 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMention Memory: incorporating textual knowledge into Transformers through entity mention attention
Oct 12, 2021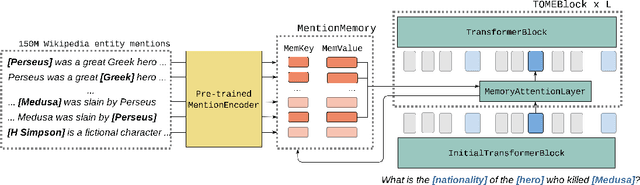
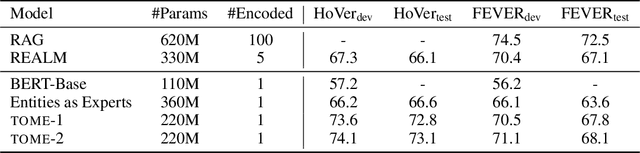
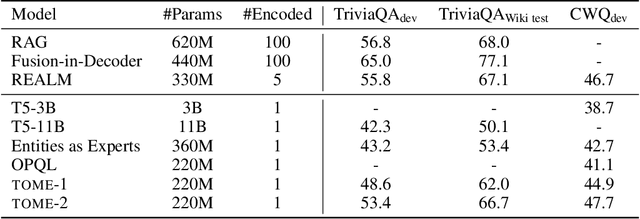
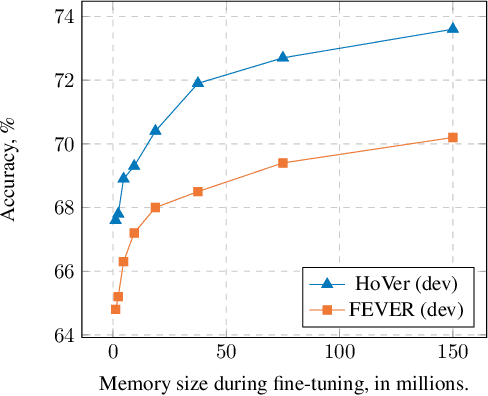
Natural language understanding tasks such as open-domain question answering often require retrieving and assimilating factual information from multiple sources. We propose to address this problem by integrating a semi-parametric representation of a large text corpus into a Transformer model as a source of factual knowledge. Specifically, our method represents knowledge with `mention memory', a table of dense vector representations of every entity mention in a corpus. The proposed model - TOME - is a Transformer that accesses the information through internal memory layers in which each entity mention in the input passage attends to the mention memory. This approach enables synthesis of and reasoning over many disparate sources of information within a single Transformer model. In experiments using a memory of 150 million Wikipedia mentions, TOME achieves strong performance on several open-domain knowledge-intensive tasks, including the claim verification benchmarks HoVer and FEVER and several entity-based QA benchmarks. We also show that the model learns to attend to informative mentions without any direct supervision. Finally we demonstrate that the model can generalize to new unseen entities by updating the memory without retraining.
