 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfigurable Clinical Information Extraction with Agentic RAG: What Works, What Breaks, and Why
Jun 17, 2026Patient contexts span hundreds of heterogeneous documents and thousands of structured data points, yet the document-level metadata that AI systems need for retrieval and triage is absent or incomplete. Standard retrieval-augmented generation fails on this data, mishandling temporal reasoning, cross-document dependencies, and missing metadata. We deploy ACIE (Agentic Clinical Information Extraction) at University Medicine Essen: an on-premise agentic RAG pipeline that reasons over complete patient contexts and grounds every answer in source passages for clinician verification. We quantify the metadata gap, trace the architectural decisions it shaped, and evaluate extraction alongside an independent retrospective lymphoma registry study, in which nuclear-medicine physicians verify every extracted value against its cited sources. Across 7,326 judgments, clinicians accepted 96.5\% of extractions, with per-type acceptance ranging from 80\% to 99\%.
SALT: Introducing a Framework for Hierarchical Segmentations in Medical Imaging using Softmax for Arbitrary Label Trees
Jul 11, 2024



Traditional segmentation networks approach anatomical structures as standalone elements, overlooking the intrinsic hierarchical connections among them. This study introduces Softmax for Arbitrary Label Trees (SALT), a novel approach designed to leverage the hierarchical relationships between labels, improving the efficiency and interpretability of the segmentations. This study introduces a novel segmentation technique for CT imaging, which leverages conditional probabilities to map the hierarchical structure of anatomical landmarks, such as the spine's division into lumbar, thoracic, and cervical regions and further into individual vertebrae. The model was developed using the SAROS dataset from The Cancer Imaging Archive (TCIA), comprising 900 body region segmentations from 883 patients. The dataset was further enhanced by generating additional segmentations with the TotalSegmentator, for a total of 113 labels. The model was trained on 600 scans, while validation and testing were conducted on 150 CT scans. Performance was assessed using the Dice score across various datasets, including SAROS, CT-ORG, FLARE22, LCTSC, LUNA16, and WORD. Among the evaluated datasets, SALT achieved its best results on the LUNA16 and SAROS datasets, with Dice scores of 0.93 and 0.929 respectively. The model demonstrated reliable accuracy across other datasets, scoring 0.891 on CT-ORG and 0.849 on FLARE22. The LCTSC dataset showed a score of 0.908 and the WORD dataset also showed good performance with a score of 0.844. SALT used the hierarchical structures inherent in the human body to achieve whole-body segmentations with an average of 35 seconds for 100 slices. This rapid processing underscores its potential for integration into clinical workflows, facilitating the automatic and efficient computation of full-body segmentations with each CT scan, thus enhancing diagnostic processes and patient care.
ROCOv2: Radiology Objects in COntext Version 2, an Updated Multimodal Image Dataset
May 16, 2024Automated medical image analysis systems often require large amounts of training data with high quality labels, which are difficult and time consuming to generate. This paper introduces Radiology Object in COntext version 2 (ROCOv2), a multimodal dataset consisting of radiological images and associated medical concepts and captions extracted from the PMC Open Access subset. It is an updated version of the ROCO dataset published in 2018, and adds 35,705 new images added to PMC since 2018. It further provides manually curated concepts for imaging modalities with additional anatomical and directional concepts for X-rays. The dataset consists of 79,789 images and has been used, with minor modifications, in the concept detection and caption prediction tasks of ImageCLEFmedical Caption 2023. The dataset is suitable for training image annotation models based on image-caption pairs, or for multi-label image classification using Unified Medical Language System (UMLS) concepts provided with each image. In addition, it can serve for pre-training of medical domain models, and evaluation of deep learning models for multi-task learning.
Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
Apr 08, 2024



Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023



We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
Why does my medical AI look at pictures of birds? Exploring the efficacy of transfer learning across domain boundaries
Jun 30, 2023It is an open secret that ImageNet is treated as the panacea of pretraining. Particularly in medical machine learning, models not trained from scratch are often finetuned based on ImageNet-pretrained models. We posit that pretraining on data from the domain of the downstream task should almost always be preferred instead. We leverage RadNet-12M, a dataset containing more than 12 million computed tomography (CT) image slices, to explore the efficacy of self-supervised pretraining on medical and natural images. Our experiments cover intra- and cross-domain transfer scenarios, varying data scales, finetuning vs. linear evaluation, and feature space analysis. We observe that intra-domain transfer compares favorably to cross-domain transfer, achieving comparable or improved performance (0.44% - 2.07% performance increase using RadNet pretraining, depending on the experiment) and demonstrate the existence of a domain boundary-related generalization gap and domain-specific learned features.
Current State of Community-Driven Radiological AI Deployment in Medical Imaging
Dec 29, 2022



