 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePmeta-TLA: Backdoor Attacks for Speech Classification Models via Meta-Learning with Timbre Leakage Attack
Jul 02, 2026Recently, speech classification methods have gained widespread adoption in intelligent gadgets. Current study indicates that backdoor attacks provide a substantial security concern to these models, underscoring the pressing necessity to investigate additional potential attack techniques to expose and prevent such risks. This work discusses the vulnerability of current speech triggers to detection by deep neural network defenders and introduces the Timbre Leakage Attack (TLA). The suggested trigger disseminates timbre information at the frame level within the deep self-supervised features, producing poisoned samples that appear natural to human perception. Furthermore, we introduce Pmeta-TLA, an innovative training mechanism for embedding numerous backdoors one time. This method proposes a multi-backdoor injection training strategy using meta-learning and Projected Conflicting Gradients (PCGrad) and introduces TLA as a multi-target attack tool within it. We performed tests on data-poisoning backdoor attacks in keyword spotting tasks utilizing some deep neural network models. Experimental results indicate that the proposed strategy attains superior Attack efficacy, enhanced stealthiness, robustness, and a reduced attack cost relative to baseline methods.
DRL-CLBA: A Clean Label Backdoor Attack for Speech Classification via DDPG Reinforcement Learning
Jul 02, 2026Deep learning models for speech classification are vulnerable to backdoor attacks, where malicious triggers cause misclassification at inference time. While sample-specific attacks can bypass many defenses, they often rely on poisoned label attack, making them detectable via manual data defense. In this paper, we propose DRL-CLBA, a novel clean label backdoor attack for speech classification that leverages Deep Deterministic Policy Gradient (DDPG) reinforcement learning. We also utilize deep audio steganography to embed sample-specific triggers into source audio, creating feature-space anchors. The proposed reinforcement learning framework effectively optimizes target samples toward trigger-bearing anchor points in the model's deep latent space, enabling label-migration-free poisoning of target samples. Experimental results across three datasets and four different DNNs demonstrate that DRL-CLBA achieves a high attack success rate, effectively bypassing some backdoor defenses. The attack demonstrates strong resistance against fine-tuning, pruning, and spectral signature defenses, exposing critical vulnerabilities in speech-controlled systems.
No Prompt, No Leaks: A Robust Generative Steganography Framework via Prompt-Free Diffusion
Jun 30, 2026Generative image steganography synthesizes stego images directly from secret information to achieve inherent security advantages. Latent Diffusion Models (LDMs) have recently emerged as a fundamental image steganography framework that modulates secret latent representations with text prompts. Limited by the inflexibility of text prompts, these methods still struggle to generate high-quality stego images and accurately recover secret images. In this work, we propose a prompt-free diffusion image steganography framework that integrates style semantic priors to control more robust and reliable stego image generation. Specifically, a Cascaded Affine Coupling Module (CACM) establishes a bijective, deterministic mapping between a secret image and its latent representation. Then, style semantics are integrated into the diffusion process to control latent representation and ensure visual imperceptibility in the generated stego images. To mitigate trajectory deviations stemming from the unconditioned reverse process, a predictor-corrector mechanism is introduced to iteratively refine the generation trajectory via feedback from the current and predicted next states. Extensive experimental results show that the proposed method achieves competitive performance compared to state-of-the-art methods in terms of security, secret image reconstruction accuracy and controllability.
Focus-to-Perceive Representation Learning: A Cognition-Inspired Hierarchical Framework for Endoscopic Video Analysis
Mar 26, 2026Endoscopic video analysis is essential for early gastrointestinal screening but remains hindered by limited high-quality annotations. While self-supervised video pre-training shows promise, existing methods developed for natural videos prioritize dense spatio-temporal modeling and exhibit motion bias, overlooking the static, structured semantics critical to clinical decision-making. To address this challenge, we propose Focus-to-Perceive Representation Learning (FPRL), a cognition-inspired hierarchical framework that emulates clinical examination. FPRL first focuses on intra-frame lesion-centric regions to learn static semantics, and then perceives their evolution across frames to model contextual semantics. To achieve this, FPRL employs a hierarchical semantic modeling mechanism that explicitly distinguishes and collaboratively learns both types of semantics. Specifically, it begins by capturing static semantics via teacher-prior adaptive masking (TPAM) combined with multi-view sparse sampling. This approach mitigates redundant temporal dependencies and enables the model to concentrate on lesion-related local semantics. Following this, contextual semantics are derived through cross-view masked feature completion (CVMFC) and attention-guided temporal prediction (AGTP). These processes establish cross-view correspondences and effectively model structured inter-frame evolution, thereby reinforcing temporal semantic continuity while preserving global contextual integrity. Extensive experiments on 11 endoscopic video datasets show that FPRL achieves superior performance across diverse downstream tasks, demonstrating its effectiveness in endoscopic video representation learning. The code is available at https://github.com/MLMIP/FPRL.
