 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint sparse coding and temporal dynamics support context reconfiguration
May 11, 2026Adaptive behavior requires the brain to transition between distinct contexts while maintaining representations of prior experience. The ability to reconfigure neural representations without erasing previously acquired knowledge is central to learning in dynamic environments, yet the neural mechanisms that support this balance remain unclear. Understanding these mechanisms is also critical for addressing catastrophic forgetting in artificial systems designed for lifelong learning. Here, we identify joint sparse coding and temporal dynamics in both the mouse medial prefrontal cortex (mPFC) and computational networks as mechanisms that help preserve prior representations during context transitions. Specifically, sparsity in context-dependent representations reduces cross-context interference, whereas temporal dynamics within the network activity further enhance context separability across time. Strikingly, networks endowed with both properties, such as spiking neural networks, exhibit improved retention during lifelong learning without auxiliary heuristics. These findings establish joint sparse coding and temporal dynamics as a core mechanism supporting flexible context reconfiguration in lifelong learning and, through their activity constraining nature, as an energy-efficient architectural principle for stable adaptation. Together, they provide a mechanistic framework for understanding how the brain preserves prior knowledge while flexibly adapting to new contexts.
Mitigating Hallucinations in Vision-Language Models through Image-Guided Head Suppression
May 22, 2025


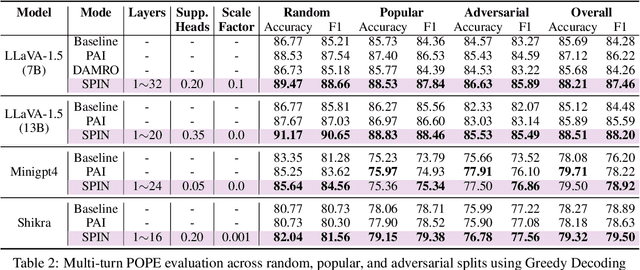
Despite their remarkable progress in multimodal understanding tasks, large vision language models (LVLMs) often suffer from "hallucinations", generating texts misaligned with the visual context. Existing methods aimed at reducing hallucinations through inference time intervention incur a significant increase in latency. To mitigate this, we present SPIN, a task-agnostic attention-guided head suppression strategy that can be seamlessly integrated during inference, without incurring any significant compute or latency overhead. We investigate whether hallucination in LVLMs can be linked to specific model components. Our analysis suggests that hallucinations can be attributed to a dynamic subset of attention heads in each layer. Leveraging this insight, for each text query token, we selectively suppress attention heads that exhibit low attention to image tokens, keeping the top-K attention heads intact. Extensive evaluations on visual question answering and image description tasks demonstrate the efficacy of SPIN in reducing hallucination scores up to 2.7x while maintaining F1, and improving throughput by 1.8x compared to existing alternatives. Code is available at https://github.com/YUECHE77/SPIN.
Region Masking to Accelerate Video Processing on Neuromorphic Hardware
Mar 21, 2025



The rapidly growing demand for on-chip edge intelligence on resource-constrained devices has motivated approaches to reduce energy and latency of deep learning models. Spiking neural networks (SNNs) have gained particular interest due to their promise to reduce energy consumption using event-based processing. We assert that while sigma-delta encoding in SNNs can take advantage of the temporal redundancy across video frames, they still involve a significant amount of redundant computations due to processing insignificant events. In this paper, we propose a region masking strategy that identifies regions of interest at the input of the SNN, thereby eliminating computation and data movement for events arising from unimportant regions. Our approach demonstrates that masking regions at the input not only significantly reduces the overall spiking activity of the network, but also provides significant improvement in throughput and latency. We apply region masking during video object detection on Loihi 2, demonstrating that masking approximately 60% of input regions can reduce energy-delay product by 1.65x over a baseline sigma-delta network, with a degradation in mAP@0.5 by 1.09%.