 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the TREC 2025 Tip-of-the-Tongue track
Jan 28, 2026Tip-of-the-tongue (ToT) known-item retrieval involves re-finding an item for which the searcher does not reliably recall an identifier. ToT information requests (or queries) are verbose and tend to include several complex phenomena, making them especially difficult for existing information retrieval systems. The TREC 2025 ToT track focused on a single ad-hoc retrieval task. This year, we extended the track to general domain and incorporated different sets of test queries from diverse sources, namely from the MS-ToT dataset, manual topic development, and LLM-based synthetic query generation. This year, 9 groups (including the track coordinators) submitted 32 runs.
Diversification as Risk Minimization
Oct 26, 2025Users tend to remember failures of a search session more than its many successes. This observation has led to work on search robustness, where systems are penalized if they perform very poorly on some queries. However, this principle of robustness has been overlooked within a single query. An ambiguous or underspecified query (e.g., ``jaguar'') can have several user intents, where popular intents often dominate the ranking, leaving users with minority intents unsatisfied. Although the diversification literature has long recognized this issue, existing metrics only model the average relevance across intents and provide no robustness guarantees. More surprisingly, we show theoretically and empirically that many well-known diversification algorithms are no more robust than a naive, non-diversified algorithm. To address this critical gap, we propose to frame diversification as a risk-minimization problem. We introduce VRisk, which measures the expected risk faced by the least-served fraction of intents in a query. Optimizing VRisk produces a robust ranking, reducing the likelihood of poor user experiences. We then propose VRisker, a fast greedy re-ranker with provable approximation guarantees. Finally, experiments on NTCIR INTENT-2, TREC Web 2012, and MovieLens show the vulnerability of existing methods. VRisker reduces worst-case intent failures by up to 33% with a minimal 2% drop in average performance.
Rigor in AI: Doing Rigorous AI Work Requires a Broader, Responsible AI-Informed Conception of Rigor
Jun 17, 2025In AI research and practice, rigor remains largely understood in terms of methodological rigor -- such as whether mathematical, statistical, or computational methods are correctly applied. We argue that this narrow conception of rigor has contributed to the concerns raised by the responsible AI community, including overblown claims about AI capabilities. Our position is that a broader conception of what rigorous AI research and practice should entail is needed. We believe such a conception -- in addition to a more expansive understanding of (1) methodological rigor -- should include aspects related to (2) what background knowledge informs what to work on (epistemic rigor); (3) how disciplinary, community, or personal norms, standards, or beliefs influence the work (normative rigor); (4) how clearly articulated the theoretical constructs under use are (conceptual rigor); (5) what is reported and how (reporting rigor); and (6) how well-supported the inferences from existing evidence are (interpretative rigor). In doing so, we also aim to provide useful language and a framework for much-needed dialogue about the AI community's work by researchers, policymakers, journalists, and other stakeholders.
LTRR: Learning To Rank Retrievers for LLMs
Jun 16, 2025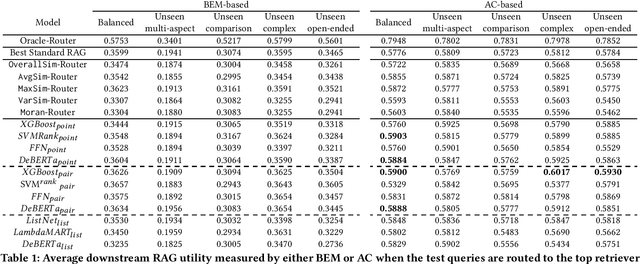
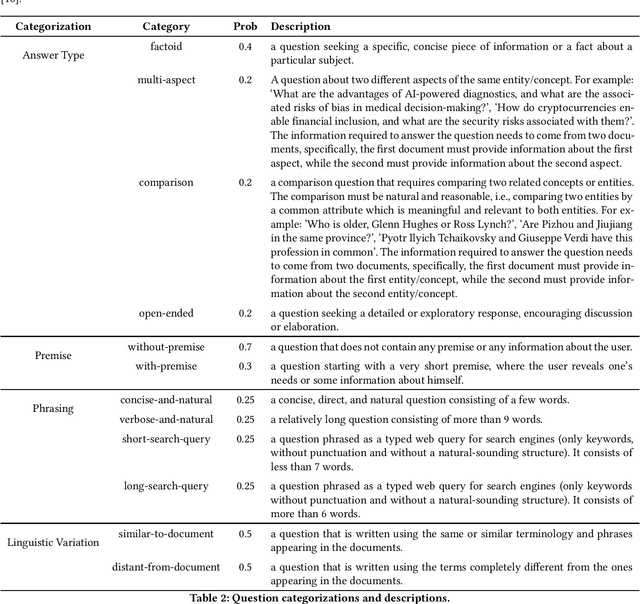
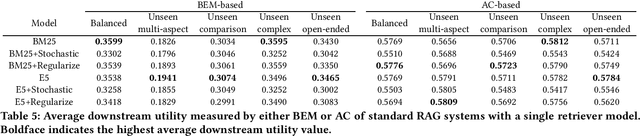
Retrieval-Augmented Generation (RAG) systems typically rely on a single fixed retriever, despite growing evidence that no single retriever performs optimally across all query types. In this paper, we explore a query routing approach that dynamically selects from a pool of retrievers based on the query, using both train-free heuristics and learned routing models. We frame routing as a learning-to-rank (LTR) problem and introduce LTRR, a framework that learns to rank retrievers by their expected utility gain to downstream LLM performance. Our experiments, conducted on synthetic QA data with controlled query type variations, show that routing-based RAG systems can outperform the best single-retriever-based systems. Performance gains are especially pronounced in models trained with the Answer Correctness (AC) metric and with pairwise learning approaches, especially with XGBoost. We also observe improvements in generalization to out-of-distribution queries. As part of the SIGIR 2025 LiveRAG challenge, our submitted system demonstrated the practical viability of our approach, achieving competitive performance in both answer correctness and faithfulness. These findings highlight the importance of both training methodology and metric selection in query routing for RAG systems.
Contextual Metric Meta-Evaluation by Measuring Local Metric Accuracy
Mar 25, 2025



