 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"It's Not Just Hate'': A Multi-Dimensional Perspective on Detecting Harmful Speech Online
Oct 28, 2022Well-annotated data is a prerequisite for good Natural Language Processing models. Too often, though, annotation decisions are governed by optimizing time or annotator agreement. We make a case for nuanced efforts in an interdisciplinary setting for annotating offensive online speech. Detecting offensive content is rapidly becoming one of the most important real-world NLP tasks. However, most datasets use a single binary label, e.g., for hate or incivility, even though each concept is multi-faceted. This modeling choice severely limits nuanced insights, but also performance. We show that a more fine-grained multi-label approach to predicting incivility and hateful or intolerant content addresses both conceptual and performance issues. We release a novel dataset of over 40,000 tweets about immigration from the US and UK, annotated with six labels for different aspects of incivility and intolerance. Our dataset not only allows for a more nuanced understanding of harmful speech online, models trained on it also outperform or match performance on benchmark datasets.
ProSiT! Latent Variable Discovery with PROgressive SImilarity Thresholds
Oct 26, 2022



The most common ways to explore latent document dimensions are topic models and clustering methods. However, topic models have several drawbacks: e.g., they require us to choose the number of latent dimensions a priori, and the results are stochastic. Most clustering methods have the same issues and lack flexibility in various ways, such as not accounting for the influence of different topics on single documents, forcing word-descriptors to belong to a single topic (hard-clustering) or necessarily relying on word representations. We propose PROgressive SImilarity Thresholds - ProSiT, a deterministic and interpretable method, agnostic to the input format, that finds the optimal number of latent dimensions and only has two hyper-parameters, which can be set efficiently via grid search. We compare this method with a wide range of topic models and clustering methods on four benchmark data sets. In most setting, ProSiT matches or outperforms the other methods in terms six metrics of topic coherence and distinctiveness, producing replicable, deterministic results.
Data-Efficient Strategies for Expanding Hate Speech Detection into Under-Resourced Languages
Oct 20, 2022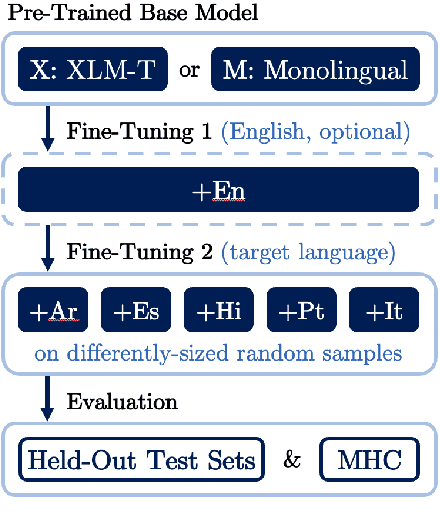
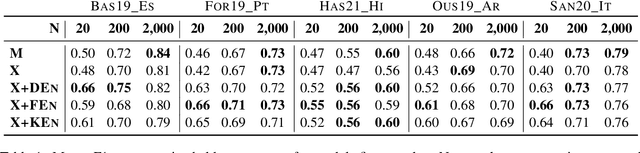
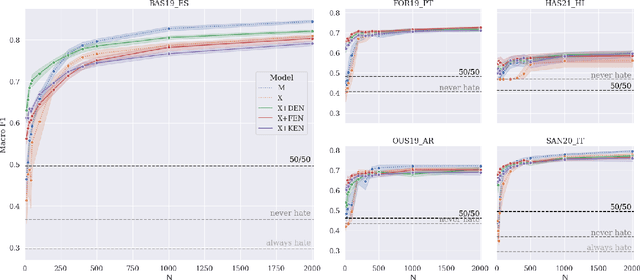
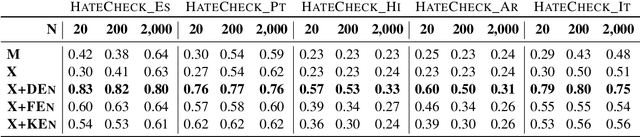
Hate speech is a global phenomenon, but most hate speech datasets so far focus on English-language content. This hinders the development of more effective hate speech detection models in hundreds of languages spoken by billions across the world. More data is needed, but annotating hateful content is expensive, time-consuming and potentially harmful to annotators. To mitigate these issues, we explore data-efficient strategies for expanding hate speech detection into under-resourced languages. In a series of experiments with mono- and multilingual models across five non-English languages, we find that 1) a small amount of target-language fine-tuning data is needed to achieve strong performance, 2) the benefits of using more such data decrease exponentially, and 3) initial fine-tuning on readily-available English data can partially substitute target-language data and improve model generalisability. Based on these findings, we formulate actionable recommendations for hate speech detection in low-resource language settings.
