 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Deep Reinforcement Learning Ready for Practical Applications in Healthcare? A Sensitivity Analysis of Duel-DDQN for Sepsis Treatment
May 08, 2020
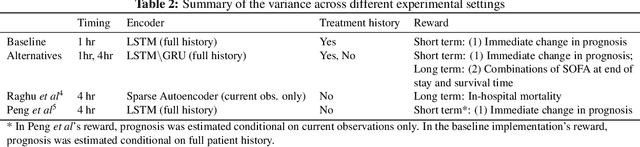
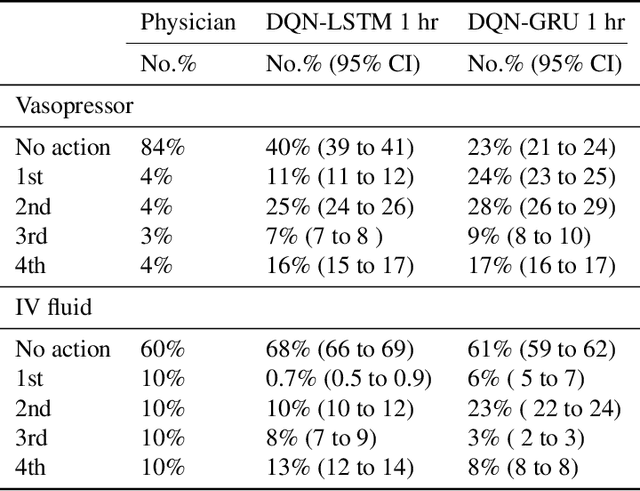
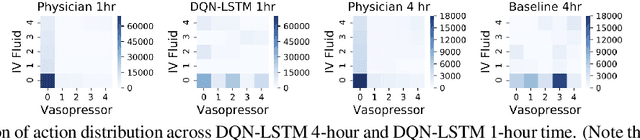
The potential of Reinforcement Learning (RL) has been demonstrated through successful applications to games such as Go and Atari. However, while it is straightforward to evaluate the performance of an RL algorithm in a game setting by simply using it to play the game, evaluation is a major challenge in clinical settings where it could be unsafe to follow RL policies in practice. Thus, understanding sensitivity of RL policies to the host of decisions made during implementation is an important step toward building the type of trust in RL required for eventual clinical uptake. In this work, we perform a sensitivity analysis on a state-of-the-art RL algorithm (Dueling Double Deep Q-Networks)applied to hemodynamic stabilization treatment strategies for septic patients in the ICU. We consider sensitivity of learned policies to input features, time discretization, reward function, and random seeds. We find that varying these settings can significantly impact learned policies, which suggests a need for caution when interpreting RL agent output.
Power-Constrained Bandits
Apr 13, 2020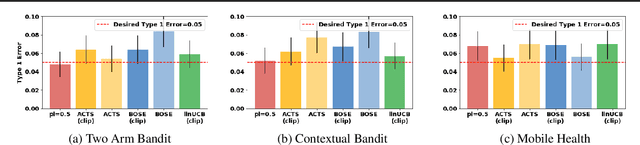

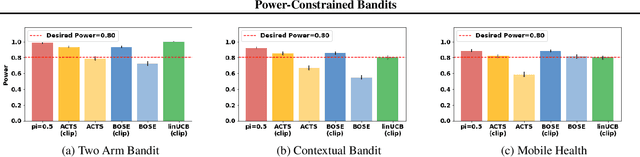
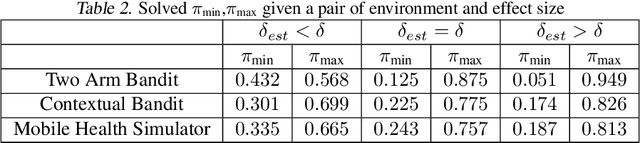
Contextual bandits often provide simple and effective personalization in decision making problems, making them popular in many domains including digital health. However, when bandits are deployed in the context of a scientific study, the aim is not only to personalize for an individual, but also to determine, with sufficient statistical power, whether or not the system's intervention is effective. In this work, we develop a set of constraints and a general meta-algorithm that can be used to both guarantee power constraints and minimize regret. Our results demonstrate a number of existing algorithms can be easily modified to satisfy the constraint without significant decrease in average return. We also show that our modification is also robust to a variety of model mis-specifications.