Artificial Intelligence (AI) has become commonplace to solve routine everyday tasks. Because of the exponential growth in medical imaging data volume and complexity, the workload on radiologists is steadily increasing. We project that the gap between the number of imaging exams and the number of expert radiologist readers required to cover this increase will continue to expand, consequently introducing a demand for AI-based tools that improve the efficiency with which radiologists can comfortably interpret these exams. AI has been shown to improve efficiency in medical-image generation, processing, and interpretation, and a variety of such AI models have been developed across research labs worldwide. However, very few of these, if any, find their way into routine clinical use, a discrepancy that reflects the divide between AI research and successful AI translation. To address the barrier to clinical deployment, we have formed MONAI Consortium, an open-source community which is building standards for AI deployment in healthcare institutions, and developing tools and infrastructure to facilitate their implementation. This report represents several years of weekly discussions and hands-on problem solving experience by groups of industry experts and clinicians in the MONAI Consortium. We identify barriers between AI-model development in research labs and subsequent clinical deployment and propose solutions. Our report provides guidance on processes which take an imaging AI model from development to clinical implementation in a healthcare institution. We discuss various AI integration points in a clinical Radiology workflow. We also present a taxonomy of Radiology AI use-cases. Through this report, we intend to educate the stakeholders in healthcare and AI (AI researchers, radiologists, imaging informaticists, and regulators) about cross-disciplinary challenges and possible solutions.
Open-Source Skull Reconstruction with MONAI
Nov 25, 2022



We present a deep learning-based approach for skull reconstruction for MONAI, which has been pre-trained on the MUG500+ skull dataset. The implementation follows the MONAI contribution guidelines, hence, it can be easily tried out and used, and extended by MONAI users. The primary goal of this paper lies in the investigation of open-sourcing codes and pre-trained deep learning models under the MONAI framework. Nowadays, open-sourcing software, especially (pre-trained) deep learning models, has become increasingly important. Over the years, medical image analysis experienced a tremendous transformation. Over a decade ago, algorithms had to be implemented and optimized with low-level programming languages, like C or C++, to run in a reasonable time on a desktop PC, which was not as powerful as today's computers. Nowadays, users have high-level scripting languages like Python, and frameworks like PyTorch and TensorFlow, along with a sea of public code repositories at hand. As a result, implementations that had thousands of lines of C or C++ code in the past, can now be scripted with a few lines and in addition executed in a fraction of the time. To put this even on a higher level, the Medical Open Network for Artificial Intelligence (MONAI) framework tailors medical imaging research to an even more convenient process, which can boost and push the whole field. The MONAI framework is a freely available, community-supported, open-source and PyTorch-based framework, that also enables to provide research contributions with pre-trained models to others. Codes and pre-trained weights for skull reconstruction are publicly available at: https://github.com/Project-MONAI/research-contributions/tree/master/SkullRec
k-strip: A novel segmentation algorithm in k-space for the application of skull stripping
May 19, 2022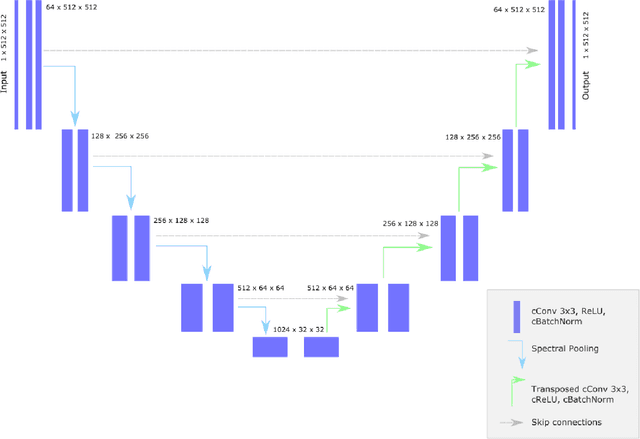
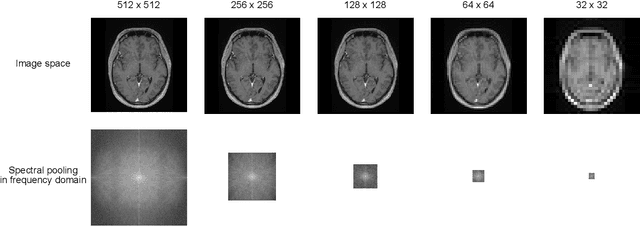
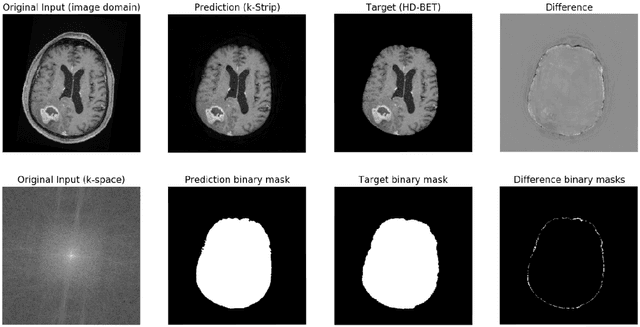
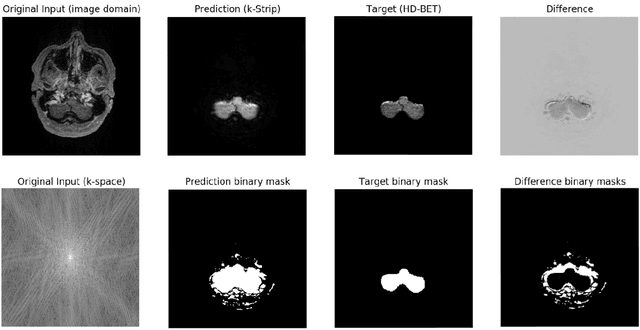
Objectives: Present a novel deep learning-based skull stripping algorithm for magnetic resonance imaging (MRI) that works directly in the information rich k-space. Materials and Methods: Using two datasets from different institutions with a total of 36,900 MRI slices, we trained a deep learning-based model to work directly with the complex raw k-space data. Skull stripping performed by HD-BET (Brain Extraction Tool) in the image domain were used as the ground truth. Results: Both datasets were very similar to the ground truth (DICE scores of 92\%-98\% and Hausdorff distances of under 5.5 mm). Results on slices above the eye-region reach DICE scores of up to 99\%, while the accuracy drops in regions around the eyes and below, with partially blurred output. The output of k-strip often smoothed edges at the demarcation to the skull. Binary masks are created with an appropriate threshold. Conclusion: With this proof-of-concept study, we were able to show the feasibility of working in the k-space frequency domain, preserving phase information, with consistent results. Future research should be dedicated to discovering additional ways the k-space can be used for innovative image analysis and further workflows.
MOMO -- Deep Learning-driven classification of external DICOM studies for PACS archivation
Dec 01, 2021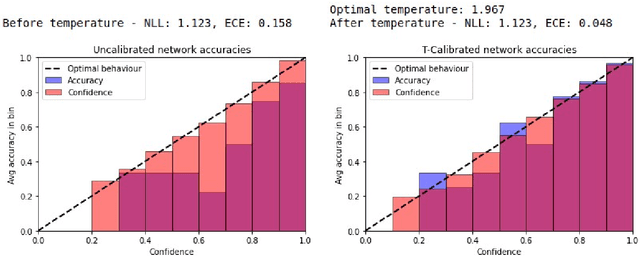
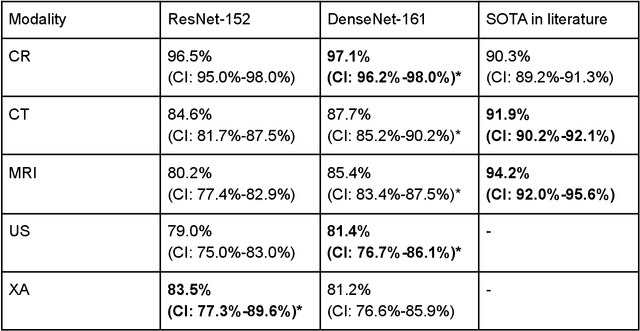