Is It Worth the Cost? Limited Evidence for the Benefits of Diachronic Continuous Training
Oct 13, 2022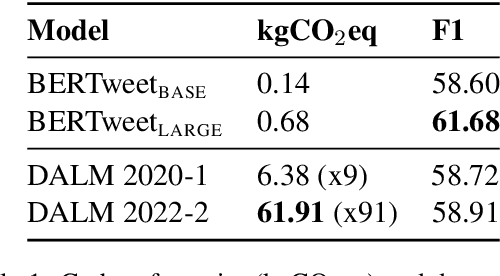
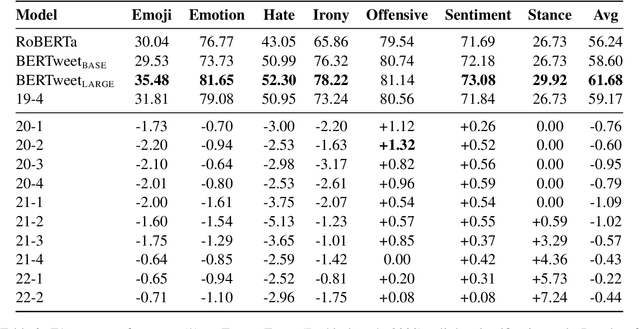
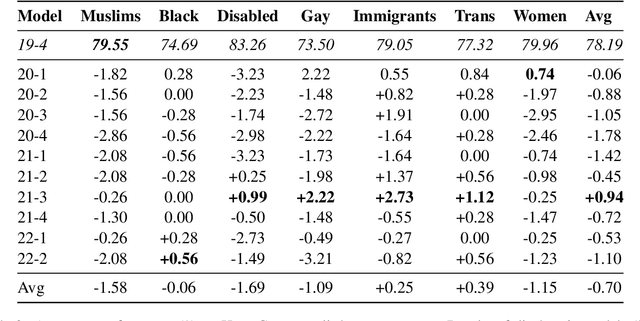
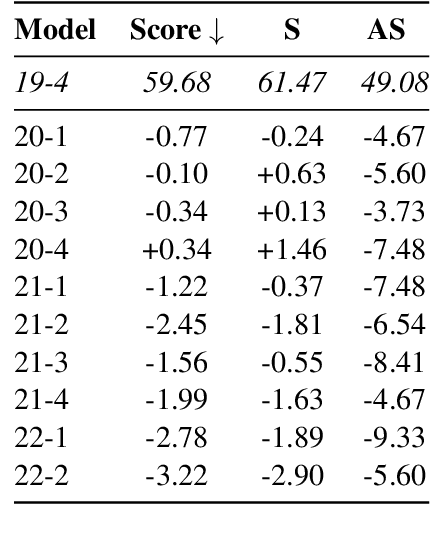
Language is constantly changing and evolving, leaving language models to quickly become outdated, both factually and linguistically. Recent research proposes we continuously update our models using new data. Continuous training allows us to teach language models about new events and facts and changing norms. However, continuous training also means continuous costs. We show there is currently limited evidence for the benefits of continuous training, be it for the actual downstream performance or the environmental cost. Our results show continuous training does not significantly improve performance. While it is clear that, sooner or later, our language models need to be updated, it is unclear when this effort is worth the cost. We call for a critical reflection about when and how to use continuous training and for more benchmarks to support this research direction.
