 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight-Weight RetinaNet for Object Detection
May 24, 2019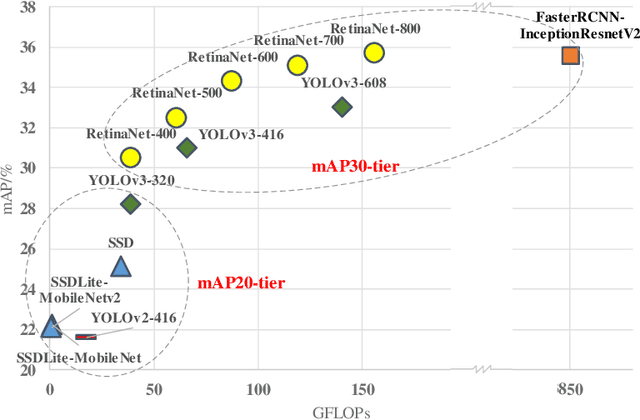
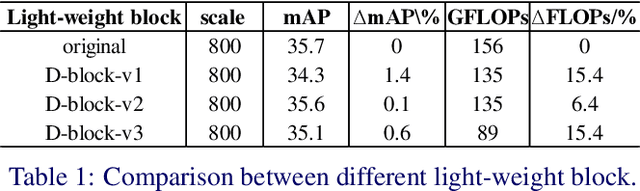
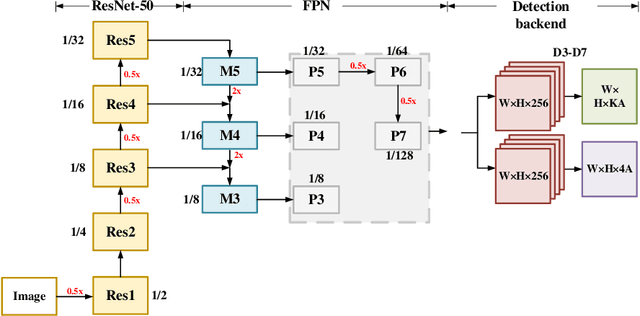
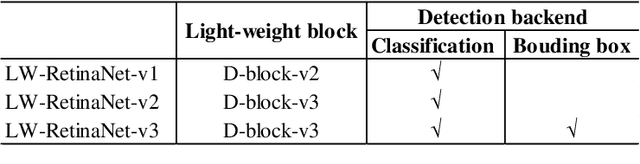
Object detection has gained great progress driven by the development of deep learning. Compared with a widely studied task -- classification, generally speaking, object detection even need one or two orders of magnitude more FLOPs (floating point operations) in processing the inference task. To enable a practical application, it is essential to explore effective runtime and accuracy trade-off scheme. Recently, a growing number of studies are intended for object detection on resource constraint devices, such as YOLOv1, YOLOv2, SSD, MobileNetv2-SSDLite, whose accuracy on COCO test-dev detection results are yield to mAP around 22-25% (mAP-20-tier). On the contrary, very few studies discuss the computation and accuracy trade-off scheme for mAP-30-tier detection networks. In this paper, we illustrate the insights of why RetinaNet gives effective computation and accuracy trade-off for object detection and how to build a light-weight RetinaNet. We propose to only reduce FLOPs in computational intensive layers and keep other layer the same. Compared with most common way -- input image scaling for FLOPs-accuracy trade-off, the proposed solution shows a constantly better FLOPs-mAP trade-off line. Quantitatively, the proposed method result in 0.1% mAP improvement at 1.15x FLOPs reduction and 0.3% mAP improvement at 1.8x FLOPs reduction.
