 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Player, Multi-Strategy Quantum Game Model for Interaction-Aware Decision-Making in Autonomous Driving
Feb 03, 2026Although significant progress has been made in decision-making for automated driving, challenges remain for deployment in the real world. One challenge lies in addressing interaction-awareness. Most existing approaches oversimplify interactions between the ego vehicle and surrounding agents, and often neglect interactions among the agents themselves. A common solution is to model these interactions using classical game theory. However, its formulation assumes rational players, whereas human behavior is frequently uncertain or irrational. To address these challenges, we propose the Quantum Game Decision-Making (QGDM) model, a novel framework that combines classical game theory with quantum mechanics principles (such as superposition, entanglement, and interference) to tackle multi-player, multi-strategy decision-making problems. To the best of our knowledge, this is one of the first studies to apply quantum game theory to decision-making for automated driving. QGDM runs in real time on a standard computer, without requiring quantum hardware. We evaluate QGDM in simulation across various scenarios, including roundabouts, merging, and highways, and compare its performance with multiple baseline methods. Results show that QGDM significantly improves success rates and reduces collision rates compared to classical approaches, particularly in scenarios with high interaction.
An Extended Horizon Tactical Decision-Making for Automated Driving Based on Monte Carlo Tree Search
Apr 22, 2025This paper introduces COR-MCTS (Conservation of Resources - Monte Carlo Tree Search), a novel tactical decision-making approach for automated driving focusing on maneuver planning over extended horizons. Traditional decision-making algorithms are often constrained by fixed planning horizons, typically up to 6 seconds for classical approaches and 3 seconds for learning-based methods limiting their adaptability in particular dynamic driving scenarios. However, planning must be done well in advance in environments such as highways, roundabouts, and exits to ensure safe and efficient maneuvers. To address this challenge, we propose a hybrid method integrating Monte Carlo Tree Search (MCTS) with our prior utility-based framework, COR-MP (Conservation of Resources Model for Maneuver Planning). This combination enables long-term, real-time decision-making, significantly enhancing the ability to plan a sequence of maneuvers over extended horizons. Through simulations across diverse driving scenarios, we demonstrate that COR-MCTS effectively improves planning robustness and decision efficiency over extended horizons.
COR-MP: Conservation of Resources Model for Maneuver Planning
Oct 25, 2024Decision-making for automated driving remains a challenging task. For their integration into real platforms, these algorithms must guarantee passenger safety and comfort while ensuring interpretability and an appropriate computational time. To model and solve this decision-making problem, we have developed a novel approach called COR-MP (Conservation of Resources model for Maneuver Planning). This model is based on the Conservation of Resources theory, a psychological concept applied to human behavior. COR-MP is based on various driving parameters, such as comfort, safety, or energy, and provides in real-time a profit value that enables us to quantify the impact of a decision on the decision-maker. Our method has been tested and validated through closed-loop simulations using RTMaps middleware, and preliminary results have been obtained by testing COR-MP on a real vehicle.
Improving behavior profile discovery for vehicles
Sep 24, 2024



Multiple approaches have already been proposed to mimic real driver behaviors in simulation. This article proposes a new one, based solely on the exploration of undisturbed observation of intersections. From them, the behavior profiles for each macro-maneuver will be discovered. Using the macro-maneuvers already identified in previous works, a comparison method between trajectories with different lengths using an Extended Kalman Filter (EKF) is proposed, which combined with an Expectation-Maximization (EM) inspired method, defines the different clusters that represent the behaviors observed. This is also paired with a Kullback-Liebler divergent (KL) criteria to define when the clusters need to be split or merged. Finally, the behaviors for each macro-maneuver are determined by each cluster discovered, without using any map information about the environment and being dynamically consistent with vehicle motion. By observation it becomes clear that the two main factors for driver's behavior are their assertiveness and interaction with other road users.
Fast maneuver recovery from aerial observation: trajectory clustering and outliers rejection
Jul 03, 2024



The implementation of road user models that realistically reproduce a credible behavior in a multi-agentsimulation is still an open problem. A data-driven approach consists on to deduce behaviors that may exist in real situation to obtain different types of trajectories from a large set of observations. The data, and its classification, could then be used to train models capable to extrapolate such behavior. Cars and two different types of Vulnerable Road Users (VRU) will be considered by the trajectory clustering methods proposed: pedestrians and cyclists. The results reported here evaluate methods to extract well-defined trajectory classes from raw data without the use of map information while also separating ''eccentric'' or incomplete trajectories from the ones that are complete and representative in any scenario. Two environments will serve as test for the methods develop, three different intersections and one roundabout. The resulting clusters of trajectories can then be used for prediction or learning tasks or discarded if it is composed by outliers.
Interpretable Long Term Waypoint-Based Trajectory Prediction Model
Dec 11, 2023