When and why vision-language models behave like bags-of-words, and what to do about it?
Oct 06, 2022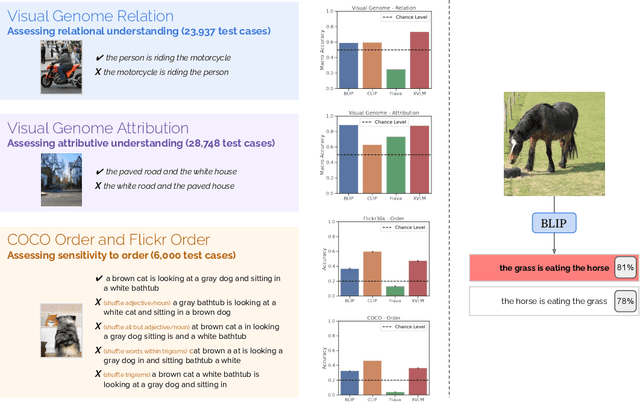

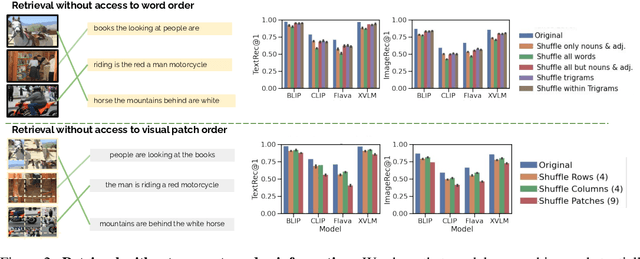
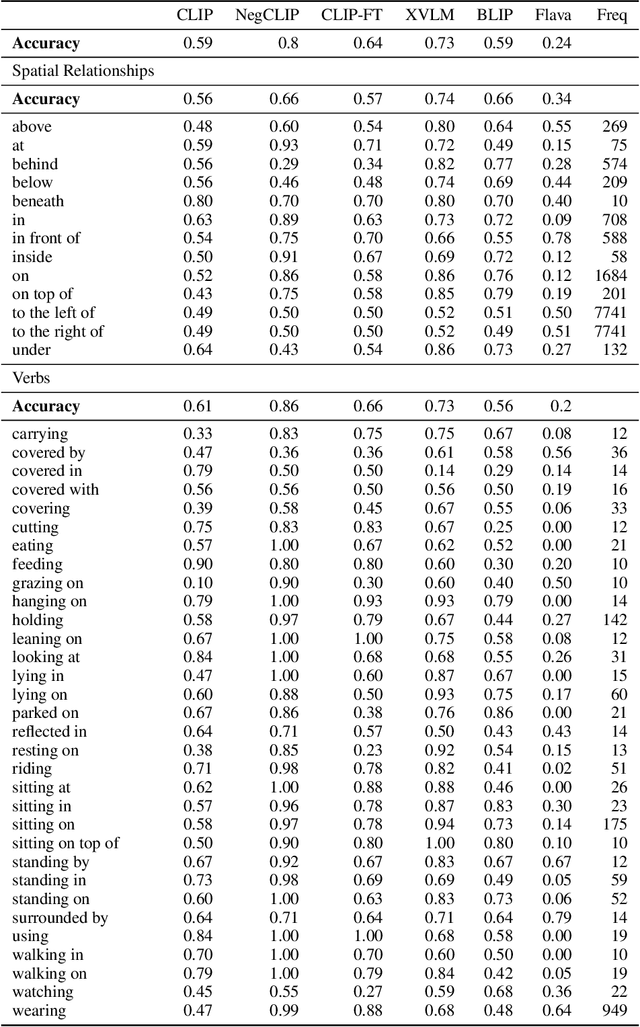
Despite the success of large vision and language models (VLMs) in many downstream applications, it is unclear how well they encode compositional information. Here, we create the Attribution, Relation, and Order (ARO) benchmark to systematically evaluate the ability of VLMs to understand different types of relationships, attributes, and order. ARO consists of Visual Genome Attribution, to test the understanding of objects' properties; Visual Genome Relation, to test for relational understanding; and COCO & Flickr30k-Order, to test for order sensitivity. ARO is orders of magnitude larger than previous benchmarks of compositionality, with more than 50,000 test cases. We show where state-of-the-art VLMs have poor relational understanding, can blunder when linking objects to their attributes, and demonstrate a severe lack of order sensitivity. VLMs are predominantly trained and evaluated on large datasets with rich compositional structure in the images and captions. Yet, training on these datasets has not been enough to address the lack of compositional understanding, and evaluating on these datasets has failed to surface this deficiency. To understand why these limitations emerge and are not represented in the standard tests, we