Visually Grounded Concept Composition
Sep 29, 2021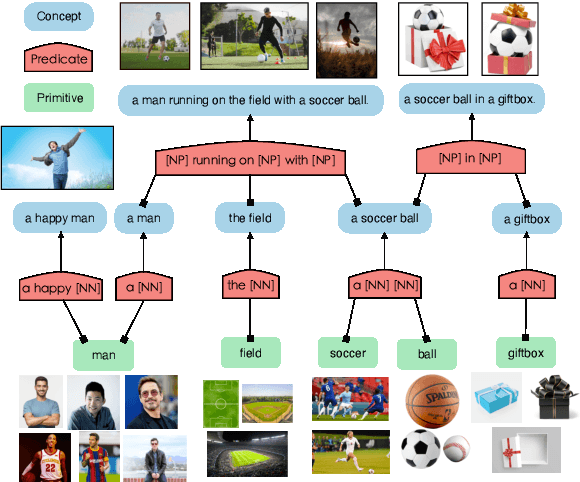

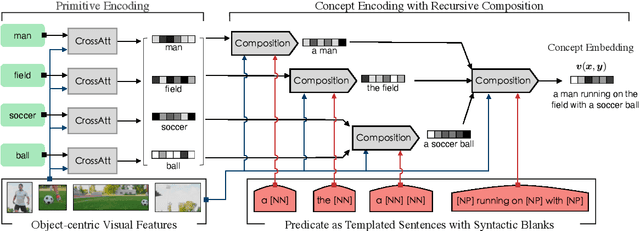
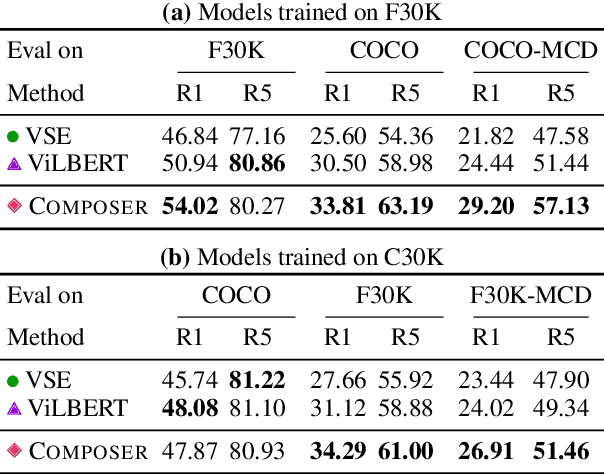
We investigate ways to compose complex concepts in texts from primitive ones while grounding them in images. We propose Concept and Relation Graph (CRG), which builds on top of constituency analysis and consists of recursively combined concepts with predicate functions. Meanwhile, we propose a concept composition neural network called Composer to leverage the CRG for visually grounded concept learning. Specifically, we learn the grounding of both primitive and all composed concepts by aligning them to images and show that learning to compose leads to more robust grounding results, measured in text-to-image matching accuracy. Notably, our model can model grounded concepts forming at both the finer-grained sentence level and the coarser-grained intermediate level (or word-level). Composer leads to pronounced improvement in matching accuracy when the evaluation data has significant compound divergence from the training data.
Systematic Generalization on gSCAN: What is Nearly Solved and What is Next?
Sep 25, 2021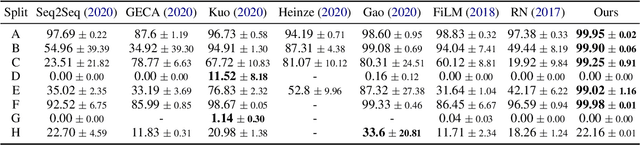
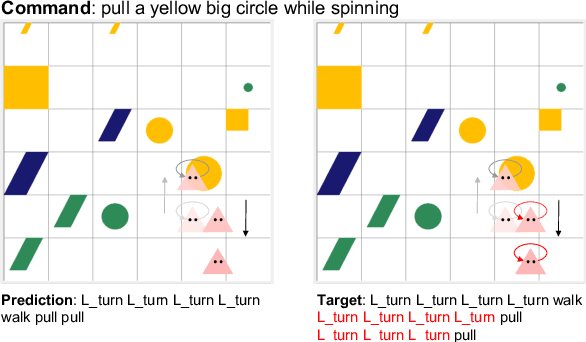

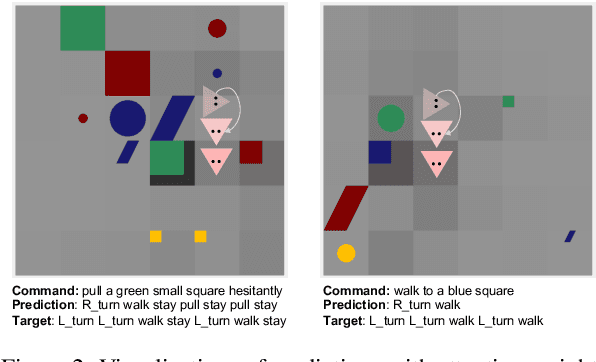
We analyze the grounded SCAN (gSCAN) benchmark, which was recently proposed to study systematic generalization for grounded language understanding. First, we study which aspects of the original benchmark can be solved by commonly used methods in multi-modal research. We find that a general-purpose Transformer-based model with cross-modal attention achieves strong performance on a majority of the gSCAN splits, surprisingly outperforming more specialized approaches from prior work. Furthermore, our analysis suggests that many of the remaining errors reveal the same fundamental challenge in systematic generalization of linguistic constructs regardless of visual context. Second, inspired by this finding, we propose challenging new tasks for gSCAN by generating data to incorporate relations between objects in the visual environment. Finally, we find that current models are surprisingly data inefficient given the narrow scope of commands in gSCAN, suggesting another challenge for future work.
