 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust-Region Diffusion Policies for Massively Parallel On-Policy RL
Jun 13, 2026Reinforcement learning with massively parallel simulations has become a standard framework for developing robust, deployable policies; however, most existing approaches still rely on simple Gaussian policy parameterizations. Diffusion models provide a more expressive policy class and have shown strong performance on challenging control problems, yet most diffusion-based RL methods are designed for offline or off-policy training. In this work, we ask whether diffusion policies can be trained effectively in the massively parallel, on-policy regime. To this end, we introduce Trust-region Diffusion Policies (TruDi), which enables diffusion policies for on-policy RL with massively parallel simulations. This setting is particularly challenging because the data distribution changes quickly across updates, making stable training with complex policies difficult. TruDi addresses this by integrating a trust-region optimization rule to enforce a KL-divergence constraint over the entire diffusion trajectory. Empirically, we evaluate TruDi on a diverse set of 4 massively parallel RL benchmarks comprising a total of 73 tasks. Across these tasks, TruDi consistently outperforms or is on-par with strong baselines on standard tasks and achieves clear gains on more challenging humanoid control tasks, establishing a strong new baseline for massively parallel on-policy RL.
SOLO: Search Online, Learn Offline for Combinatorial Optimization Problems
Apr 08, 2021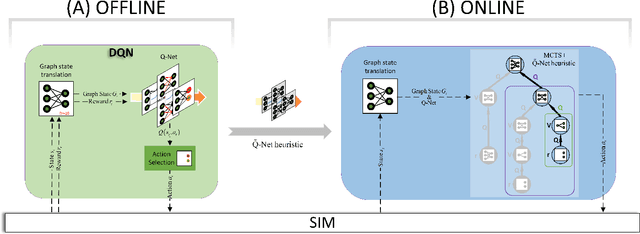
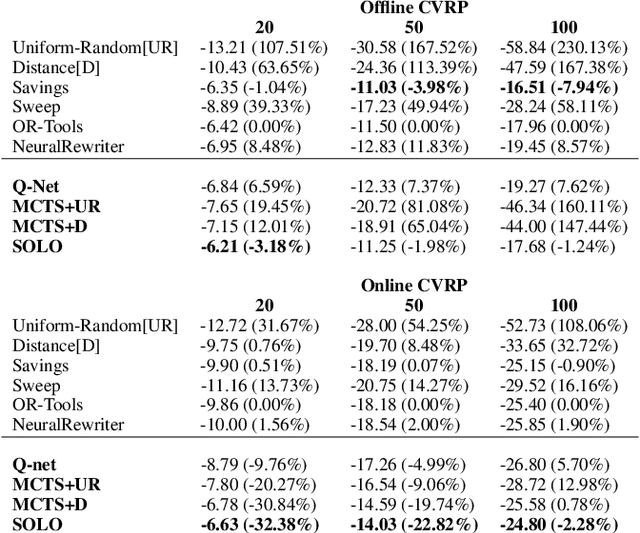
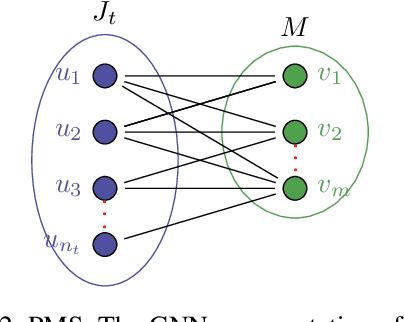

We study combinatorial problems with real world applications such as machine scheduling, routing, and assignment. We propose a method that combines Reinforcement Learning (RL) and planning. This method can equally be applied to both the offline, as well as online, variants of the combinatorial problem, in which the problem components (e.g., jobs in scheduling problems) are not known in advance, but rather arrive during the decision-making process. Our solution is quite generic, scalable, and leverages distributional knowledge of the problem parameters. We frame the solution process as an MDP, and take a Deep Q-Learning approach wherein states are represented as graphs, thereby allowing our trained policies to deal with arbitrary changes in a principled manner. Though learned policies work well in expectation, small deviations can have substantial negative effects in combinatorial settings. We mitigate these drawbacks by employing our graph-convolutional policies as non-optimal heuristics in a compatible search algorithm, Monte Carlo Tree Search, to significantly improve overall performance. We demonstrate our method on two problems: Machine Scheduling and Capacitated Vehicle Routing. We show that our method outperforms custom-tailored mathematical solvers, state of the art learning-based algorithms, and common heuristics, both in computation time and performance.