 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyWalk: Going Farther in Vision-and-Language Navigation by Taking Baby Steps
Jun 14, 2020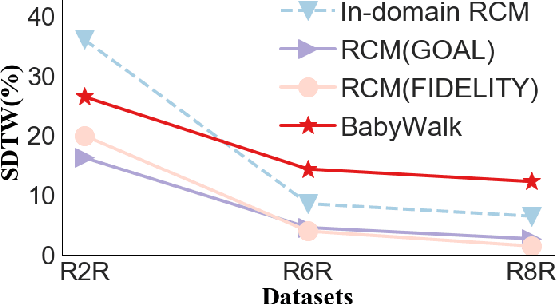
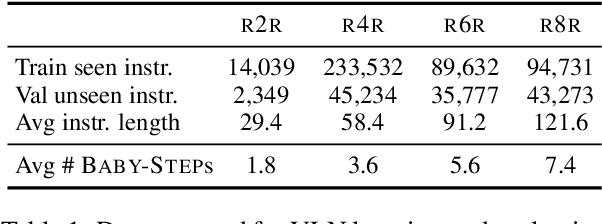
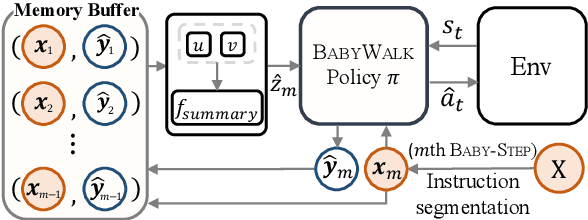
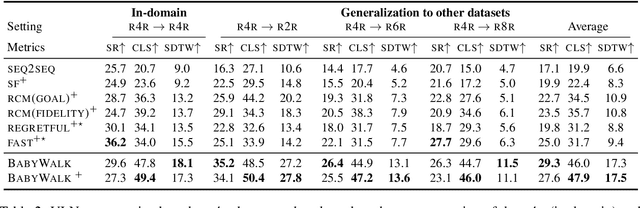
Learning to follow instructions is of fundamental importance to autonomous agents for vision-and-language navigation (VLN). In this paper, we study how an agent can navigate long paths when learning from a corpus that consists of shorter ones. We show that existing state-of-the-art agents do not generalize well. To this end, we propose BabyWalk, a new VLN agent that is learned to navigate by decomposing long instructions into shorter ones (BabySteps) and completing them sequentially. A special design memory buffer is used by the agent to turn its past experiences into contexts for future steps. The learning process is composed of two phases. In the first phase, the agent uses imitation learning from demonstration to accomplish BabySteps. In the second phase, the agent uses curriculum-based reinforcement learning to maximize rewards on navigation tasks with increasingly longer instructions. We create two new benchmark datasets (of long navigation tasks) and use them in conjunction with existing ones to examine BabyWalk's generalization ability. Empirical results show that BabyWalk achieves state-of-the-art results on several metrics, in particular, is able to follow long instructions better. The codes and the datasets are released on our project page https://github.com/Sha-Lab/babywalk.