ReadTwice: Reading Very Large Documents with Memories
May 11, 2021
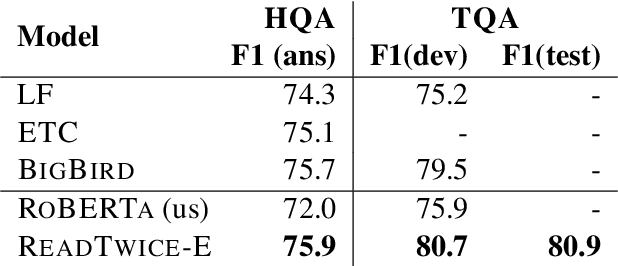
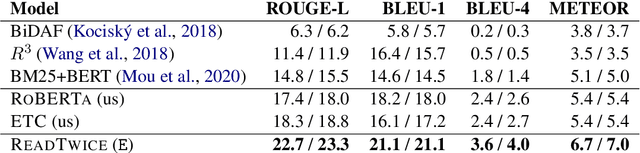
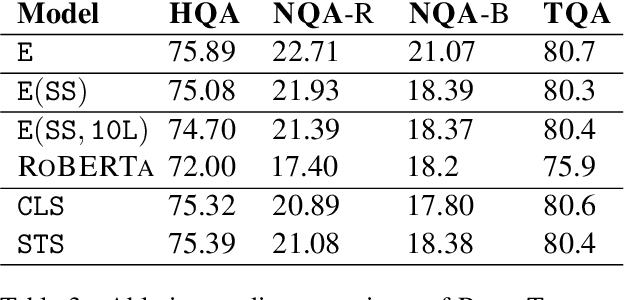
Knowledge-intensive tasks such as question answering often require assimilating information from different sections of large inputs such as books or article collections. We propose ReadTwice, a simple and effective technique that combines several strengths of prior approaches to model long-range dependencies with Transformers. The main idea is to read text in small segments, in parallel, summarizing each segment into a memory table to be used in a second read of the text. We show that the method outperforms models of comparable size on several question answering (QA) datasets and sets a new state of the art on the challenging NarrativeQA task, with questions about entire books. Source code and pre-trained checkpoints for ReadTwice can be found at https://goo.gle/research-readtwice.