LAPRAN: A Scalable Laplacian Pyramid Reconstructive Adversarial Network for Flexible Compressive Sensing Reconstruction
Nov 03, 2018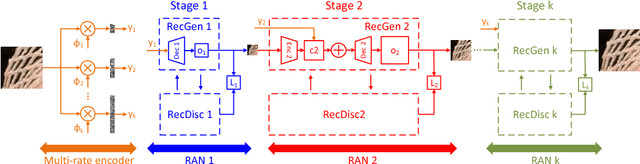

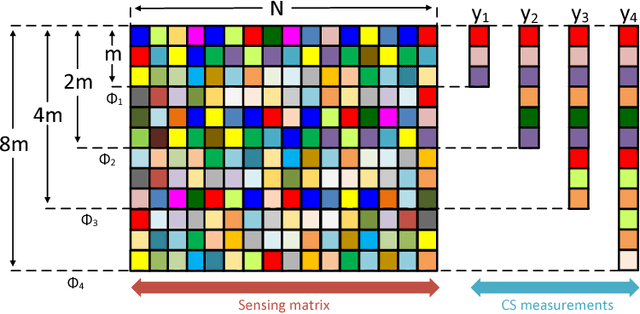
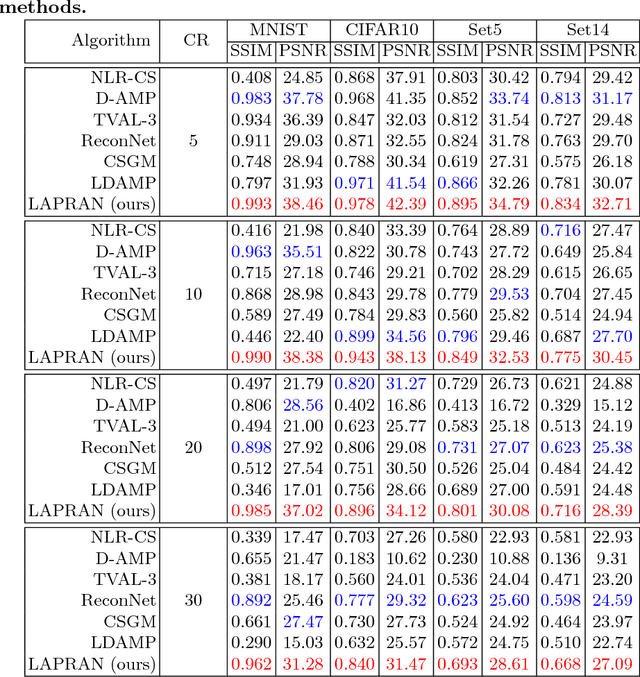
This paper addresses the single-image compressive sensing (CS) and reconstruction problem. We propose a scalable Laplacian pyramid reconstructive adversarial network (LAPRAN) that enables high-fidelity, flexible and fast CS images reconstruction. LAPRAN progressively reconstructs an image following the concept of Laplacian pyramid through multiple stages of reconstructive adversarial networks (RANs). At each pyramid level, CS measurements are fused with a contextual latent vector to generate a high-frequency image residual. Consequently, LAPRAN can produce hierarchies of reconstructed images and each with an incremental resolution and improved quality. The scalable pyramid structure of LAPRAN enables high-fidelity CS reconstruction with a flexible resolution that is adaptive to a wide range of compression ratios (CRs), which is infeasible with existing methods. Experimental results on multiple public datasets show that LAPRAN offers an average 7.47dB and 5.98dB PSNR, and an average 57.93% and 33.20% SSIM improvement compared to model-based and data-driven baselines, respectively.
Build a Compact Binary Neural Network through Bit-level Sensitivity and Data Pruning
Feb 03, 2018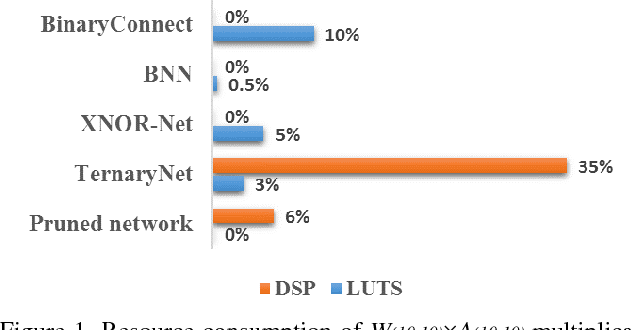
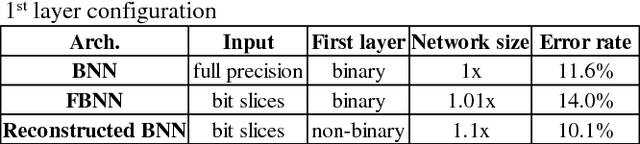
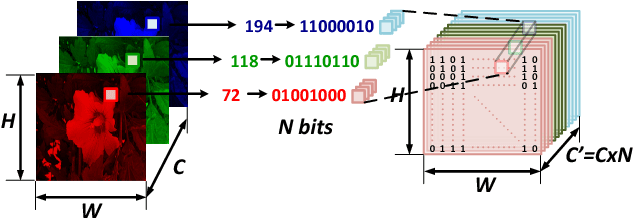
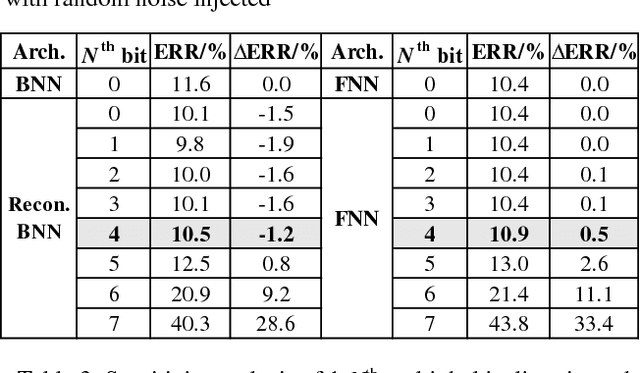
Convolutional neural network (CNN) has been widely used for vision-based tasks. Due to the high computational complexity and memory storage requirement, it is hard to directly deploy a full-precision CNN on embedded devices. The hardware-friendly designs are needed for re-source-limited and energy-constrained embed-ded devices. Emerging solutions are adopted for the neural network compression, e.g., bina-ry/ternary weight network, pruned network and quantized network. Among them, Binarized Neural Network (BNN) is believed to be the most hardware-friendly framework due