 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus-to-Perceive Representation Learning: A Cognition-Inspired Hierarchical Framework for Endoscopic Video Analysis
Mar 26, 2026Endoscopic video analysis is essential for early gastrointestinal screening but remains hindered by limited high-quality annotations. While self-supervised video pre-training shows promise, existing methods developed for natural videos prioritize dense spatio-temporal modeling and exhibit motion bias, overlooking the static, structured semantics critical to clinical decision-making. To address this challenge, we propose Focus-to-Perceive Representation Learning (FPRL), a cognition-inspired hierarchical framework that emulates clinical examination. FPRL first focuses on intra-frame lesion-centric regions to learn static semantics, and then perceives their evolution across frames to model contextual semantics. To achieve this, FPRL employs a hierarchical semantic modeling mechanism that explicitly distinguishes and collaboratively learns both types of semantics. Specifically, it begins by capturing static semantics via teacher-prior adaptive masking (TPAM) combined with multi-view sparse sampling. This approach mitigates redundant temporal dependencies and enables the model to concentrate on lesion-related local semantics. Following this, contextual semantics are derived through cross-view masked feature completion (CVMFC) and attention-guided temporal prediction (AGTP). These processes establish cross-view correspondences and effectively model structured inter-frame evolution, thereby reinforcing temporal semantic continuity while preserving global contextual integrity. Extensive experiments on 11 endoscopic video datasets show that FPRL achieves superior performance across diverse downstream tasks, demonstrating its effectiveness in endoscopic video representation learning. The code is available at https://github.com/MLMIP/FPRL.
MSDNN: Multi-Scale Deep Neural Network for Salient Object Detection
Jan 12, 2018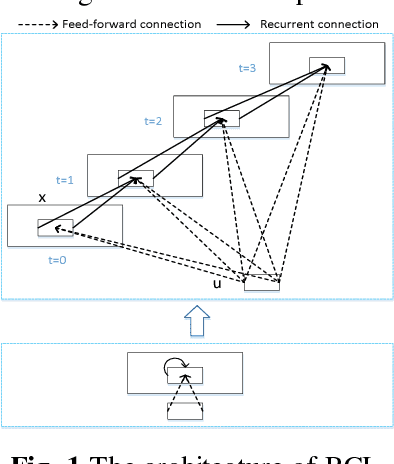
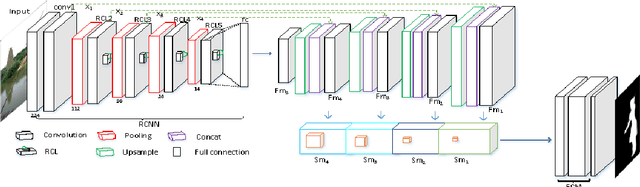
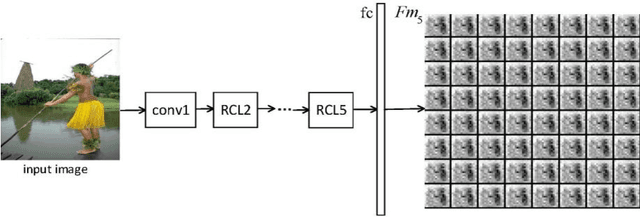

Salient object detection is a fundamental problem and has been received a great deal of attentions in computer vision. Recently deep learning model became a powerful tool for image feature extraction. In this paper, we propose a multi-scale deep neural network (MSDNN) for salient object detection. The proposed model first extracts global high-level features and context information over the whole source image with recurrent convolutional neural network (RCNN). Then several stacked deconvolutional layers are adopted to get the multi-scale feature representation and obtain a series of saliency maps. Finally, we investigate a fusion convolution module (FCM) to build a final pixel level saliency map. The proposed model is extensively evaluated on four salient object detection benchmark datasets. Results show that our deep model significantly outperforms other 12 state-of-the-art approaches.