, at the scoring time the best recommendation is found by computing an argmax over the personalized recommendations. This method obeys principles such as the conditionality principle and the likelihood principle. A second method is useful when the model does not fit reality and underfits. In this case, we can use the fact that we know the distribution of historical recommendations (concentrated on previously identified good actions with some exploration) to adjust the errors in the fit to be evenly distributed over all actions. Finally, the inverse propensity score can be used to produce an estimate of the decision rules expected performance. The latter two methods violate the conditionality and likelihood principle but are shown to have good performance in certain settings. In this paper we review the literature around this fundamental, yet often overlooked choice and do some experiments using the RecoGym simulation environment.
RecoGym: A Reinforcement Learning Environment for the problem of Product Recommendation in Online Advertising
Sep 14, 2018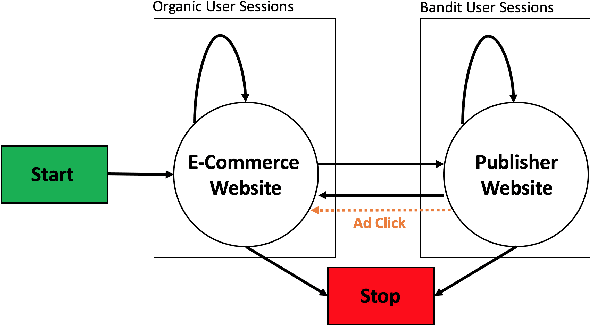

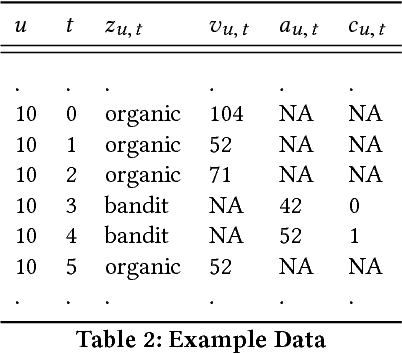
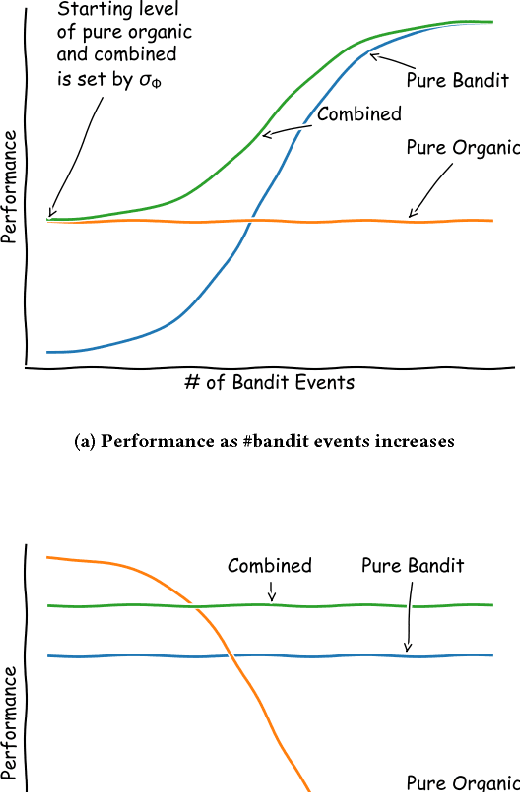
Recommender Systems are becoming ubiquitous in many settings and take many forms, from product recommendation in e-commerce stores, to query suggestions in search engines, to friend recommendation in social networks. Current research directions which are largely based upon supervised learning from historical data appear to be showing diminishing returns with a lot of practitioners report a discrepancy between improvements in offline metrics for supervised learning and the online performance of the newly proposed models. One possible reason is that we are using the wrong paradigm: when looking at the long-term cycle of collecting historical performance data, creating a new version of the recommendation model, A/B testing it and then rolling it out. We see that there a lot of commonalities with the reinforcement learning (RL) setup, where the agent observes the environment and acts upon it in order to change its state towards better states (states with higher rewards). To this end we introduce RecoGym, an RL environment for recommendation, which is defined by a model of user traffic patterns on e-commerce and the users response to recommendations on the publisher websites. We believe that this is an important step forward for the field of recommendation systems research, that could open up an avenue of collaboration between the recommender systems and reinforcement learning communities and lead to better alignment between offline and online performance metrics.