Uncertainty Estimation with Infinitesimal Jackknife, Its Distribution and Mean-Field Approximation
Jun 13, 2020
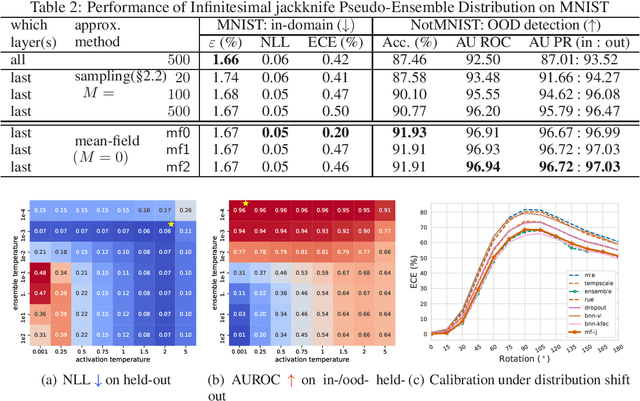
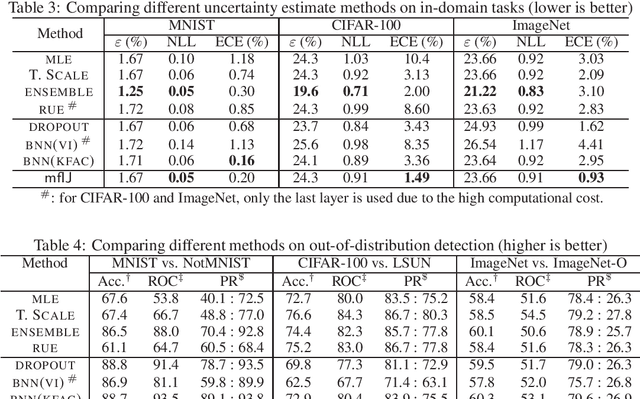

Uncertainty quantification is an important research area in machine learning. Many approaches have been developed to improve the representation of uncertainty in deep models to avoid overconfident predictions. Existing ones such as Bayesian neural networks and ensemble methods require modifications to the training procedures and are computationally costly for both training and inference. Motivated by this, we propose mean-field infinitesimal jackknife (mfIJ) -- a simple, efficient, and general-purpose plug-in estimator for uncertainty estimation. The main idea is to use infinitesimal jackknife, a classical tool from statistics for uncertainty estimation to construct a pseudo-ensemble that can be described with a closed-form Gaussian distribution, without retraining. We then use this Gaussian distribution for uncertainty estimation. While the standard way is to sample models from this distribution and combine each sample's prediction, we develop a mean-field approximation to the inference where Gaussian random variables need to be integrated with the softmax nonlinear functions to generate probabilities for multinomial variables. The approach has many appealing properties: it functions as an ensemble without requiring multiple models, and it enables closed-form approximate inference using only the first and second moments of Gaussians. Empirically, mfIJ performs competitively when compared to state-of-the-art methods, including deep ensembles, temperature scaling, dropout and Bayesian NNs, on important uncertainty tasks. It especially outperforms many methods on out-of-distribution detection.
AI-QMIX: Attention and Imagination for Dynamic Multi-Agent Reinforcement Learning
Jun 07, 2020

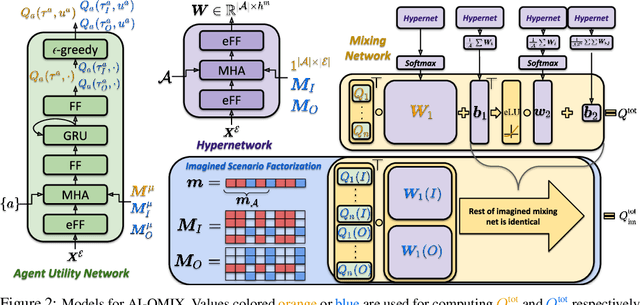
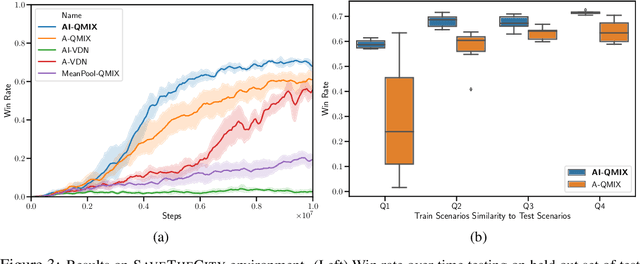
Real world multi-agent tasks often involve varying types and quantities of agents and non-agent entities. Agents frequently do not know a priori how many other agents and non-agent entities they will need to interact with in order to complete a given task, requiring agents to generalize across a combinatorial number of task configurations with each potentially requiring different strategies. In this work, we tackle the problem of multi-agent reinforcement learning (MARL) in such dynamic scenarios. We hypothesize that, while the optimal behaviors in these scenarios with varying quantities and types of agents/entities are diverse, they may share common patterns within sub-teams of agents that are combined to form team behavior. As such, we propose a method that can learn these sub-group relationships and how they can be combined, ultimately improving knowledge sharing and generalization across scenarios. This method, Attentive-Imaginative QMIX, extends QMIX for dynamic MARL in two ways: 1) an attention mechanism that enables model sharing across variable sized scenarios and 2) a training objective that improves learning across scenarios with varying combinations of agent/entity types by factoring the value function into imagined sub-scenarios. We validate our approach on both a novel grid-world task as well as a version of the StarCraft Multi-Agent Challenge minimally modified for the dynamic scenario setting. The results in these domains validate the effectiveness of the two new components in generalizing across dynamic configurations of agents and entities.
