 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
Towards a parallel corpus of Portuguese and the Bantu language Emakhuwa of Mozambique
Apr 12, 2021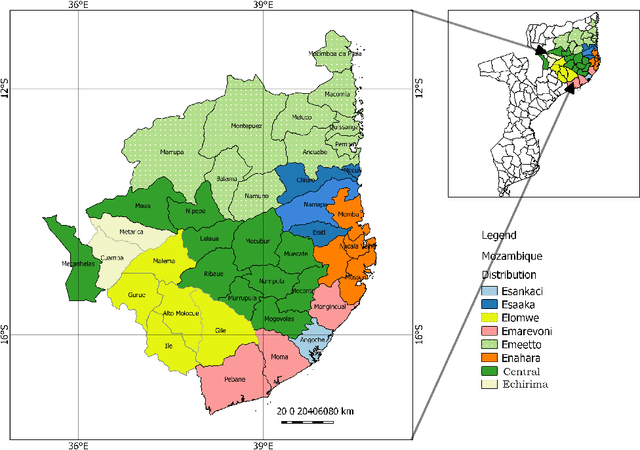
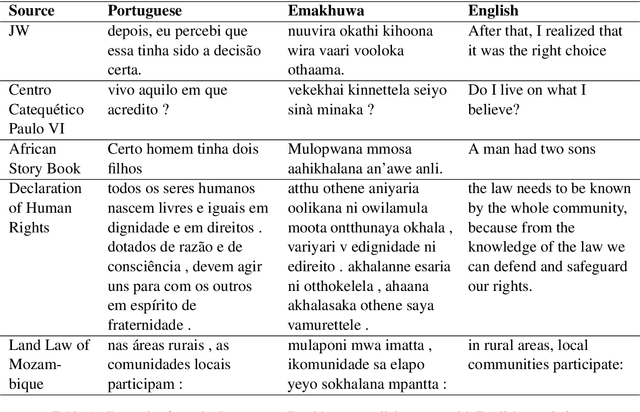
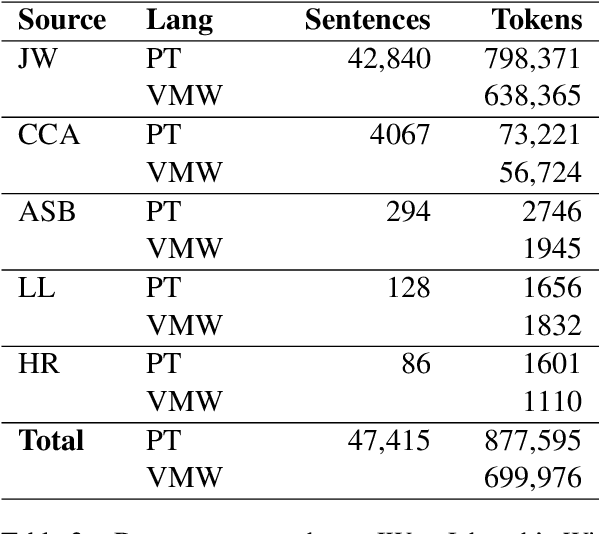

Major advancement in the performance of machine translation models has been made possible in part thanks to the availability of large-scale parallel corpora. But for most languages in the world, the existence of such corpora is rare. Emakhuwa, a language spoken in Mozambique, is like most African languages low-resource in NLP terms. It lacks both computational and linguistic resources and, to the best of our knowledge, few parallel corpora including Emakhuwa already exist. In this paper we describe the creation of the Emakhuwa-Portuguese parallel corpus, which is a collection of texts from the Jehovah's Witness website and a variety of other sources including the African Story Book website, the Universal Declaration of Human Rights and Mozambican legal documents. The dataset contains 47,415 sentence pairs, amounting to 699,976 word tokens of Emakhuwa and 877,595 word tokens in Portuguese. After normalization processes which remain to be completed, the corpus will be made freely available for research use.