 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy Label Learning for Large-scale Medical Image Classification
Mar 06, 2021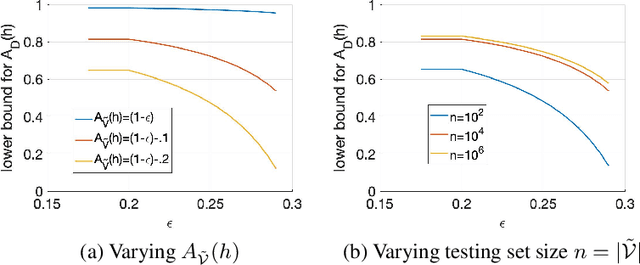
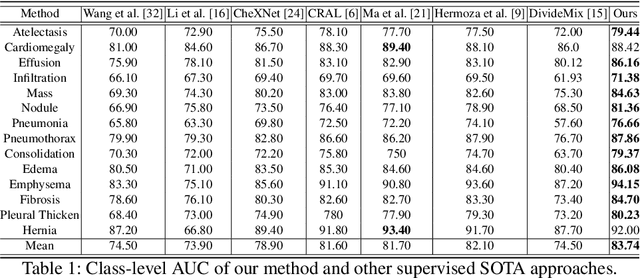
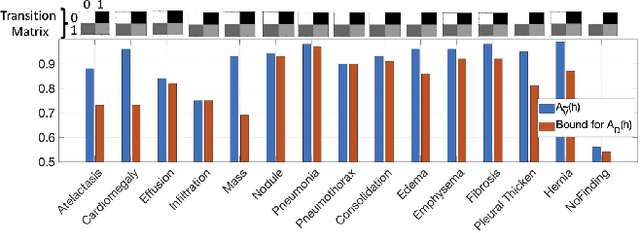

The classification accuracy of deep learning models depends not only on the size of their training sets, but also on the quality of their labels. In medical image classification, large-scale datasets are becoming abundant, but their labels will be noisy when they are automatically extracted from radiology reports using natural language processing tools. Given that deep learning models can easily overfit these noisy-label samples, it is important to study training approaches that can handle label noise. In this paper, we adapt a state-of-the-art (SOTA) noisy-label multi-class training approach to learn a multi-label classifier for the dataset Chest X-ray14, which is a large scale dataset known to contain label noise in the training set. Given that this dataset also has label noise in the testing set, we propose a new theoretically sound method to estimate the performance of the model on a hidden clean testing data, given the result on the noisy testing data. Using our clean data performance estimation, we notice that the majority of label noise on Chest X-ray14 is present in the class 'No Finding', which is intuitively correct because this is the most likely class to contain one or more of the 14 diseases due to labelling mistakes.
Self-supervised Mean Teacher for Semi-supervised Chest X-ray Classification
Mar 05, 2021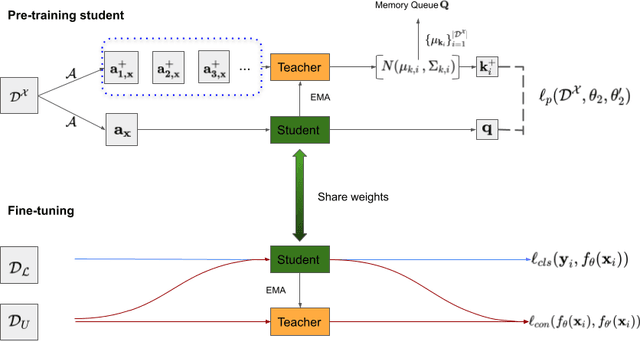
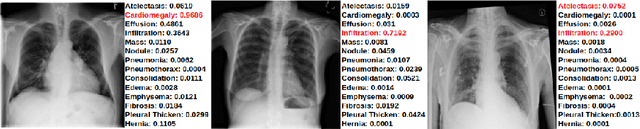
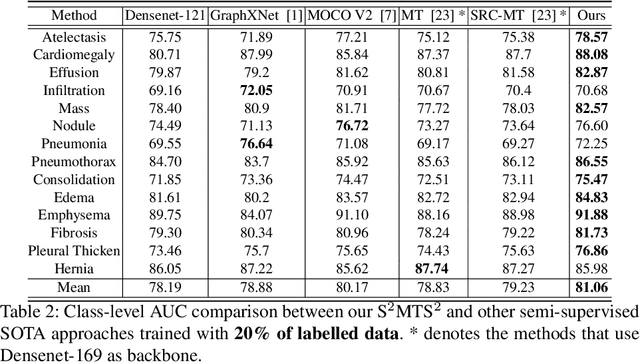
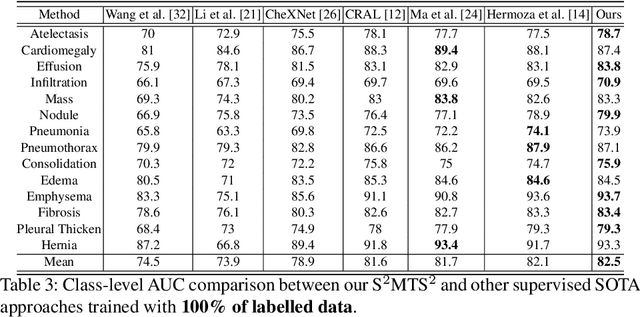
The training of deep learning models generally requires a large amount of annotated data for effective convergence and generalisation. However, obtaining high-quality annotations is a laboursome and expensive process due to the need of expert radiologists for the labelling task. The study of semi-supervised learning in medical image analysis is then of crucial importance given that it is much less expensive to obtain unlabelled images than to acquire