Visual Storytelling via Predicting Anchor Word Embeddings in the Stories
Jan 13, 2020
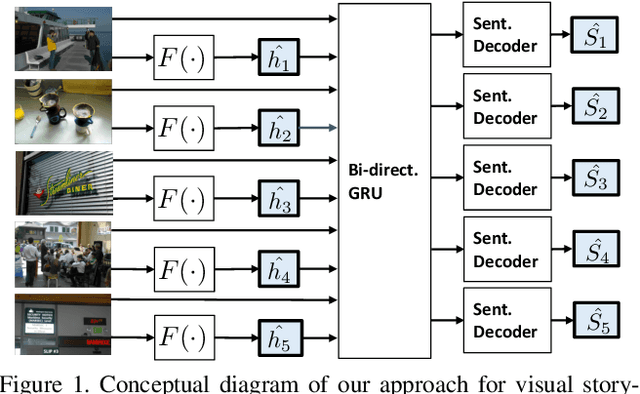
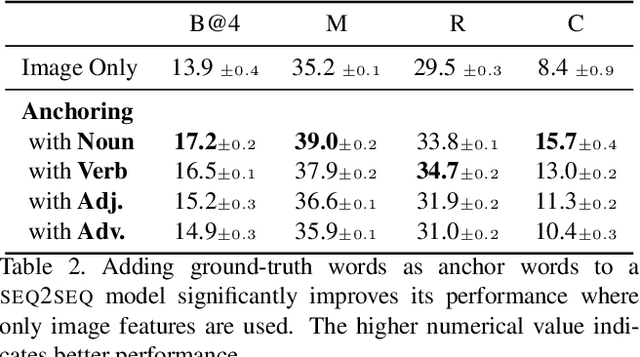
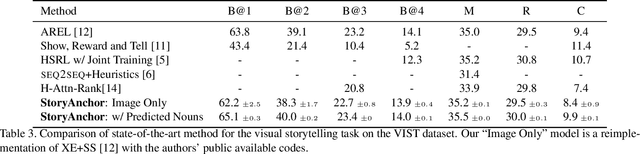
We propose a learning model for the task of visual storytelling. The main idea is to predict anchor word embeddings from the images and use the embeddings and the image features jointly to generate narrative sentences. We use the embeddings of randomly sampled nouns from the groundtruth stories as the target anchor word embeddings to learn the predictor. To narrate a sequence of images, we use the predicted anchor word embeddings and the image features as the joint input to a seq2seq model. As opposed to state-of-the-art methods, the proposed model is simple in design, easy to optimize, and attains the best results in most automatic evaluation metrics. In human evaluation, the method also outperforms competing methods.
Decoupling Adaptation from Modeling with Meta-Optimizers for Meta Learning
Oct 30, 2019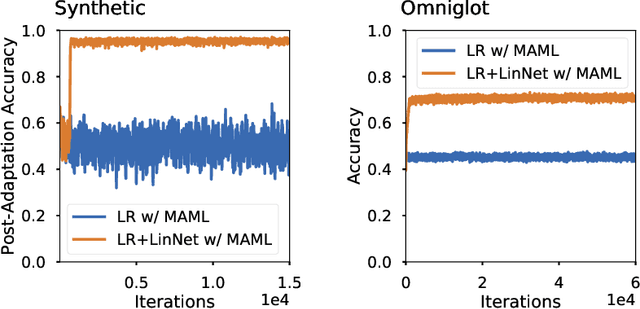

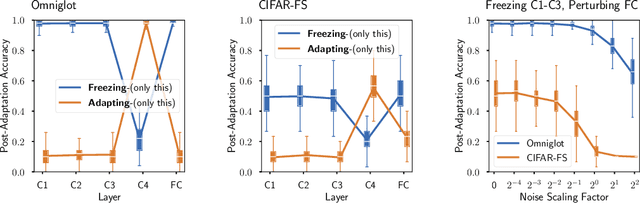

Meta-learning methods, most notably Model-Agnostic Meta-Learning or MAML, have achieved great success in adapting to new tasks quickly, after having been trained on similar tasks. The mechanism behind their success, however, is poorly understood. We begin this work with an experimental analysis of MAML, finding that deep models are crucial for its success, even given sets of simple tasks where a linear model would suffice on any individual task. Furthermore, on image-recognition tasks, we find that the early layers of MAML-trained models learn task-invariant features, while later layers are used for adaptation, providing further evidence that these models require greater capacity than is strictly necessary for their individual tasks. Following our findings, we propose a method which enables better use of model capacity at inference time by separating the adaptation aspect of meta-learning into parameters that are only used for adaptation but are not part of the forward model. We find that our approach enables more effective meta-learning in smaller models, which are suitably sized for the individual tasks.