Meta-evaluation of automatic evaluation metrics -- assessing evaluation metrics themselves -- is crucial for accurately benchmarking natural language processing systems and has implications for scientific inquiry, production model development, and policy enforcement. While existing approaches to metric meta-evaluation focus on general statements about the absolute and relative quality of metrics across arbitrary system outputs, in practice, metrics are applied in highly contextual settings, often measuring the performance for a highly constrained set of system outputs. For example, we may only be interested in evaluating a specific model or class of models. We introduce a method for contextual metric meta-evaluation by comparing the local metric accuracy of evaluation metrics. Across translation, speech recognition, and ranking tasks, we demonstrate that the local metric accuracies vary both in absolute value and relative effectiveness as we shift across evaluation contexts. This observed variation highlights the importance of adopting context-specific metric evaluations over global ones.
Tip of the Tongue Query Elicitation for Simulated Evaluation
Feb 25, 2025



Tip-of-the-tongue (TOT) search occurs when a user struggles to recall a specific identifier, such as a document title. While common, existing search systems often fail to effectively support TOT scenarios. Research on TOT retrieval is further constrained by the challenge of collecting queries, as current approaches rely heavily on community question-answering (CQA) websites, leading to labor-intensive evaluation and domain bias. To overcome these limitations, we introduce two methods for eliciting TOT queries - leveraging large language models (LLMs) and human participants - to facilitate simulated evaluations of TOT retrieval systems. Our LLM-based TOT user simulator generates synthetic TOT queries at scale, achieving high correlations with how CQA-based TOT queries rank TOT retrieval systems when tested in the Movie domain. Additionally, these synthetic queries exhibit high linguistic similarity to CQA-derived queries. For human-elicited queries, we developed an interface that uses visual stimuli to place participants in a TOT state, enabling the collection of natural queries. In the Movie domain, system rank correlation and linguistic similarity analyses confirm that human-elicited queries are both effective and closely resemble CQA-based queries. These approaches reduce reliance on CQA-based data collection while expanding coverage to underrepresented domains, such as Landmark and Person. LLM-elicited queries for the Movie, Landmark, and Person domains have been released as test queries in the TREC 2024 TOT track, with human-elicited queries scheduled for inclusion in the TREC 2025 TOT track. Additionally, we provide source code for synthetic query generation and the human query collection interface, along with curated visual stimuli used for eliciting TOT queries.
Offline Evaluation of Set-Based Text-to-Image Generation
Oct 22, 2024Text-to-Image (TTI) systems often support people during ideation, the early stages of a creative process when exposure to a broad set of relevant images can help explore the design space. Since ideation is an important subclass of TTI tasks, understanding how to quantitatively evaluate TTI systems according to how well they support ideation is crucial to promoting research and development for these users. However, existing evaluation metrics for TTI remain focused on distributional similarity metrics like Fr\'echet Inception Distance (FID). We take an alternative approach and, based on established methods from ranking evaluation, develop TTI evaluation metrics with explicit models of how users browse and interact with sets of spatially arranged generated images. Our proposed offline evaluation metrics for TTI not only capture how relevant generated images are with respect to the user's ideation need but also take into consideration the diversity and arrangement of the set of generated images. We analyze our proposed family of TTI metrics using human studies on image grids generated by three different TTI systems based on subsets of the widely used benchmarks such as MS-COCO captions and Localized Narratives as well as prompts used in naturalistic settings. Our results demonstrate that grounding metrics in how people use systems is an important and understudied area of benchmark design.