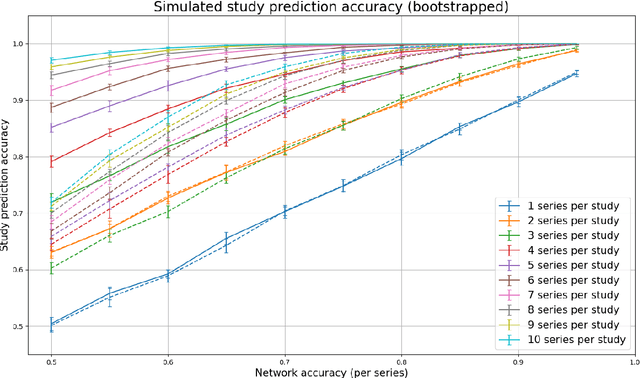
Patients regularly continue assessment or treatment in other facilities than they began them in, receiving their previous imaging studies as a CD-ROM and requiring clinical staff at the new hospital to import these studies into their local database. However, between different facilities, standards for nomenclature, contents, or even medical procedures may vary, often requiring human intervention to accurately classify the received studies in the context of the recipient hospital's standards. In this study, the authors present MOMO (MOdality Mapping and Orchestration), a deep learning-based approach to automate this mapping process utilizing metadata substring matching and a neural network ensemble, which is trained to recognize the 76 most common imaging studies across seven different modalities. A retrospective study is performed to measure the accuracy that this algorithm can provide. To this end, a set of 11,934 imaging series with existing labels was retrieved from the local hospital's PACS database to train the neural networks. A set of 843 completely anonymized external studies was hand-labeled to assess the performance of our algorithm. Additionally, an ablation study was performed to measure the performance impact of the network ensemble in the algorithm, and a comparative performance test with a commercial product was conducted. In comparison to a commercial product (96.20% predictive power, 82.86% accuracy, 1.36% minor errors), a neural network ensemble alone performs the classification task with less accuracy (99.05% predictive power, 72.69% accuracy, 10.3% minor errors). However, MOMO outperforms either by a large margin in accuracy and with increased predictive power (99.29% predictive power, 92.71% accuracy, 2.63% minor errors).