Topic Augmented Generator for Abstractive Summarization
Aug 19, 2019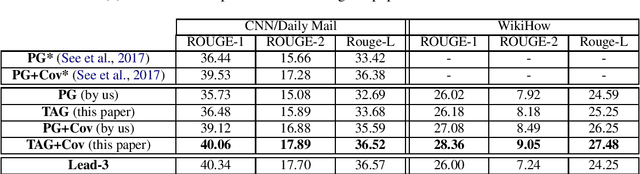
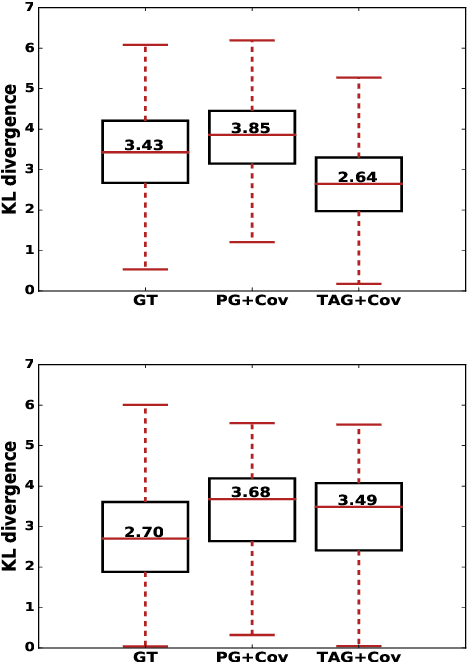


Steady progress has been made in abstractive summarization with attention-based sequence-to-sequence learning models. In this paper, we propose a new decoder where the output summary is generated by conditioning on both the input text and the latent topics of the document. The latent topics, identified by a topic model such as LDA, reveals more global semantic information that can be used to bias the decoder to generate words. In particular, they enable the decoder to have access to additional word co-occurrence statistics captured at document corpus level. We empirically validate the advantage of the proposed approach on both the CNN/Daily Mail and the WikiHow datasets. Concretely, we attain strongly improved ROUGE scores when compared to state-of-the-art models.
Neural Theorem Provers Do Not Learn Rules Without Exploration
Jun 17, 2019
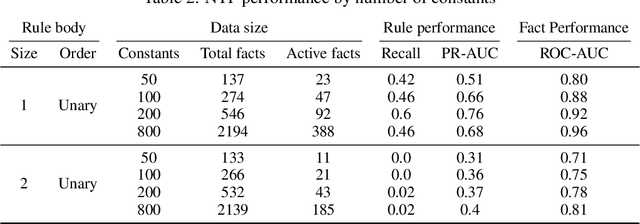
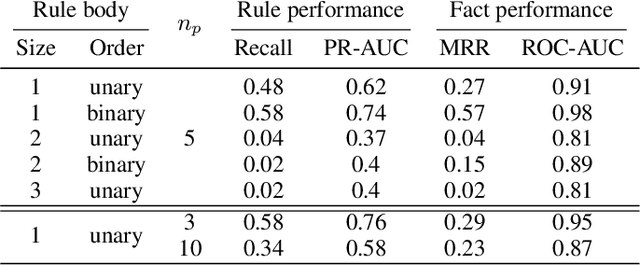
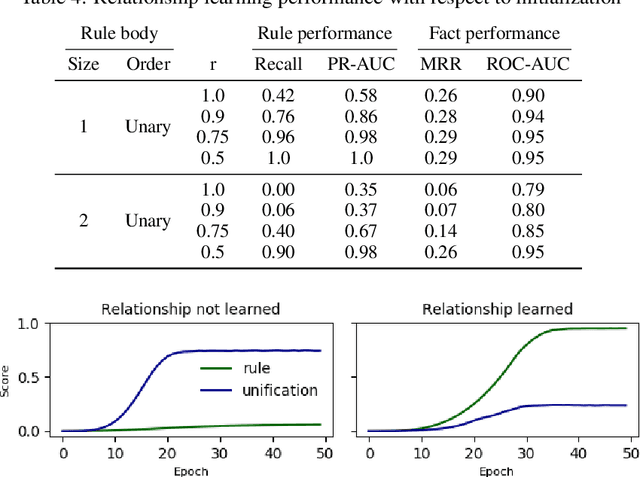
Neural symbolic processing aims to combine the generalization of logical learning approaches and the performance of neural networks. The Neural Theorem Proving (NTP) model by Rocktaschel et al (2017) learns embeddings for concepts and performs logical unification. While NTP is promising and effective in predicting facts accurately, we have little knowledge how well it can extract true relationship among data. To this end, we create synthetic logical datasets with injected relationships, which can be generated on-the-fly, to test neural-based relation learning algorithms including NTP. We show that it has difficulty recovering relationships in all but the simplest settings. Critical analysis and diagnostic