Pureformer-VC: Non-parallel Voice Conversion with Pure Stylized Transformer Blocks and Triplet Discriminative Training
Jun 10, 2025As a foundational technology for intelligent human-computer interaction, voice conversion (VC) seeks to transform speech from any source timbre into any target timbre. Traditional voice conversion methods based on Generative Adversarial Networks (GANs) encounter significant challenges in precisely encoding diverse speech elements and effectively synthesising these elements into natural-sounding converted speech. To overcome these limitations, we introduce Pureformer-VC, an encoder-decoder framework that utilizes Conformer blocks to build a disentangled encoder and employs Zipformer blocks to create a style transfer decoder. We adopt a variational decoupled training approach to isolate speech components using a Variational Autoencoder (VAE), complemented by triplet discriminative training to enhance the speaker's discriminative capabilities. Furthermore, we incorporate the Attention Style Transfer Mechanism (ASTM) with Zipformer's shared weights to improve the style transfer performance in the decoder. We conducted experiments on two multi-speaker datasets. The experimental results demonstrate that the proposed model achieves comparable subjective evaluation scores while significantly enhancing objective metrics compared to existing approaches in many-to-many and many-to-one VC scenarios.
SPBA: Utilizing Speech Large Language Model for Backdoor Attacks on Speech Classification Models
Jun 10, 2025Deep speech classification tasks, including keyword spotting and speaker verification, are vital in speech-based human-computer interaction. Recently, the security of these technologies has been revealed to be susceptible to backdoor attacks. Specifically, attackers use noisy disruption triggers and speech element triggers to produce poisoned speech samples that train models to become vulnerable. However, these methods typically create only a limited number of backdoors due to the inherent constraints of the trigger function. In this paper, we propose that speech backdoor attacks can strategically focus on speech elements such as timbre and emotion, leveraging the Speech Large Language Model (SLLM) to generate diverse triggers. Increasing the number of triggers may disproportionately elevate the poisoning rate, resulting in higher attack costs and a lower success rate per trigger. We introduce the Multiple Gradient Descent Algorithm (MGDA) as a mitigation strategy to address this challenge. The proposed attack is called the Speech Prompt Backdoor Attack (SPBA). Building on this foundation, we conducted attack experiments on two speech classification tasks, demonstrating that SPBA shows significant trigger effectiveness and achieves exceptional performance in attack metrics.
MSDNN: Multi-Scale Deep Neural Network for Salient Object Detection
Jan 12, 2018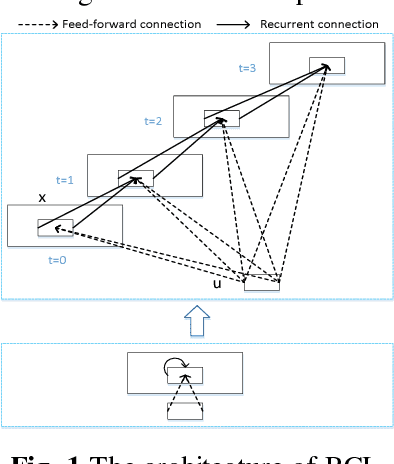
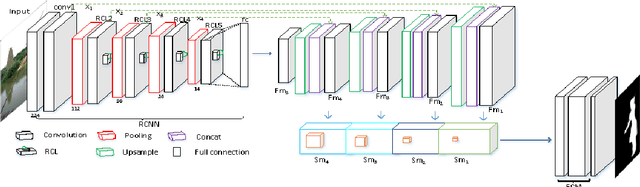
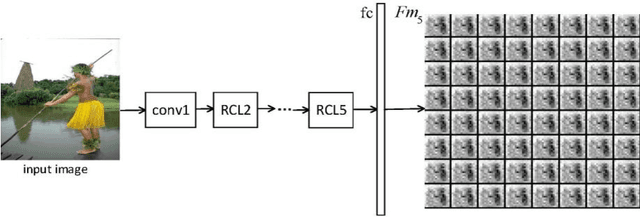

Salient object detection is a fundamental problem and has been received a great deal of attentions in computer vision. Recently deep learning model became a powerful tool for image feature extraction. In this paper, we propose a multi-scale deep neural network (MSDNN) for salient object detection. The proposed model first extracts global high-level features and context information over the whole source image with recurrent convolutional neural network (RCNN). Then several stacked deconvolutional layers are adopted to get the multi-scale feature representation and obtain a series of saliency maps. Finally, we investigate a fusion convolution module (FCM) to build a final pixel level saliency map. The proposed model is extensively evaluated on four salient object detection benchmark datasets. Results show that our deep model significantly outperforms other 12 state-of-the-art approaches.