Characterizing and Avoiding Problematic Global Optima of Variational Autoencoders
Mar 17, 2020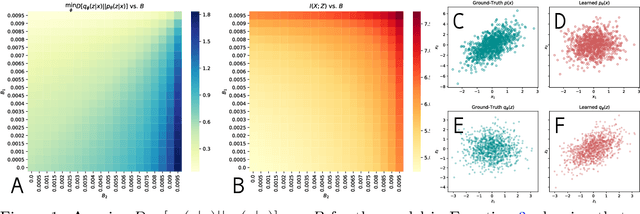

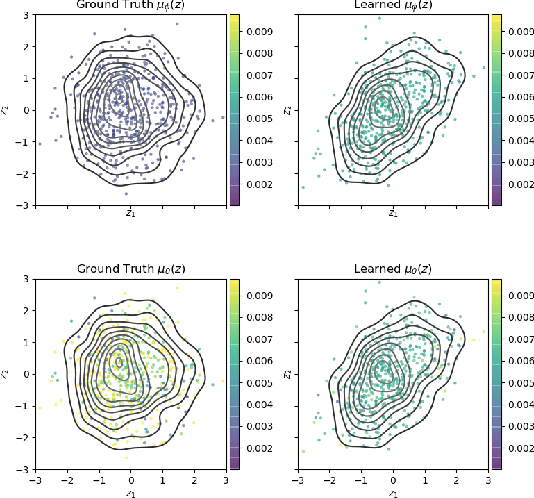
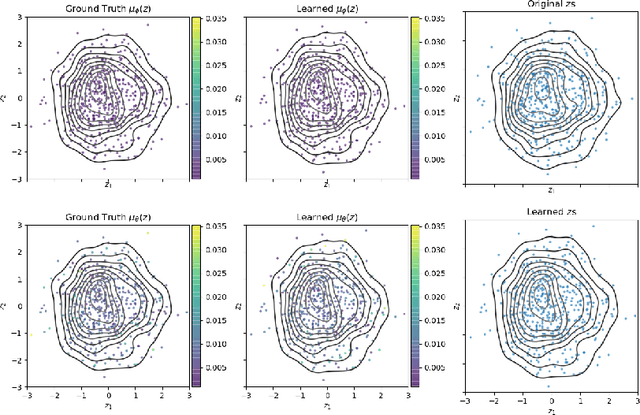
Variational Auto-encoders (VAEs) are deep generative latent variable models consisting of two components: a generative model that captures a data distribution p(x) by transforming a distribution p(z) over latent space, and an inference model that infers likely latent codes for each data point (Kingma and Welling, 2013). Recent work shows that traditional training methods tend to yield solutions that violate modeling desiderata: (1) the learned generative model captures the observed data distribution but does so while ignoring the latent codes, resulting in codes that do not represent the data (e.g. van den Oord et al. (2017); Kim et al. (2018)); (2) the aggregate of the learned latent codes does not match the prior p(z). This mismatch means that the learned generative model will be unable to generate realistic data with samples from p(z)(e.g. Makhzani et al. (2015); Tomczak and Welling (2017)). In this paper, we demonstrate that both issues stem from the fact that the global optima of the VAE training objective often correspond to undesirable solutions. Our analysis builds on two observations: (1) the generative model is unidentifiable - there exist many generative models that explain the data equally well, each with different (and potentially unwanted) properties and (2) bias in the VAE objective - the VAE objective may prefer generative models that explain the data poorly but have posteriors that are easy to approximate. We present a novel inference method, LiBI, mitigating the problems identified in our analysis. On synthetic datasets, we show that LiBI can learn generative models that capture the data distribution and inference models that better satisfy modeling assumptions when traditional methods struggle to do so.