experiments suggest that the optimization algorithm suffers from poor local minima due to its greedy winner-takes-all strategy in identifying the most informative structure (proof path) to pursue. We alter the NTP algorithm to increase exploration, which sharply improves performance. We argue and demonstate that it is insightful to benchmark with synthetic data with ground-truth relationships, for both evaluating models and revealing algorithmic issues.
Learning Classifier Synthesis for Generalized Few-Shot Learning
Jun 07, 2019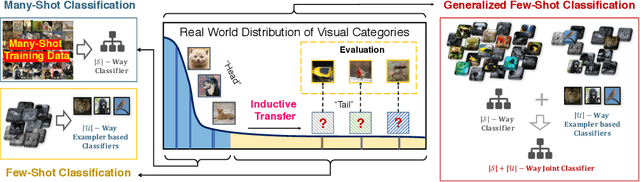
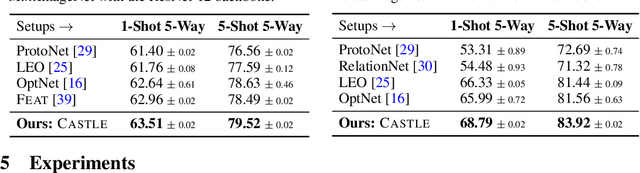
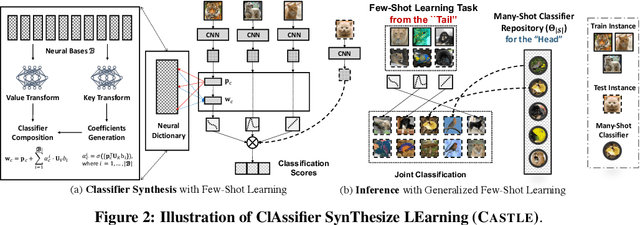
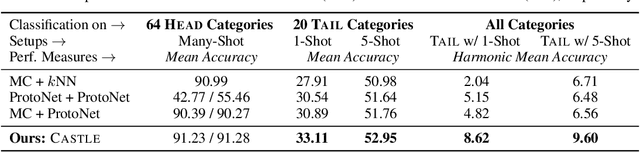
Visual recognition in real-world requires handling long-tailed and even open-ended data. It is a practical utility of a visual system to reliably recognizing the populated "head" visual concepts and meanwhile to learn about "tail" categories of few instances. Class-balanced many-shot learning and few-shot learning tackle one side of this challenging problem, via either learning strong classifiers for populated categories or few-shot classifiers for the tail classes. In this paper, we investigate the problem of generalized few-shot learning, where recognition on the head and the tail are performed jointly. We propose a neural dictionary-based ClAssifier SynThesis LEarning (CASTLE) approach to synthesizes the calibrated "tail" classifiers in addition to the multi-class "head" classifiers, and simultaneously recognizes the head and tail visual categories in a global discerning framework. CASTLE has demonstrated superior performances across different learning scenarios, i.e., many-shot learning, few-shot learning, and generalized few-shot learning, on two standard benchmark datasets --- MiniImageNet and TieredImageNet.