to its small network size and low computational com-plexity. No existing work has further shrunk the size of BNN. In this work, we explore the redun-dancy in BNN and build a compact BNN (CBNN) based on the bit-level sensitivity analy-sis and bit-level data pruning. The input data is converted to a high dimensional bit-sliced for-mat. In post-training stage, we analyze the im-pact of different bit slices to the accuracy. By pruning the redundant input bit slices and shrinking the network size, we are able to build a more compact BNN. Our result shows that we can further scale down the network size of the BNN up to 3.9x with no more than 1% accuracy drop. The actual runtime can be reduced up to 2x and 9.9x compared with the baseline BNN and its full-precision counterpart, respectively.
CSVideoNet: A Real-time End-to-end Learning Framework for High-frame-rate Video Compressive Sensing
Jan 28, 2018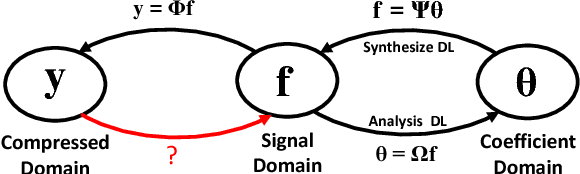
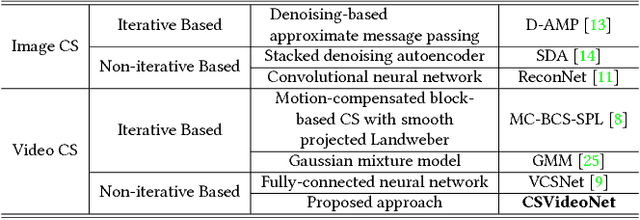
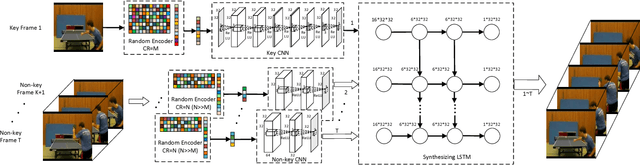
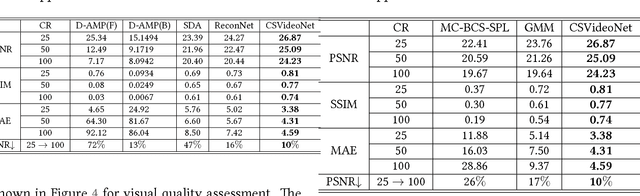
This paper addresses the real-time encoding-decoding problem for high-frame-rate video compressive sensing (CS). Unlike prior works that perform reconstruction using iterative optimization-based approaches, we propose a non-iterative model, named "CSVideoNet". CSVideoNet directly learns the inverse mapping of CS and reconstructs the original input in a single forward propagation. To overcome the limitations of existing CS cameras, we propose a multi-rate CNN and a synthesizing RNN to improve the trade-off between compression ratio (CR) and spatial-temporal resolution of the reconstructed videos. The experiment results demonstrate that CSVideoNet significantly outperforms the state-of-the-art approaches. With no pre/post-processing, we achieve 25dB PSNR recovery quality at 100x CR, with a frame rate of 125 fps on a Titan X GPU. Due to the feedforward and high-data-concurrency natures of CSVideoNet, it can take advantage of GPU acceleration to achieve three orders of magnitude speed-up over conventional iterative-based approaches. We share the source code at https://github.com/PSCLab-ASU/CSVideoNet.