* Accepted at the Proceedings of The 2nd Symposium on Advances in Approximate Bayesian Inference 2019
Interpretable Off-Policy Evaluation in Reinforcement Learning by Highlighting Influential Transitions
Feb 14, 2020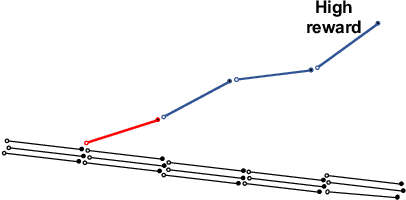
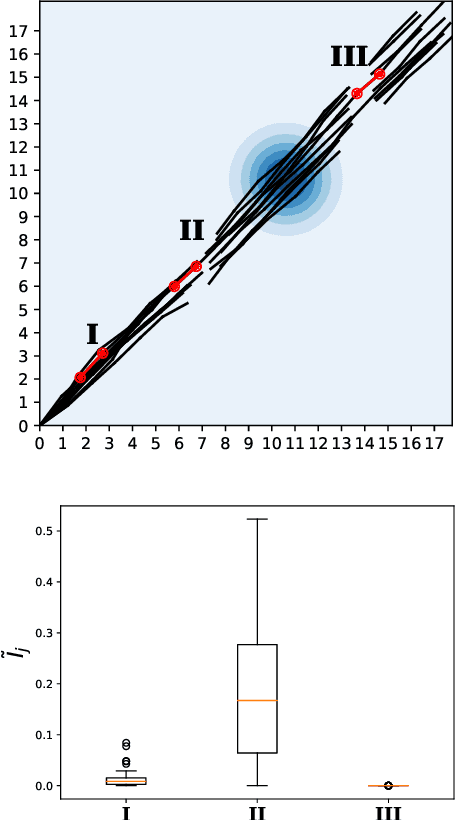
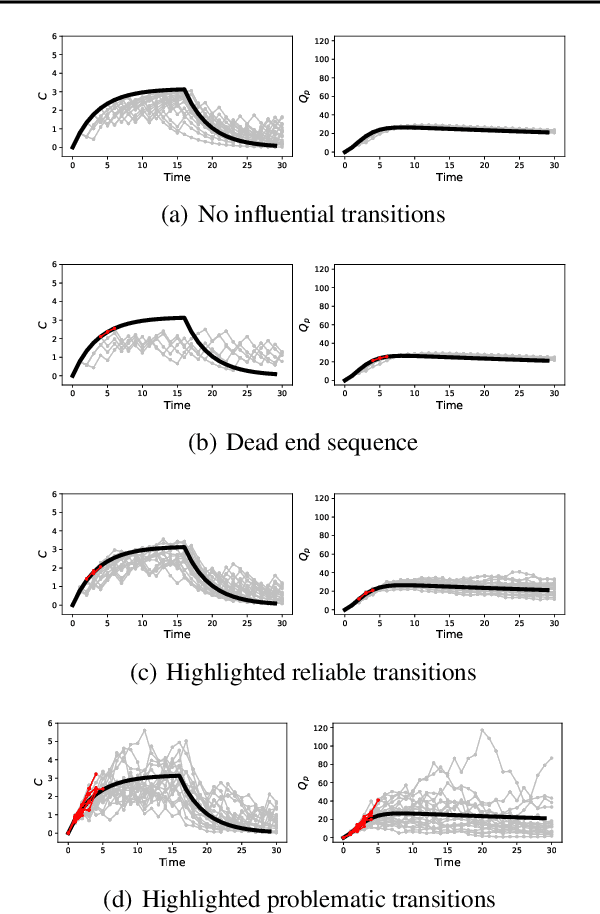
Off-policy evaluation in reinforcement learning offers the chance of using observational data to improve future outcomes in domains such as healthcare and education, but safe deployment in high stakes settings requires ways of assessing its validity. Traditional measures such as confidence intervals may be insufficient due to noise, limited data and confounding. In this paper we develop a method that could serve as a hybrid human-AI system, to enable human experts to analyze the validity of policy evaluation estimates. This is accomplished by highlighting observations in the data whose removal will have a large effect on the OPE estimate, and formulating a set of rules for choosing which ones to present to domain experts for validation. We develop methods to compute exactly the influence functions for fitted Q-evaluation with two different function classes: kernel-based and linear least squares. Experiments on medical simulations and real-world intensive care unit data demonstrate that our method can be used to identify limitations in the evaluation process and make evaluation more robust.