Amortized Inference of Variational Bounds for Learning Noisy-OR
Jun 06, 2019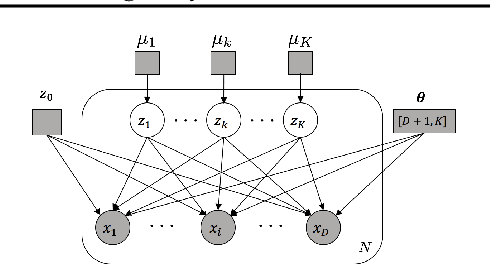
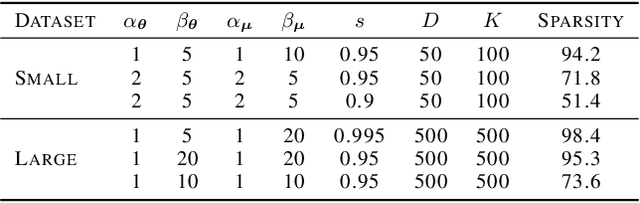
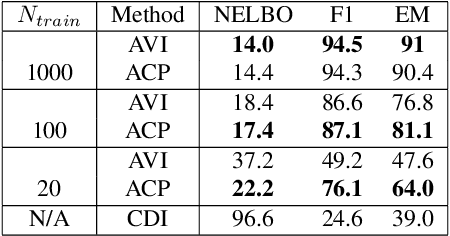
Classical approaches for approximate inference depend on cleverly designed variational distributions and bounds. Modern approaches employ amortized variational inference, which uses a neural network to approximate any posterior without leveraging the structures of the generative models. In this paper, we propose Amortized Conjugate Posterior (ACP), a hybrid approach taking advantages of both types of approaches. Specifically, we use the classical methods to derive specific forms of posterior distributions and then learn the variational parameters using amortized inference. We study the effectiveness of the proposed approach on the Noisy-OR model and compare to both the classical and the modern approaches for approximate inference and parameter learning. Our results show that ACP outperforms other methods when there is a limited amount of training data.
Coordinated Exploration via Intrinsic Rewards for Multi-Agent Reinforcement Learning
May 28, 2019
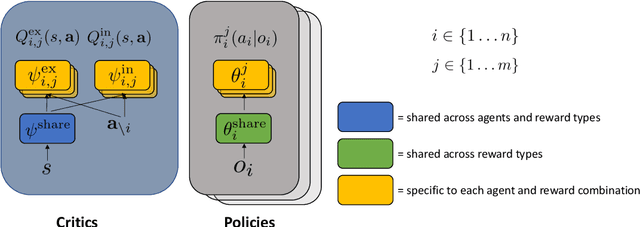
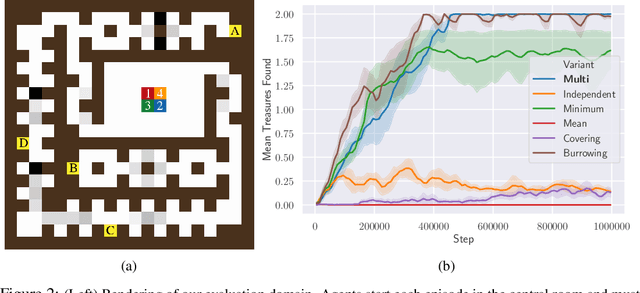
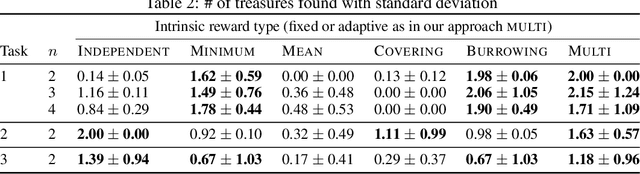
Sparse rewards are one of the most important challenges in reinforcement learning. In the single-agent setting, these challenges have been addressed by introducing intrinsic rewards that motivate agents to explore unseen regions of their state spaces. Applying these techniques naively to the multi-agent setting results in individual agents exploring independently, without any coordination among themselves. We argue that learning in cooperative multi-agent settings can be accelerated and improved if agents coordinate with respect to what they have explored. In this paper we propose an approach for learning how to dynamically select between different types of intrinsic rewards which consider not just what an individual agent has explored, but all agents, such that the agents can coordinate their exploration and maximize extrinsic returns. Concretely, we formulate the approach as a hierarchical policy where a high-level controller selects among sets of policies trained on different types of intrinsic rewards and the low-level controllers learn the action policies of all agents under these specific rewards. We demonstrate the effectiveness of the proposed approach in a multi-agent learning domain with sparse rewards.