images labelled by expert radiologists.Essentially, semi-supervised methods leverage large sets of unlabelled data to enable better training convergence and generalisation than if we use only the small set of labelled images.In this paper, we propose the Self-supervised Mean Teacher for Semi-supervised (S$^2$MTS$^2$) learning that combines self-supervised mean-teacher pre-training with semi-supervised fine-tuning. The main innovation of S$^2$MTS$^2$ is the self-supervised mean-teacher pre-training based on the joint contrastive learning, which uses an infinite number of pairs of positive query and key features to improve the mean-teacher representation. The model is then fine-tuned using the exponential moving average teacher framework trained with semi-supervised learning.We validate S$^2$MTS$^2$ on the thorax disease multi-label classification problem from the dataset Chest X-ray14, where we show that it outperforms the previous SOTA semi-supervised learning methods by a large margin.
Constrained Contrastive Distribution Learning for Unsupervised Anomaly Detection and Localisation in Medical Images
Mar 05, 2021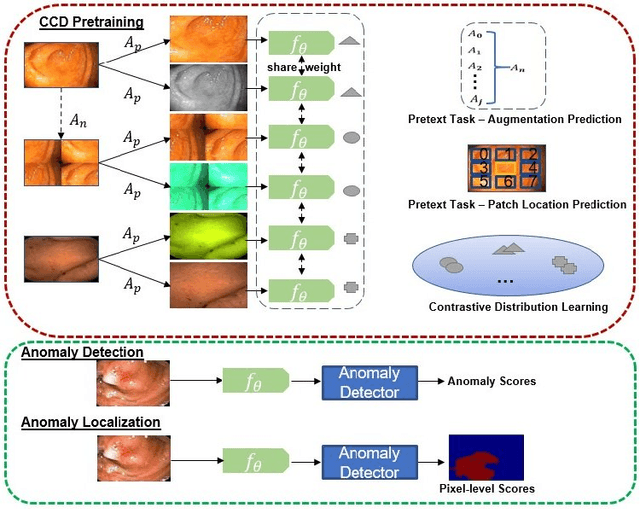
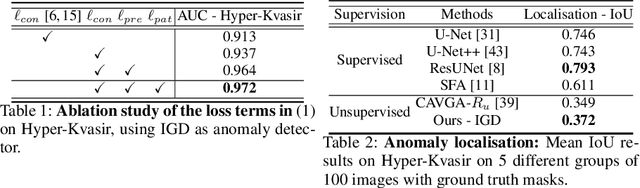
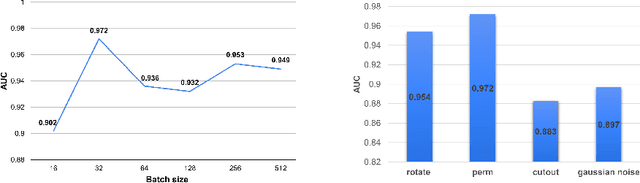
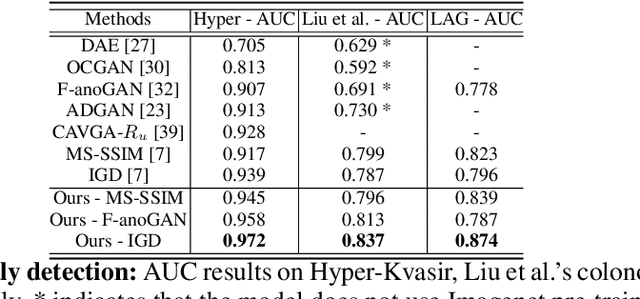
Unsupervised anomaly detection (UAD) learns one-class classifiers exclusively with normal (i.e., healthy) images to detect any abnormal (i.e., unhealthy) samples that do not conform to the expected normal patterns. UAD has two main advantages over its fully supervised counterpart. Firstly, it is able to directly leverage large datasets available from health screening programs that contain mostly normal image samples, avoiding the costly manual labelling of abnormal samples and the subsequent issues involved in training with extremely class-imbalanced data. Further, UAD approaches can potentially detect and localise any type of lesions that deviate from the normal patterns. One significant challenge faced by UAD methods is how to learn effective low-dimensional image representations to detect and localise subtle abnormalities, generally consisting of small lesions. To address this challenge, we propose a