POPCORN: Partially Observed Prediction COnstrained ReiNforcement Learning
Jan 13, 2020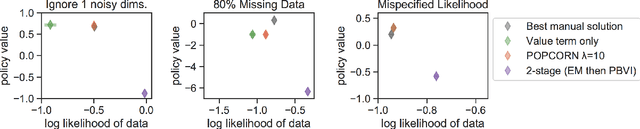
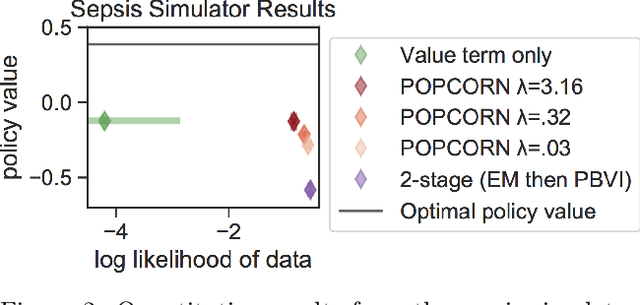

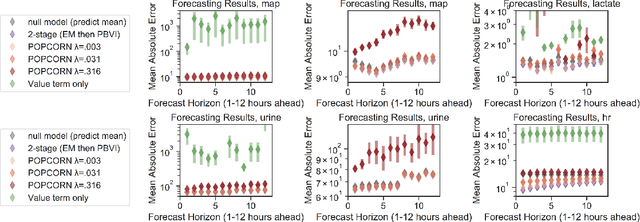
Many medical decision-making settings can be framed as partially observed Markov decision processes (POMDPs). However, popular two-stage approaches that first learn a POMDP model and then solve it often fail because the model that best fits the data may not be the best model for planning. We introduce a new optimization objective that (a) produces both high-performing policies and high-quality generative models, even when some observations are irrelevant for planning, and (b) does so in the kinds of batch, off-policy settings common in medicine. We demonstrate our approach on synthetic examples and a real-world hypotension management task.
Identifying Distinct, Effective Treatments for Acute Hypotension with SODA-RL: Safely Optimized Diverse Accurate Reinforcement Learning
Jan 09, 2020
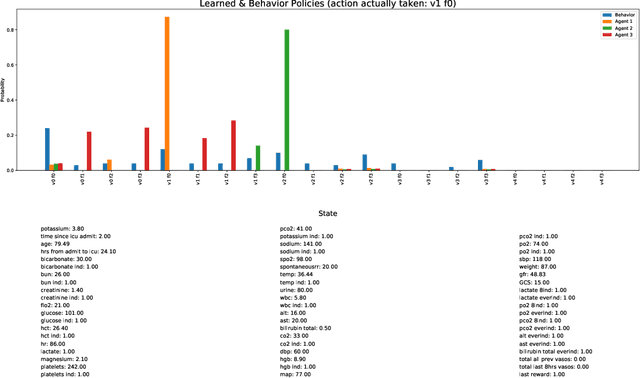
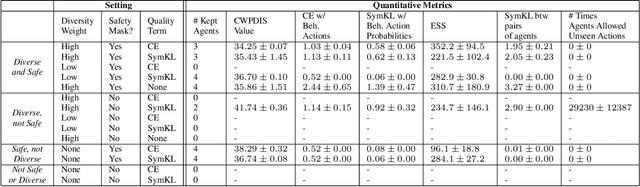
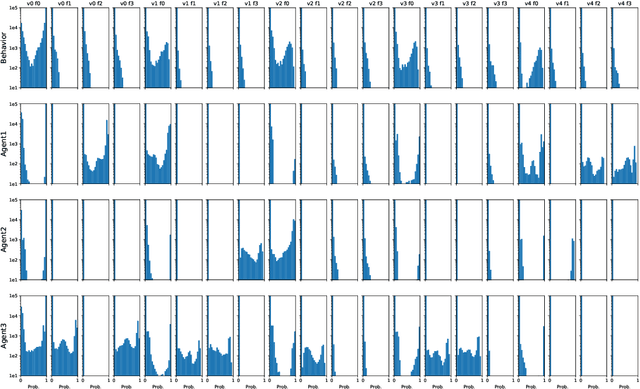
Hypotension in critical care settings is a life-threatening emergency that must be recognized and treated early. While fluid bolus therapy and vasopressors are common treatments, it is often unclear which interventions to give, in what amounts, and for how long. Observational data in the form of electronic health records can provide a source for helping inform these choices from past events, but often it is not possible to identify a single best strategy from observational data alone. In such situations, we argue it is important to expose the collection of plausible options to a provider. To this end, we develop SODA-RL: Safely Optimized, Diverse, and Accurate Reinforcement Learning, to identify distinct treatment options that are supported in the data. We demonstrate SODA-RL on a cohort of 10,142 ICU stays where hypotension presented. Our learned policies perform comparably to the observed physician behaviors, while providing different, plausible alternatives for treatment decisions.