zoom into the evaluation and training procedures. We demonstrate that it is possible to perform well on retrieval over existing datasets without using the composition and order information. Given that contrastive pretraining optimizes for retrieval on datasets with similar shortcuts, we hypothesize that this can explain why the models do not need to learn to represent compositional information. This finding suggests a natural solution: composition-aware hard negative mining. We show that a simple-to-implement modification of contrastive learning significantly improves the performance on tasks requiring understanding of order and compositionality.
Real-Time Oil Leakage Detection on Aftermarket Motorcycle Damping System with Convolutional Neural Networks
Aug 10, 2022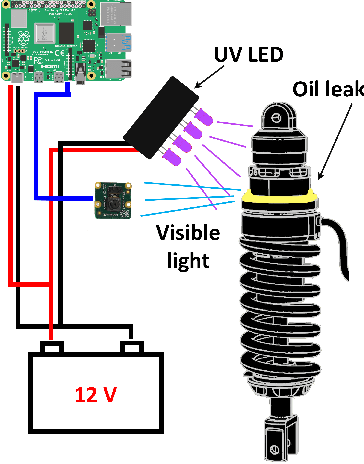

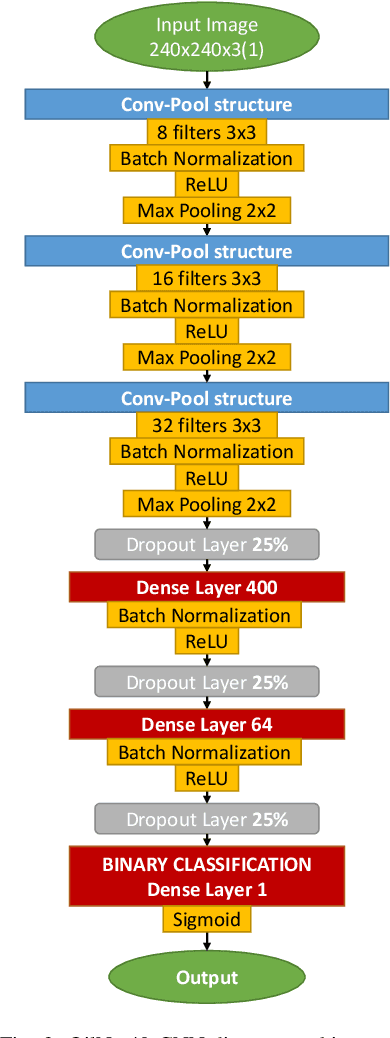
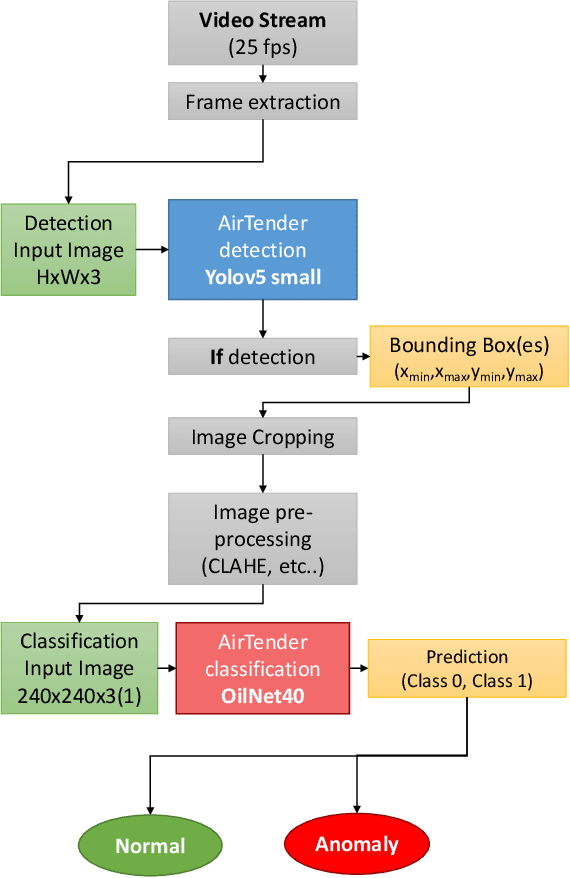
In this work, we describe in detail how Deep Learning and Computer Vision can help to detect fault events of the AirTender system, an aftermarket motorcycle damping system component. One of the most effective ways to monitor the AirTender functioning is to look for oil stains on its surface. Starting from real-time images, AirTender is first detected in the motorbike suspension system and then a binary classifier determines whether AirTender is spilling oil or not. The detection is made with the help of the Yolo5 architecture, whereas the classification is carried out with the help of a suitably designed Convolutional Neural Network, OilNet40. In order to detect oil leaks more clearly, we dilute the oil in AirTender with a fluorescent dye with excitation wavelength peak of approximately 390 nm. AirTender is then illuminated with suitable UV LEDs. The whole system is an attempt to design a low-cost detection setup. An on-board device, such as a mini-computer, is placed near the suspension system and connected to a full hd camera framing AirTender. The on-board device, through our Neural Network algorithm, is then able to localize and classify AirTender as normally functioning (non-leak image) or anomaly (leak image).
EvalRS: a Rounded Evaluation of Recommender Systems
Jul 12, 2022
Much of the complexity of Recommender Systems (RSs) comes from the fact that they are used as part of more complex applications and affect user experience through a varied range of user interfaces. However, research focused almost exclusively on the ability of RSs to produce accurate item rankings while giving little attention to the evaluation of RS behavior in real-world scenarios. Such narrow focus has limited the capacity of RSs to have a lasting impact in the real world and makes them vulnerable to undesired behavior, such as reinforcing data biases. We propose EvalRS as a new type of challenge, in order to foster this discussion among practitioners and build in the open new methodologies for testing RSs "in the wild".
