 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation using Silver Standard Labels for Ki-67 Scoring in Digital Pathology: A Step Closer to Widescale Deployment
Jul 08, 2023



Deep learning systems have been proposed to improve the objectivity and efficiency of Ki- 67 PI scoring. The challenge is that while very accurate, deep learning techniques suffer from reduced performance when applied to out-of-domain data. This is a critical challenge for clinical translation, as models are typically trained using data available to the vendor, which is not from the target domain. To address this challenge, this study proposes a domain adaptation pipeline that employs an unsupervised framework to generate silver standard (pseudo) labels in the target domain, which is used to augment the gold standard (GS) source domain data. Five training regimes were tested on two validated Ki-67 scoring architectures (UV-Net and piNET), (1) SS Only: trained on target silver standard (SS) labels, (2) GS Only: trained on source GS labels, (3) Mixed: trained on target SS and source GS labels, (4) GS+SS: trained on source GS labels and fine-tuned on target SS labels, and our proposed method (5) SS+GS: trained on source SS labels and fine-tuned on source GS labels. The SS+GS method yielded significantly (p < 0.05) higher PI accuracy (95.9%) and more consistent results compared to the GS Only model on target data. Analysis of t-SNE plots showed features learned by the SS+GS models are more aligned for source and target data, resulting in improved generalization. The proposed pipeline provides an efficient method for learning the target distribution without manual annotations, which are time-consuming and costly to generate for medical images. This framework can be applied to any target site as a per-laboratory calibration method, for widescale deployment.
Preserving Dense Features for Ki67 Nuclei Detection
Nov 10, 2021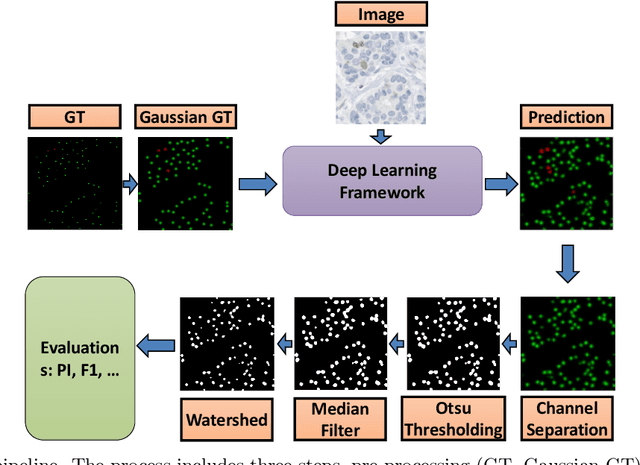
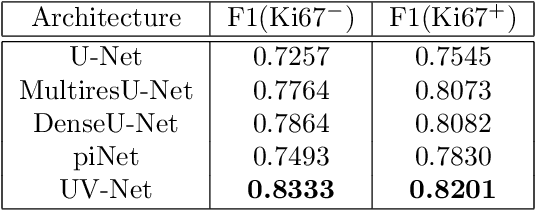
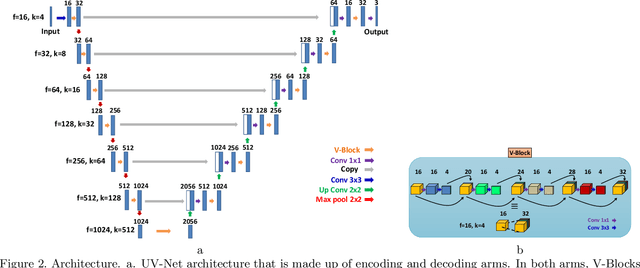
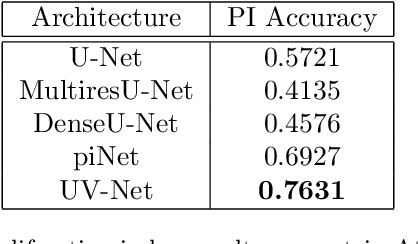
Nuclei detection is a key task in Ki67 proliferation index estimation in breast cancer images. Deep learning algorithms have shown strong potential in nuclei detection tasks. However, they face challenges when applied to pathology images with dense medium and overlapping nuclei since fine details are often diluted or completely lost by early maxpooling layers. This paper introduces an optimized UV-Net architecture, specifically developed to recover nuclear details with high-resolution through feature preservation for Ki67 proliferation index computation. UV-Net achieves an average F1-score of 0.83 on held-out test patch data, while other architectures obtain 0.74-0.79. On tissue microarrays (unseen) test data obtained from multiple centers, UV-Net's accuracy exceeds other architectures by a wide margin, including 9-42\% on Ontario Veterinary College, 7-35\% on Protein Atlas and 0.3-3\% on University Health Network.