Pessimistic Evaluation
Oct 17, 2024



Traditional evaluation of information access systems has focused primarily on average utility across a set of information needs (information retrieval) or users (recommender systems). In this work, we argue that evaluating only with average metric measurements assumes utilitarian values not aligned with traditions of information access based on equal access. We advocate for pessimistic evaluation of information access systems focusing on worst case utility. These methods are (a) grounded in ethical and pragmatic concepts, (b) theoretically complementary to existing robustness and fairness methods, and (c) empirically validated across a set of retrieval and recommendation tasks. These results suggest that pessimistic evaluation should be included in existing experimentation processes to better understand the behavior of systems, especially when concerned with principles of social good.
Towards Fair RAG: On the Impact of Fair Ranking in Retrieval-Augmented Generation
Sep 17, 2024



Many language models now enhance their responses with retrieval capabilities, leading to the widespread adoption of retrieval-augmented generation (RAG) systems. However, despite retrieval being a core component of RAG, much of the research in this area overlooks the extensive body of work on fair ranking, neglecting the importance of considering all stakeholders involved. This paper presents the first systematic evaluation of RAG systems integrated with fair rankings. We focus specifically on measuring the fair exposure of each relevant item across the rankings utilized by RAG systems (i.e., item-side fairness), aiming to promote equitable growth for relevant item providers. To gain a deep understanding of the relationship between item-fairness, ranking quality, and generation quality in the context of RAG, we analyze nine different RAG systems that incorporate fair rankings across seven distinct datasets. Our findings indicate that RAG systems with fair rankings can maintain a high level of generation quality and, in many cases, even outperform traditional RAG systems, despite the general trend of a tradeoff between ensuring fairness and maintaining system-effectiveness. We believe our insights lay the groundwork for responsible and equitable RAG systems and open new avenues for future research. We publicly release our codebase and dataset at https://github.com/kimdanny/Fair-RAG.
Retrieval-Enhanced Machine Learning: Synthesis and Opportunities
Jul 17, 2024



In the field of language modeling, models augmented with retrieval components have emerged as a promising solution to address several challenges faced in the natural language processing (NLP) field, including knowledge grounding, interpretability, and scalability. Despite the primary focus on NLP, we posit that the paradigm of retrieval-enhancement can be extended to a broader spectrum of machine learning (ML) such as computer vision, time series prediction, and computational biology. Therefore, this work introduces a formal framework of this paradigm, Retrieval-Enhanced Machine Learning (REML), by synthesizing the literature in various domains in ML with consistent notations which is missing from the current literature. Also, we found that while a number of studies employ retrieval components to augment their models, there is a lack of integration with foundational Information Retrieval (IR) research. We bridge this gap between the seminal IR research and contemporary REML studies by investigating each component that comprises the REML framework. Ultimately, the goal of this work is to equip researchers across various disciplines with a comprehensive, formally structured framework of retrieval-enhanced models, thereby fostering interdisciplinary future research.