FashionCLIP: Connecting Language and Images for Product Representations
Apr 11, 2022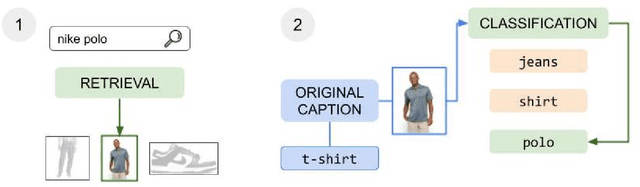
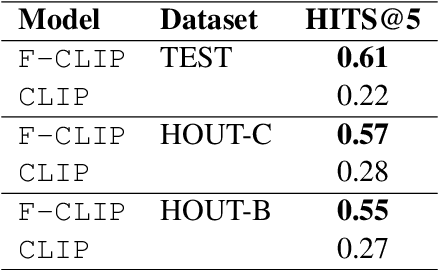

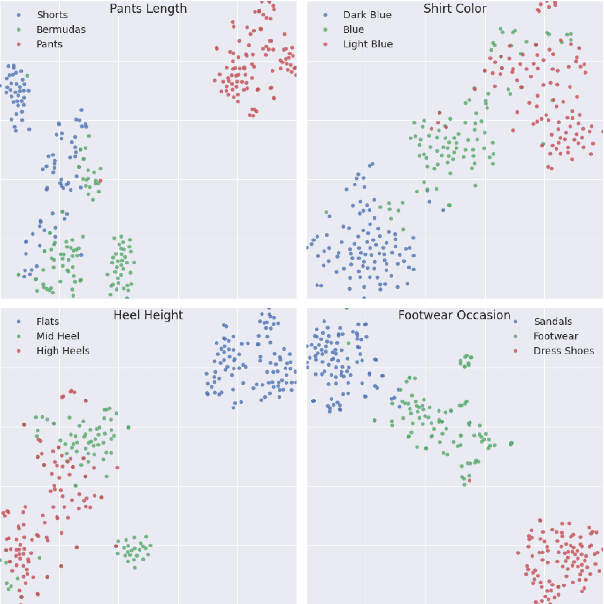
The steady rise of online shopping goes hand in hand with the development of increasingly complex ML and NLP models. While most use cases are cast as specialized supervised learning problems, we argue that practitioners would greatly benefit from more transferable representations of products. In this work, we build on recent developments in contrastive learning to train FashionCLIP, a CLIP-like model for the fashion industry. We showcase its capabilities for retrieval, classification and grounding, and release our model and code to the community.
"Does it come in black?" CLIP-like models are zero-shot recommenders
Apr 11, 2022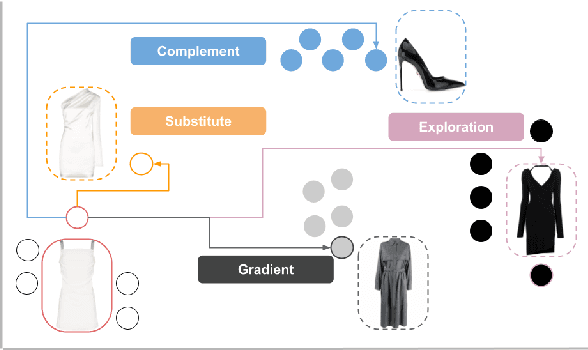


Product discovery is a crucial component for online shopping. However, item-to-item recommendations today do not allow users to explore changes along selected dimensions: given a query item, can a model suggest something similar but in a different color? We consider item recommendations of the comparative nature (e.g. "something darker") and show how CLIP-based models can support this use case in a zero-shot manner. Leveraging a large model built for fashion, we introduce GradREC and its industry potential, and offer a first rounded assessment of its strength and weaknesses.
Twitter-Demographer: A Flow-based Tool to Enrich Twitter Data
Jan 26, 2022

Twitter data have become essential to Natural Language Processing (NLP) and social science research, driving various scientific discoveries in recent years. However, the textual data alone are often not enough to conduct studies: especially social scientists need more variables to perform their analysis and control for various factors. How we augment this information, such as users' location, age, or tweet sentiment, has ramifications for anonymity and reproducibility, and requires dedicated effort. This paper describes Twitter-Demographer, a simple, flow-based tool to enrich Twitter data with additional information about tweets and users. Twitter-Demographer is aimed at NLP practitioners and (computational) social scientists who want to enrich their datasets with aggregated information, facilitating reproducibility, and providing algorithmic privacy-by-design measures for pseudo-anonymity. We discuss our design choices, inspired by the flow-based programming paradigm, to use black-box components that can easily be chained together and extended. We also analyze the ethical issues related to the use of this tool, and the built-in measures to facilitate pseudo-anonymity.