A GPU-Outperforming FPGA Accelerator Architecture for Binary Convolutional Neural Networks
Jun 08, 2017

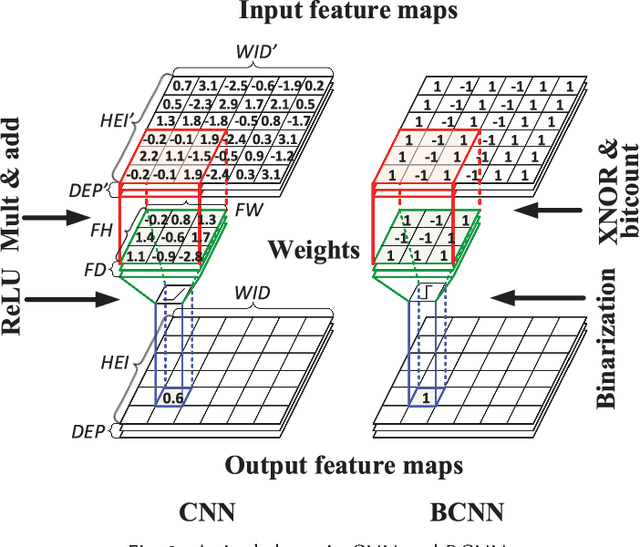
FPGA-based hardware accelerators for convolutional neural networks (CNNs) have obtained great attentions due to their higher energy efficiency than GPUs. However, it is challenging for FPGA-based solutions to achieve a higher throughput than GPU counterparts. In this paper, we demonstrate that FPGA acceleration can be a superior solution in terms of both throughput and energy efficiency when a CNN is trained with binary constraints on weights and activations. Specifically, we propose an optimized FPGA accelerator architecture tailored for bitwise convolution and normalization that features massive spatial parallelism with deep pipelines stages. A key advantage of the FPGA accelerator is that its performance is insensitive to data batch size, while the performance of GPU acceleration varies largely depending on the batch size of the data. Experiment results show that the proposed accelerator architecture for binary CNNs running on a Virtex-7 FPGA is 8.3x faster and 75x more energy-efficient than a Titan X GPU for processing online individual requests in small batch sizes. For processing static data in large batch sizes, the proposed solution is on a par with a Titan X GPU in terms of throughput while delivering 9.5x higher energy efficiency.
A Data-Driven Compressive Sensing Framework Tailored For Energy-Efficient Wearable Sensing
Dec 16, 2016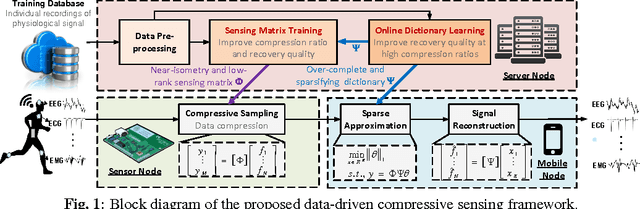
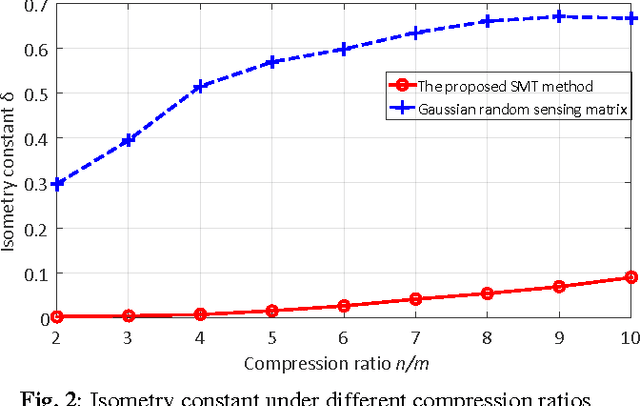
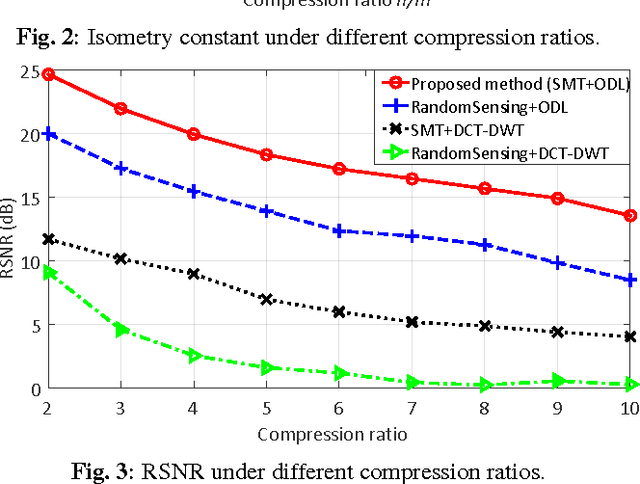
Compressive sensing (CS) is a promising technology for realizing energy-efficient wireless sensors for long-term health monitoring. However, conventional model-driven CS frameworks suffer from limited compression ratio and reconstruction quality when dealing with physiological signals due to inaccurate models and the overlook of individual variability. In this paper, we propose a