Predicting the future trajectories of dynamic agents in complex environments is crucial for a variety of applications, including autonomous driving, robotics, and human-computer interaction. It is a challenging task as the behavior of the agent is unknown and intrinsically multimodal. Our key insight is that the agents behaviors are influenced not only by their past trajectories and their interaction with their immediate environment but also largely with their long term waypoint (LTW). In this paper, we study the impact of adding a long-term goal on the performance of a trajectory prediction framework. We present an interpretable long term waypoint-driven prediction framework (WayDCM). WayDCM first predict an agent's intermediate goal (IG) by encoding his interactions with the environment as well as his LTW using a combination of a Discrete choice Model (DCM) and a Neural Network model (NN). Then, our model predicts the corresponding trajectories. This is in contrast to previous work which does not consider the ultimate intent of the agent to predict his trajectory. We evaluate and show the effectiveness of our approach on the Waymo Open dataset.
* arXiv admin note: text overlap with arXiv:2308.04312
Hierarchical Attention and Graph Neural Networks: Toward Drift-Free Pose Estimation
Sep 18, 2023



The most commonly used method for addressing 3D geometric registration is the iterative closet-point algorithm, this approach is incremental and prone to drift over multiple consecutive frames. The Common strategy to address the drift is the pose graph optimization subsequent to frame-to-frame registration, incorporating a loop closure process that identifies previously visited places. In this paper, we explore a framework that replaces traditional geometric registration and pose graph optimization with a learned model utilizing hierarchical attention mechanisms and graph neural networks. We propose a strategy to condense the data flow, preserving essential information required for the precise estimation of rigid poses. Our results, derived from tests on the KITTI Odometry dataset, demonstrate a significant improvement in pose estimation accuracy. This improvement is especially notable in determining rotational components when compared with results obtained through conventional multi-way registration via pose graph optimization. The code will be made available upon completion of the review process.
Interpretable Goal-Based model for Vehicle Trajectory Prediction in Interactive Scenarios
Aug 08, 2023



The abilities to understand the social interaction behaviors between a vehicle and its surroundings while predicting its trajectory in an urban environment are critical for road safety in autonomous driving. Social interactions are hard to explain because of their uncertainty. In recent years, neural network-based methods have been widely used for trajectory prediction and have been shown to outperform hand-crafted methods. However, these methods suffer from their lack of interpretability. In order to overcome this limitation, we combine the interpretability of a discrete choice model with the high accuracy of a neural network-based model for the task of vehicle trajectory prediction in an interactive environment. We implement and evaluate our model using the INTERACTION dataset and demonstrate the effectiveness of our proposed architecture to explain its predictions without compromising the accuracy.
Trajectory Prediction for Autonomous Driving based on Multi-Head Attention with Joint Agent-Map Representation
Jun 04, 2020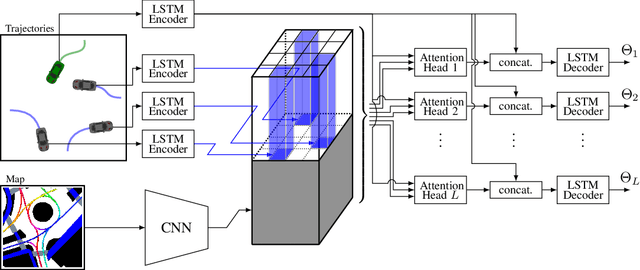