Embedding Adaptation is Still Needed for Few-Shot Learning
Apr 15, 2021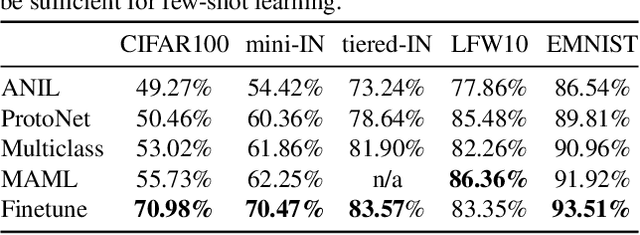
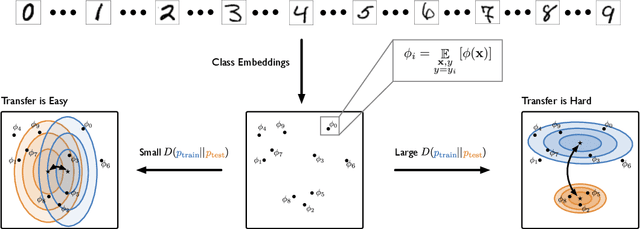
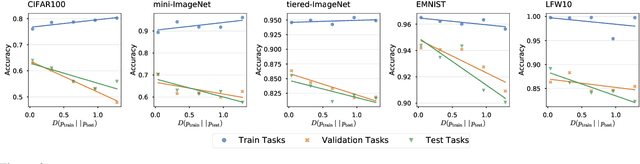
Constructing new and more challenging tasksets is a fruitful methodology to analyse and understand few-shot classification methods. Unfortunately, existing approaches to building those tasksets are somewhat unsatisfactory: they either assume train and test task distributions to be identical -- which leads to overly optimistic evaluations -- or take a "worst-case" philosophy -- which typically requires additional human labor such as obtaining semantic class relationships. We propose ATG, a principled clustering method to defining train and test tasksets without additional human knowledge. ATG models train and test task distributions while requiring them to share a predefined amount of information. We empirically demonstrate the effectiveness of ATG in generating tasksets that are easier, in-between, or harder than existing benchmarks, including those that rely on semantic information. Finally, we leverage our generated tasksets to shed a new light on few-shot classification: gradient-based methods -- previously believed to underperform -- can outperform metric-based ones when transfer is most challenging.
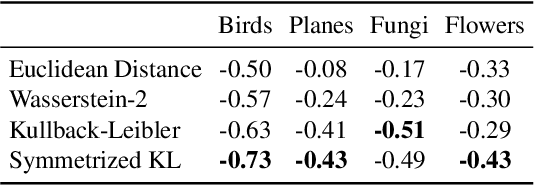
DOCENT: Learning Self-Supervised Entity Representations from Large Document Collections
Feb 26, 2021

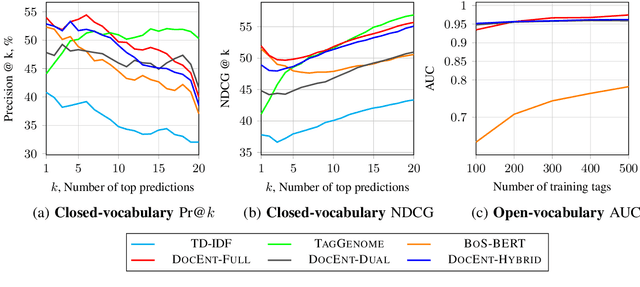
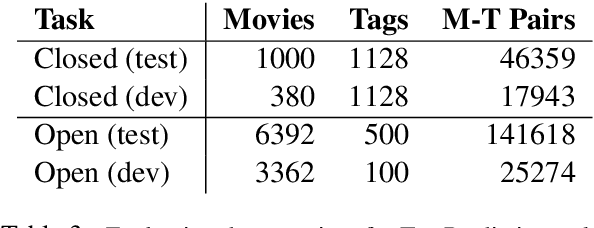
This paper explores learning rich self-supervised entity representations from large amounts of the associated text. Once pre-trained, these models become applicable to multiple entity-centric tasks such as ranked retrieval, knowledge base completion, question answering, and more. Unlike other methods that harvest self-supervision signals based merely on a local context within a sentence, we radically expand the notion of context to include any available text related to an entity. This enables a new class of powerful, high-capacity representations that can ultimately distill much of the useful information about an entity from multiple text sources, without any human supervision. We present several training strategies that, unlike prior approaches, learn to jointly predict words and entities -- strategies we compare experimentally on downstream tasks in the TV-Movies domain, such as MovieLens tag prediction from user reviews and natural language movie search. As evidenced by results, our models match or outperform competitive baselines, sometimes with little or no fine-tuning, and can scale to very large corpora. Finally, we make our datasets and pre-trained models publicly available. This includes Reviews2Movielens (see https://goo.gle/research-docent ), mapping the up to 1B word corpus of Amazon movie reviews (He and McAuley, 2016) to MovieLens tags (Harper and Konstan, 2016), as well as Reddit Movie Suggestions (see https://urikz.github.io/docent ) with natural language queries and corresponding community recommendations.
