 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes William Shakespeare REALLY Write Hamlet? Knowledge Representation Learning with Confidence
Feb 16, 2018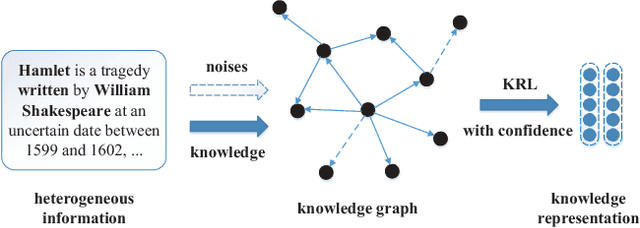
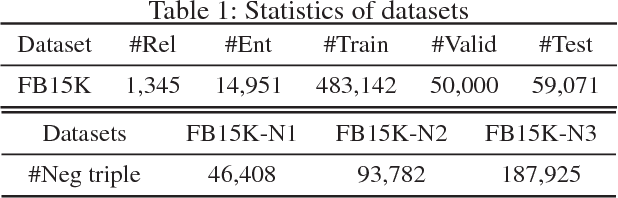
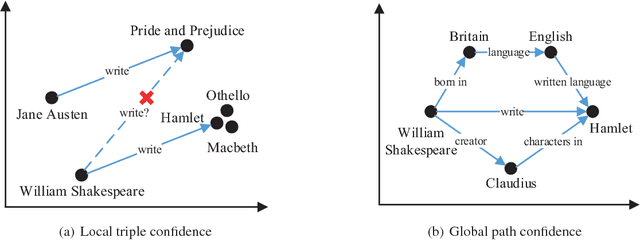
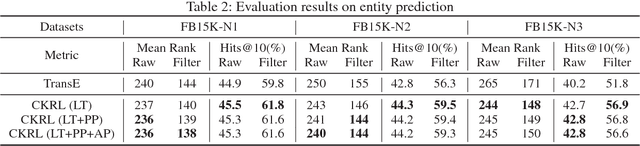
Knowledge graphs (KGs), which could provide essential relational information between entities, have been widely utilized in various knowledge-driven applications. Since the overall human knowledge is innumerable that still grows explosively and changes frequently, knowledge construction and update inevitably involve automatic mechanisms with less human supervision, which usually bring in plenty of noises and conflicts to KGs. However, most conventional knowledge representation learning methods assume that all triple facts in existing KGs share the same significance without any noises. To address this problem, we propose a novel confidence-aware knowledge representation learning framework (CKRL), which detects possible noises in KGs while learning knowledge representations with confidence simultaneously. Specifically, we introduce the triple confidence to conventional translation-based methods for knowledge representation learning. To make triple confidence more flexible and universal, we only utilize the internal structural information in KGs, and propose three kinds of triple confidences considering both local and global structural information. In experiments, We evaluate our models on knowledge graph noise detection, knowledge graph completion and triple classification. Experimental results demonstrate that our confidence-aware models achieve significant and consistent improvements on all tasks, which confirms the capability of CKRL modeling confidence with structural information in both KG noise detection and knowledge representation learning.
* 8 pages
Tree-Structured Neural Machine for Linguistics-Aware Sentence Generation
Jan 03, 2018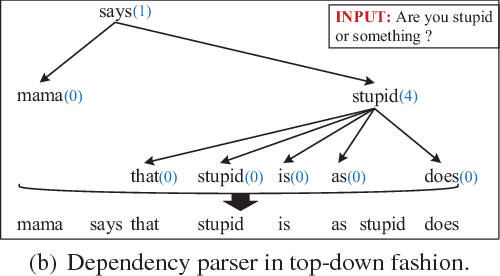
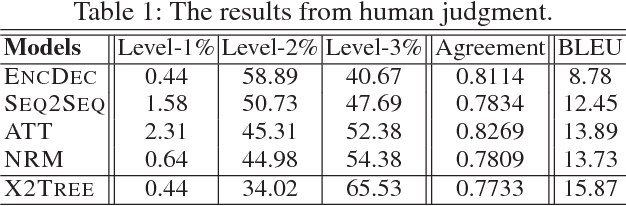
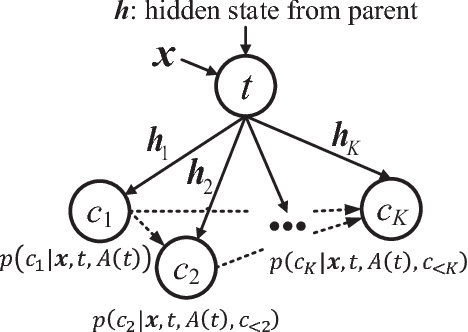
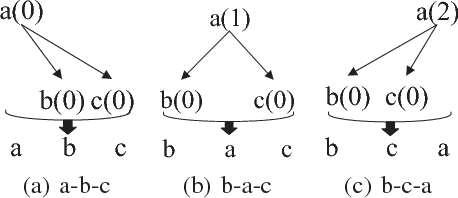
Different from other sequential data, sentences in natural language are structured by linguistic grammars. Previous generative conversational models with chain-structured decoder ignore this structure in human language and might generate plausible responses with less satisfactory relevance and fluency. In this study, we aim to incorporate the results from linguistic analysis into the process of sentence generation for high-quality conversation generation. Specifically, we use a dependency parser to transform each response sentence into a dependency tree and construct a training corpus of sentence-tree pairs. A tree-structured decoder is developed to learn the mapping from a sentence to its tree, where different types of hidden states are used to depict the local dependencies from an internal tree node to its children. For training acceleration, we propose a tree canonicalization method, which transforms trees into equivalent ternary trees. Then, with a proposed tree-structured search method, the model is able to generate the most probable responses in the form of dependency trees, which are finally flattened into sequences as the system output. Experimental results demonstrate that the proposed X2Tree framework outperforms baseline methods over 11.15% increase of acceptance ratio.