Towards Expressive Priors for Bayesian Neural Networks: Poisson Process Radial Basis Function Networks
Dec 12, 2019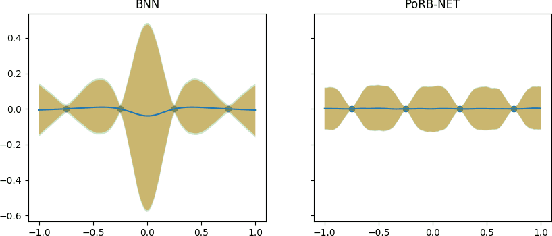
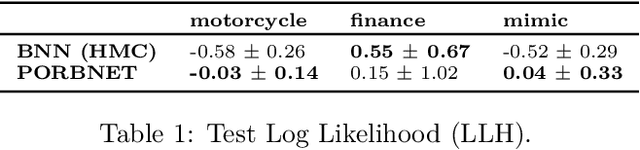
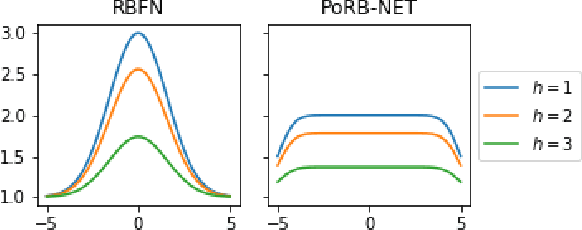
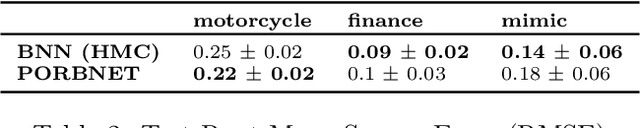
While Bayesian neural networks have many appealing characteristics, current priors do not easily allow users to specify basic properties such as expected lengthscale or amplitude variance. In this work, we introduce Poisson Process Radial Basis Function Networks, a novel prior that is able to encode amplitude stationarity and input-dependent lengthscale. We prove that our novel formulation allows for a decoupled specification of these properties, and that the estimated regression function is consistent as the number of observations tends to infinity. We demonstrate its behavior on synthetic and real examples.