A Hierarchical Multi-Modal Encoder for Moment Localization in Video Corpus
Nov 24, 2020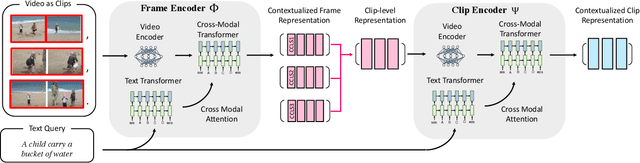
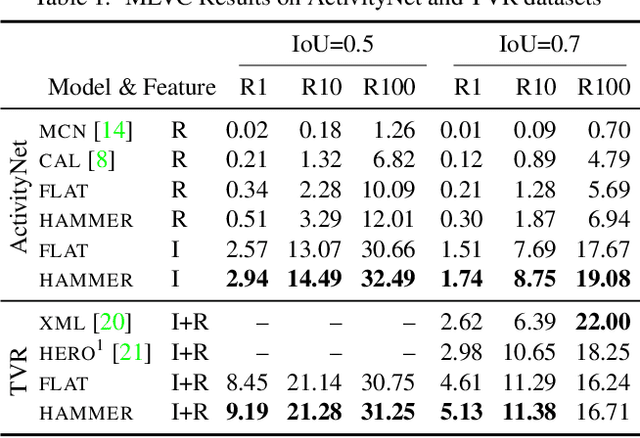
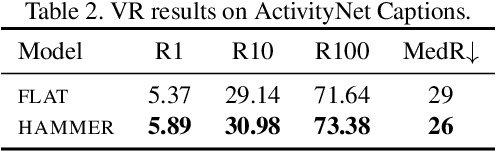
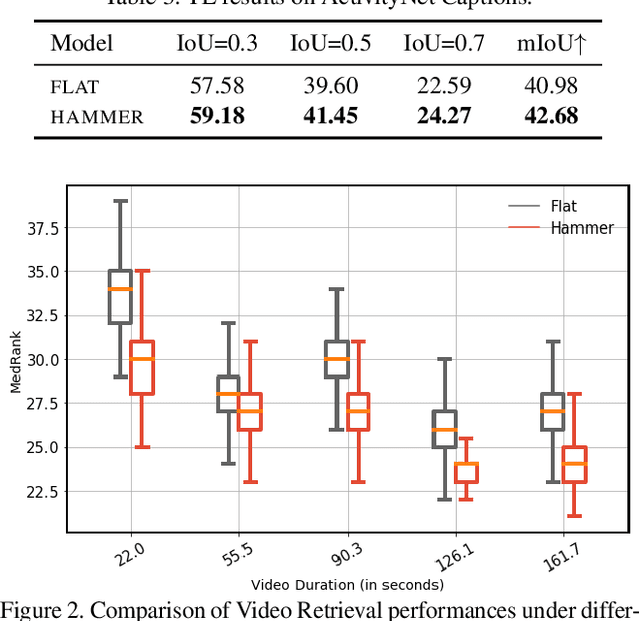
Identifying a short segment in a long video that semantically matches a text query is a challenging task that has important application potentials in language-based video search, browsing, and navigation. Typical retrieval systems respond to a query with either a whole video or a pre-defined video segment, but it is challenging to localize undefined segments in untrimmed and unsegmented videos where exhaustively searching over all possible segments is intractable. The outstanding challenge is that the representation of a video must account for different levels of granularity in the temporal domain. To tackle this problem, we propose the HierArchical Multi-Modal EncodeR (HAMMER) that encodes a video at both the coarse-grained clip level and the fine-grained frame level to extract information at different scales based on multiple subtasks, namely, video retrieval, segment temporal localization, and masked language modeling. We conduct extensive experiments to evaluate our model on moment localization in video corpus on ActivityNet Captions and TVR datasets. Our approach outperforms the previous methods as well as strong baselines, establishing new state-of-the-art for this task.