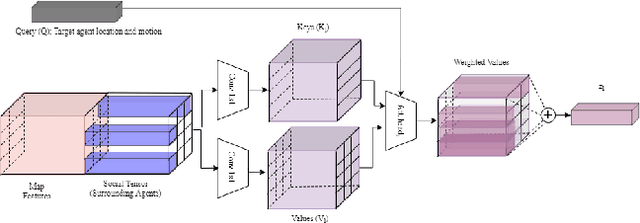
Predicting the trajectories of surrounding agents is an essential ability for robots navigating complex real-world environments. Autonomous vehicles (AV) in particular, can generate safe and efficient path plans by predicting the motion of surrounding road users. Future trajectories of agents can be inferred using two tightly linked cues: the locations and past motion of agents, and the static scene structure. The configuration of the agents may uncover which part of the scene is more relevant, while the scene structure can determine the relative influence of agents on each other's motion. To better model the interdependence of the two cues, we propose a multi-head attention-based model that uses a joint representation of the static scene and agent configuration for generating both keys and values for the attention heads. Moreover, to address the multimodality of future agent motion, we propose to use each attention head to generate a distinct future trajectory of the agent. Our model achieves state of the art results on the publicly available nuScenes dataset and generates diverse future trajectories compliant with scene structure and agent configuration. Additionally, the visualization of attention maps adds a layer of interpretability to the trajectories predicted by the model.
End-to-End Race Driving with Deep Reinforcement Learning
Aug 31, 2018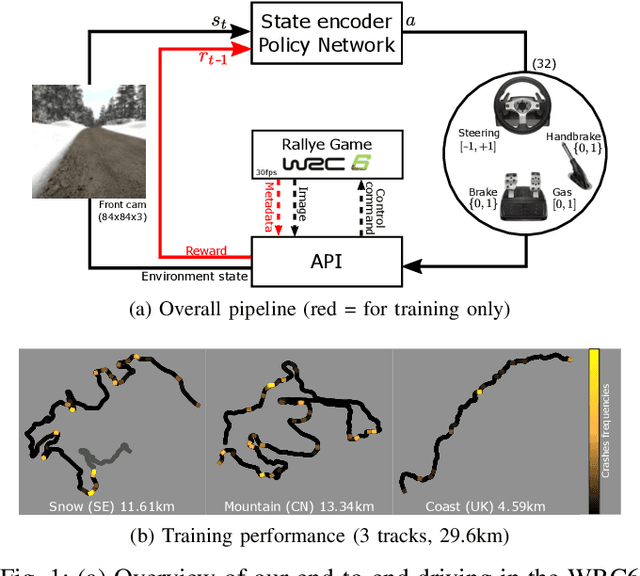
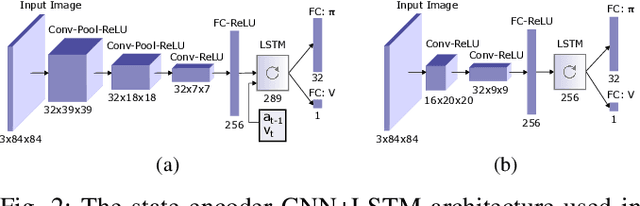
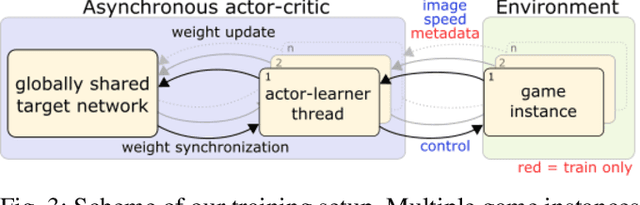
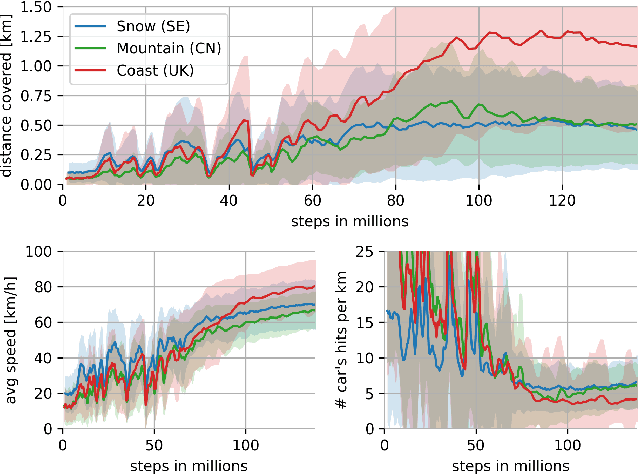
We present research using the latest reinforcement learning algorithm for end-to-end driving without any mediated perception (object recognition, scene understanding). The newly proposed reward and learning strategies lead together to faster convergence and more robust driving using only RGB image from a forward facing camera. An Asynchronous Actor Critic (A3C) framework is used to learn the car control in a physically and graphically realistic rally game, with the agents evolving simultaneously on tracks with a variety of road structures (turns, hills), graphics (seasons, location) and physics (road adherence). A thorough evaluation is conducted and generalization is proven on unseen tracks and using legal speed limits. Open loop tests on real sequences of images show some domain adaption capability of our method.