Ensembles of Locally Independent Prediction Models
Nov 27, 2019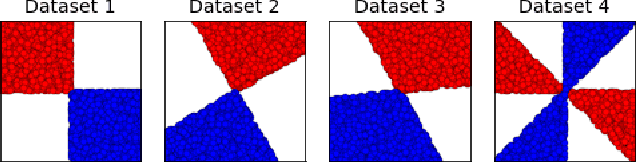
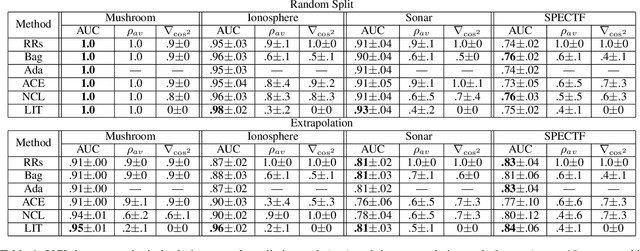
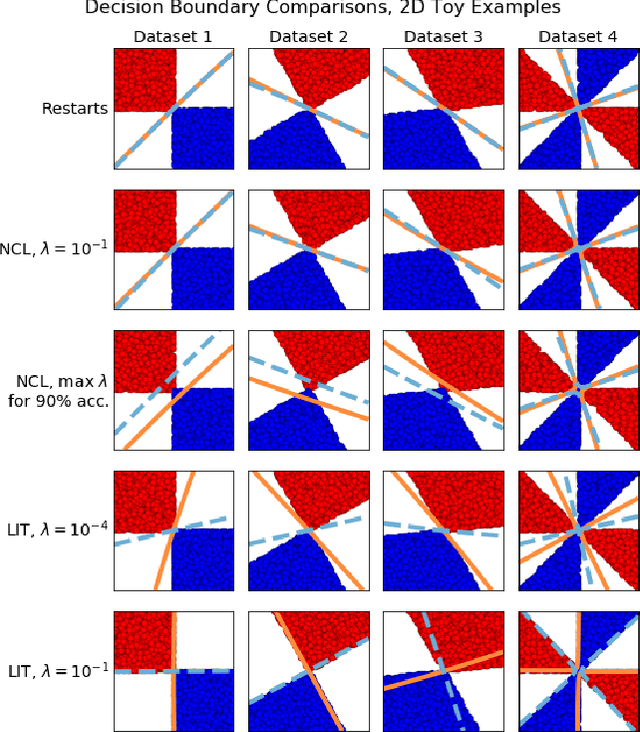
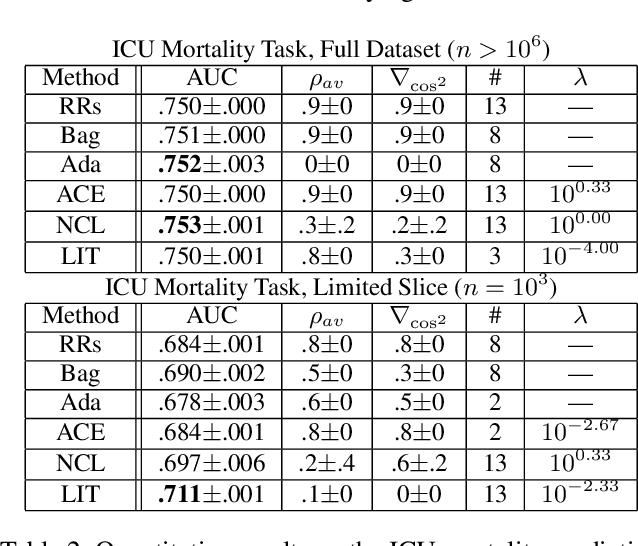
Ensembles depend on diversity for improved performance. Many ensemble training methods, therefore, attempt to optimize for diversity, which they almost always define in terms of differences in training set predictions. In this paper, however, we demonstrate the diversity of predictions on the training set does not necessarily imply diversity under mild covariate shift, which can harm generalization in practical settings. To address this issue, we introduce a new diversity metric and associated method of training ensembles of models that extrapolate differently on local patches of the data manifold. Across a variety of synthetic and real-world tasks, we find that our method improves generalization and diversity in qualitatively novel ways, especially under data limits and covariate shift.