AQuaMuSe: Automatically Generating Datasets for Query-Based Multi-Document Summarization
Oct 23, 2020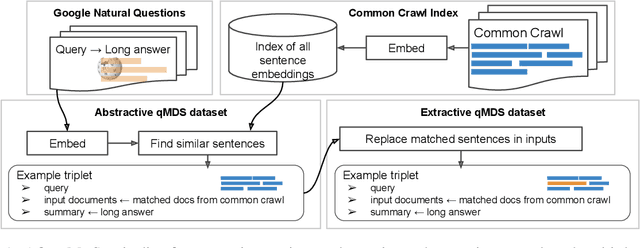

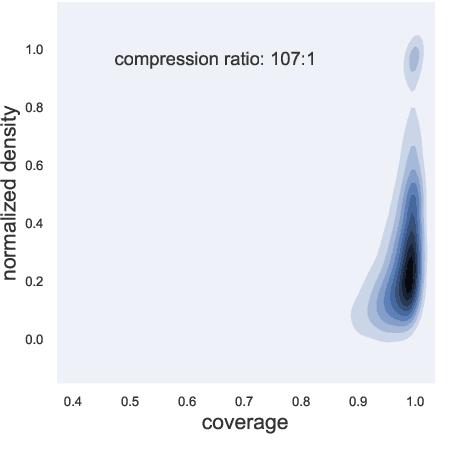
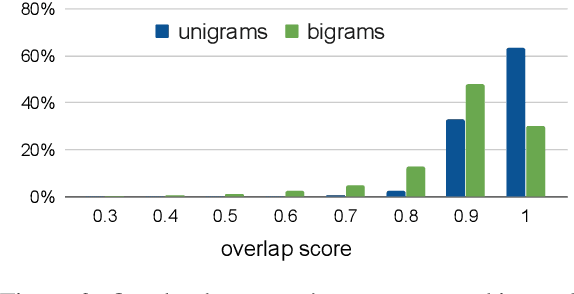
Summarization is the task of compressing source document(s) into coherent and succinct passages. This is a valuable tool to present users with concise and accurate sketch of the top ranked documents related to their queries. Query-based multi-document summarization (qMDS) addresses this pervasive need, but the research is severely limited due to lack of training and evaluation datasets as existing single-document and multi-document summarization datasets are inadequate in form and scale. We propose a scalable approach called AQuaMuSe to automatically mine qMDS examples from question answering datasets and large document corpora. Our approach is unique in the sense that it can general a dual dataset -- for extractive and abstractive summaries both. We publicly release a specific instance of an AQuaMuSe dataset with 5,519 query-based summaries, each associated with an average of 6 input documents selected from an index of 355M documents from Common Crawl. Extensive evaluation of the dataset along with baseline summarization model experiments are provided.