A Machine Learning Challenge for Prognostic Modelling in Head and Neck Cancer Using Multi-modal Data
Jan 28, 2021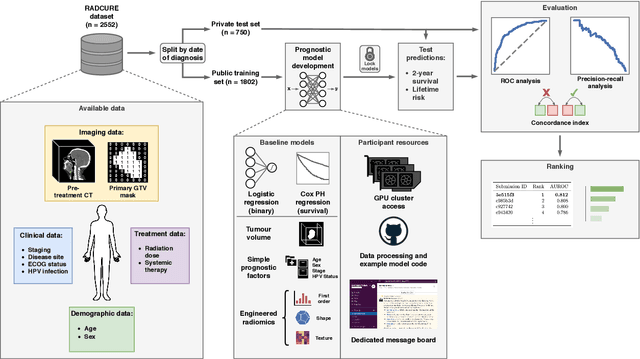
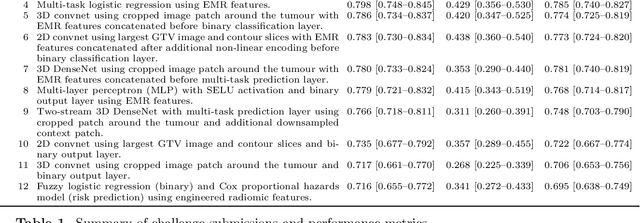
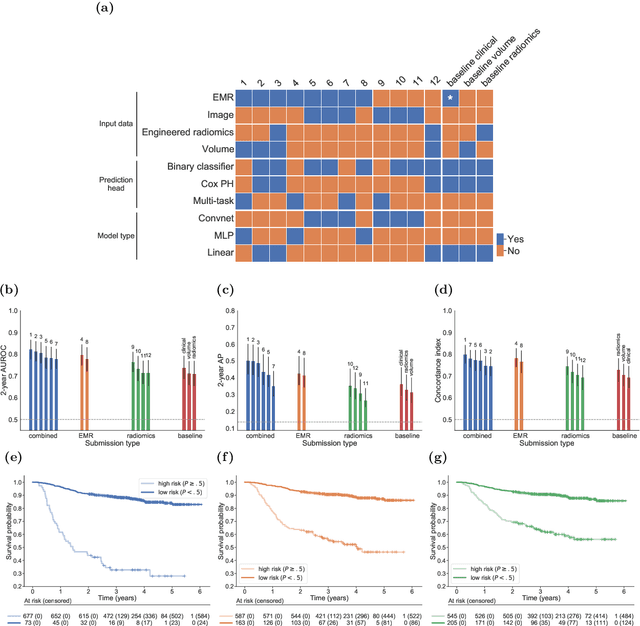
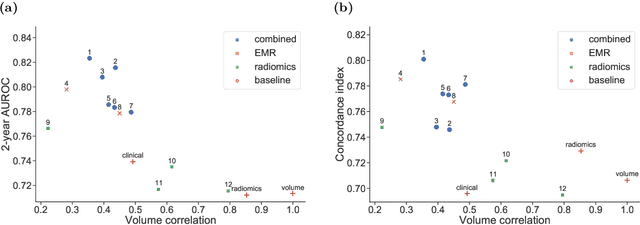
Accurate prognosis for an individual patient is a key component of precision oncology. Recent advances in machine learning have enabled the development of models using a wider range of data, including imaging. Radiomics aims to extract quantitative predictive and prognostic biomarkers from routine medical imaging, but evidence for computed tomography radiomics for prognosis remains inconclusive. We have conducted an institutional machine learning challenge to develop an accurate model for overall survival prediction in head and neck cancer using clinical data etxracted from electronic medical records and pre-treatment radiological images, as well as to evaluate the true added benefit of radiomics for head and neck cancer prognosis. Using a large, retrospective dataset of 2,552 patients and a rigorous evaluation framework, we compared 12 different submissions using imaging and clinical data, separately or in combination. The winning approach used non-linear, multitask learning on clinical data and tumour volume, achieving high prognostic accuracy for 2-year and lifetime survival prediction and outperforming models relying on clinical data only, engineered radiomics and deep learning. Combining all submissions in an ensemble model resulted in improved accuracy, with the highest gain from a image-based deep learning model. Our results show the potential of machine learning and simple, informative prognostic factors in combination with large datasets as a tool to guide personalized cancer care.