data-driven CS framework that can learn signal characteristics and personalized features from any individual recording of physiologic signals to enhance CS performance with a minimized number of measurements. Such improvements are accomplished by a co-training approach that optimizes the sensing matrix and the dictionary towards improved restricted isometry property and signal sparsity, respectively. Experimental results upon ECG signals show that the proposed method, at a compression ratio of 10x, successfully reduces the isometry constant of the trained sensing matrices by 86% against random matrices and improves the overall reconstructed signal-to-noise ratio by 15dB over conventional model-driven approaches.
A Binary Convolutional Encoder-decoder Network for Real-time Natural Scene Text Processing
Dec 12, 2016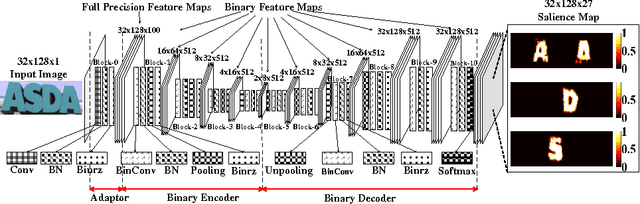
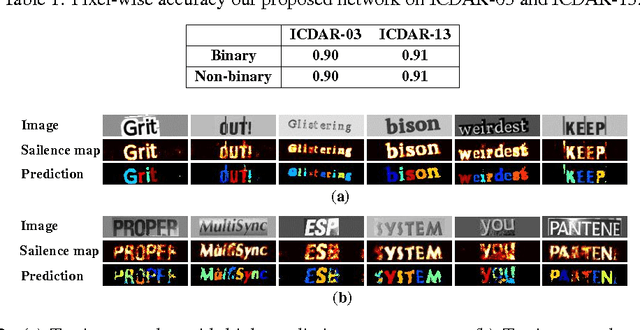
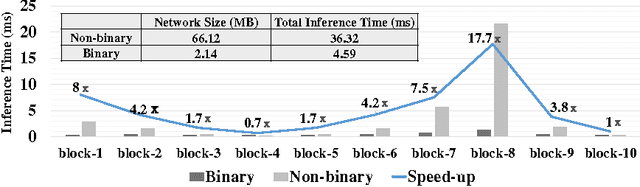
In this paper, we develop a binary convolutional encoder-decoder network (B-CEDNet) for natural scene text processing (NSTP). It converts a text image to a class-distinguished salience map that reveals the categorical, spatial and morphological information of characters. The existing solutions are either memory consuming or run-time consuming that cannot be applied to real-time applications on resource-constrained devices such as advanced driver assistance systems. The developed network can process multiple regions containing characters by one-off forward operation, and is trained to have binary weights and binary feature maps, which lead to both remarkable inference run-time speedup and memory usage reduction. By training with over 200, 000 synthesis scene text images (size of $32\times128$), it can achieve $90\%$ and $91\%$ pixel-wise accuracy on ICDAR-03 and ICDAR-13 datasets. It only consumes $4.59\ ms$ inference run-time realized on GPU with a small network size of 2.14 MB, which is up to $8\times$ faster and $96\%$ smaller than it full-precision version.