Learning to Represent Image and Text with Denotation Graph
Oct 06, 2020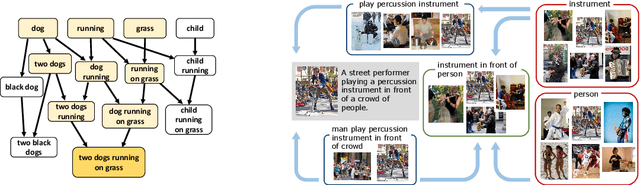

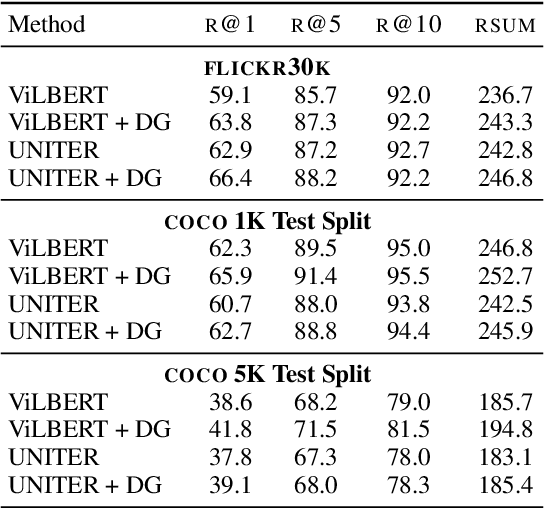
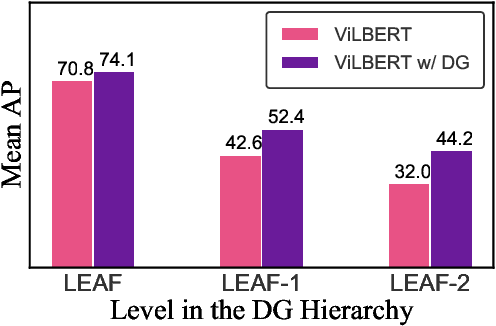
Learning to fuse vision and language information and representing them is an important research problem with many applications. Recent progresses have leveraged the ideas of pre-training (from language modeling) and attention layers in Transformers to learn representation from datasets containing images aligned with linguistic expressions that describe the images. In this paper, we propose learning representations from a set of implied, visually grounded expressions between image and text, automatically mined from those datasets. In particular, we use denotation graphs to represent how specific concepts (such as sentences describing images) can be linked to abstract and generic concepts (such as short phrases) that are also visually grounded. This type of generic-to-specific relations can be discovered using linguistic analysis tools. We propose methods to incorporate such relations into learning representation. We show that state-of-the-art multimodal learning models can be further improved by leveraging automatically harvested structural relations. The representations lead to stronger empirical results on downstream tasks of cross-modal image retrieval, referring expression, and compositional attribute-object recognition. Both our codes and the extracted denotation graphs on the Flickr30K and the COCO datasets are publically available on https://sha-lab.github.io/DG.
Drinking from a Firehose: Continual Learning with Web-scale Natural Language
Jul 18, 2020

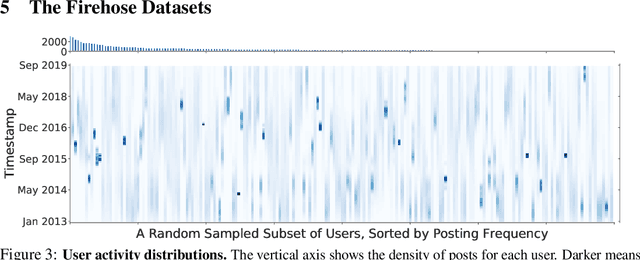

Continual learning systems will interact with humans, with each other, and with the physical world through time -- and continue to learn and adapt as they do. Such systems have typically been evaluated in artificial settings: for example, classifying randomly permuted images. A key limitation of these settings is the unnatural construct of discrete, sharply demarcated tasks that are solved in sequence. In this paper, we study a natural setting for continual learning on a massive scale. We introduce the problem of personalized online language learning (POLL), which involves fitting personalized language models to a population of users that evolves over time. To facilitate research on POLL, we collect massive datasets of Twitter posts. These datasets, Firehose10M and Firehose100M, comprise 100 million tweets, posted by one million users over six years. Enabled by the Firehose datasets, we present a rigorous evaluation of continual learning algorithms on an unprecedented scale. Based on this analysis, we develop a simple algorithm for continual gradient descent (ConGraD) that outperforms prior continual learning methods on the Firehose datasets as well as earlier benchmarks. Collectively, the POLL problem setting, the Firehose datasets, and the ConGraD algorithm enable reproducible research on web-scale continual learning.