Prediction Focused Topic Models for Electronic Health Records
Nov 15, 2019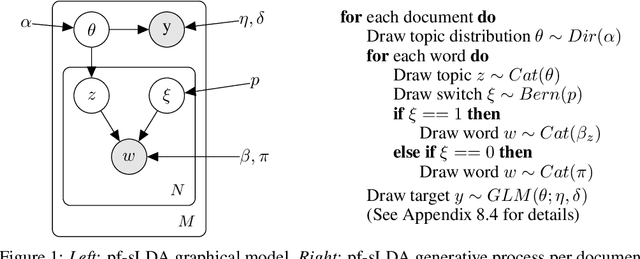
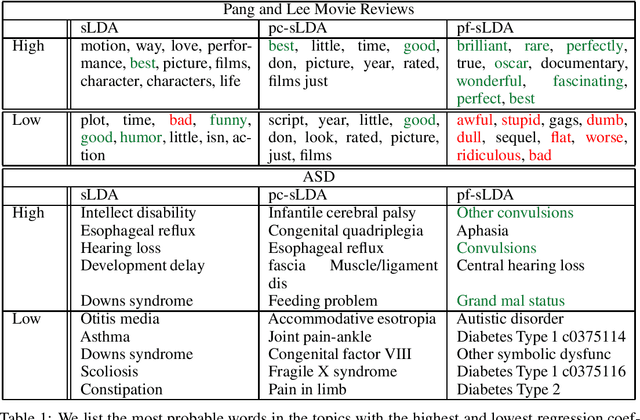
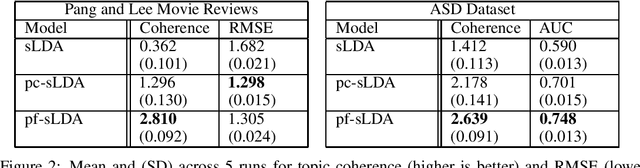
Electronic Health Record (EHR) data can be represented as discrete counts over a high dimensional set of possible procedures, diagnoses, and medications. Supervised topic models present an attractive option for incorporating EHR data as features into a prediction problem: given a patient's record, we estimate a set of latent factors that are predictive of the response variable. However, existing methods for supervised topic modeling struggle to balance prediction quality and coherence of the latent factors. We introduce a novel approach, the prediction-focused topic model, that uses the supervisory signal to retain only features that improve, or do not hinder, prediction performance. By removing features with irrelevant signal, the topic model is able to learn task-relevant, interpretable topics. We demonstrate on a EHR dataset and a movie review dataset that compared to existing approaches, prediction-focused topic models are able to learn much more coherent topics while maintaining competitive predictions.
Learning Deep Bayesian Latent Variable Regression Models that Generalize: When Non-identifiability is a Problem
Nov 01, 2019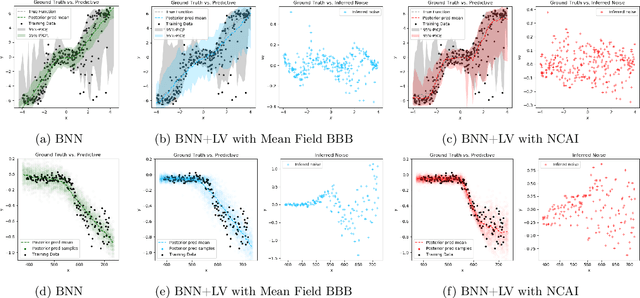

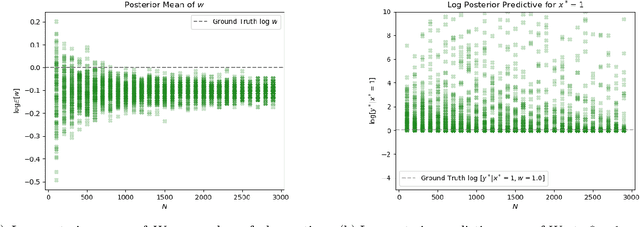

Bayesian Neural Networks with Latent Variables (BNN+LV's) provide uncertainties in prediction estimates by explicitly modeling model uncertainty (via priors on network weights) and environmental stochasticity (via a latent input noise variable). In this work, we first show that BNN+LV suffers from a serious form of non-identifiability: explanatory power can be transferred between model parameters and input noise while fitting the data equally well. We demonstrate that, as a result, traditional inference methods may yield parameters that reconstruct observed data well but generalize poorly. Next, we develop a novel inference procedure that explicitly mitigates the effects of likelihood non-identifiability during training and yields high quality predictions as well as uncertainty estimates. We demonstrate that our inference method improves upon benchmark methods across a range of synthetic and real datasets.