novel self-supervised representation learning method, called Constrained Contrastive Distribution learning for anomaly detection (CCD), which learns fine-grained feature representations by simultaneously predicting the distribution of augmented data and image contexts using contrastive learning with pretext constraints. The learned representations can be leveraged to train more anomaly-sensitive detection models. Extensive experiment results show that our method outperforms current state-of-the-art UAD approaches on three different colonoscopy and fundus screening datasets. Our code is available at https://github.com/tianyu0207/CCD.
Self-supervised Depth Estimation to Regularise Semantic Segmentation in Knee Arthroscopy
Jul 05, 2020
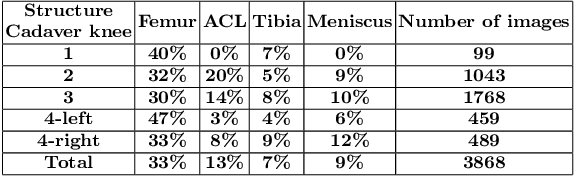
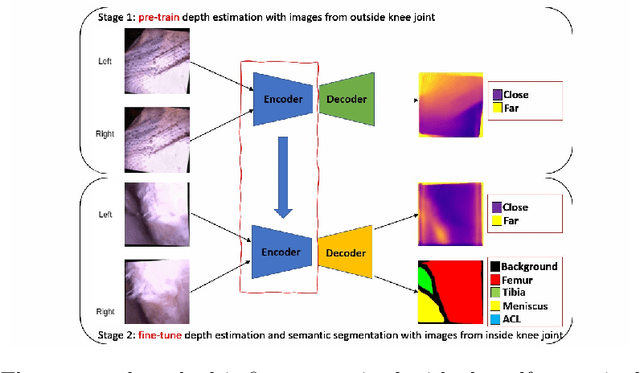
Intra-operative automatic semantic segmentation of knee joint structures can assist surgeons during knee arthroscopy in terms of situational awareness. However, due to poor imaging conditions (e.g., low texture, overexposure, etc.), automatic semantic segmentation is a challenging scenario, which justifies the scarce literature on this topic. In this paper, we propose a novel self-supervised monocular depth estimation to regularise the training of the semantic segmentation in knee arthroscopy. To further regularise the depth estimation, we propose the use of clean training images captured by the stereo arthroscope of routine objects (presenting none of the poor imaging conditions and with rich texture information) to pre-train the model. We fine-tune such model to produce both the semantic segmentation and self-supervised monocular depth using stereo arthroscopic images taken from inside the knee. Using a data set containing 3868 arthroscopic images captured during cadaveric knee arthroscopy with semantic segmentation annotations, 2000 stereo image pairs of cadaveric knee arthroscopy, and 2150 stereo image pairs of routine objects, we show that our semantic segmentation regularised by self-supervised depth estimation produces a more accurate segmentation than a state-of-the-art semantic segmentation approach modeled exclusively with semantic segmentation annotation.