 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACT: Semi-supervised Domain-adaptive Medical Image Segmentation with Asymmetric Co-training
Jun 09, 2022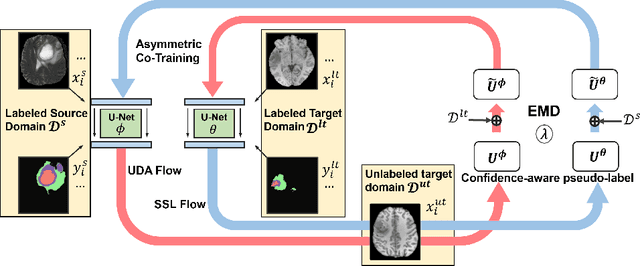
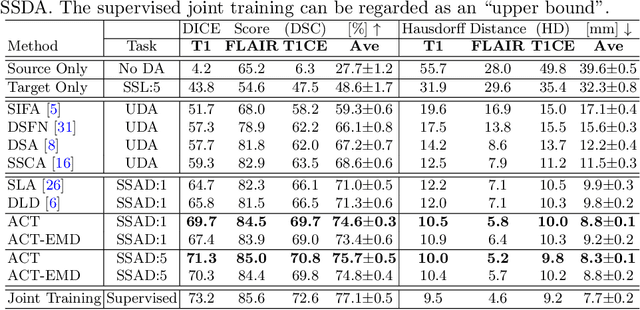
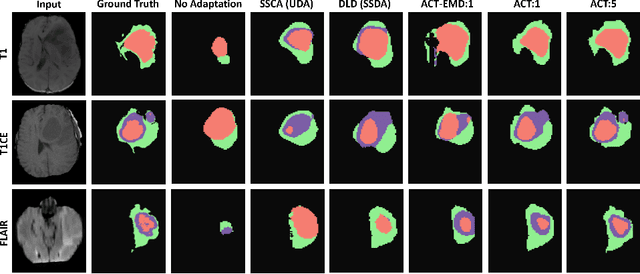
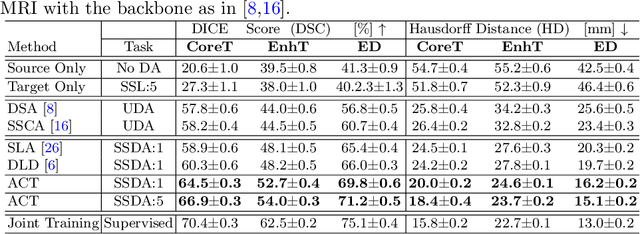
Unsupervised domain adaptation (UDA) has been vastly explored to alleviate domain shifts between source and target domains, by applying a well-performed model in an unlabeled target domain via supervision of a labeled source domain. Recent literature, however, has indicated that the performance is still far from satisfactory in the presence of significant domain shifts. Nonetheless, delineating a few target samples is usually manageable and particularly worthwhile, due to the substantial performance gain. Inspired by this, we aim to develop semi-supervised domain adaptation (SSDA) for medical image segmentation, which is largely underexplored. We, thus, propose to exploit both labeled source and target domain data, in addition to unlabeled target data in a unified manner. Specifically, we present a novel asymmetric co-training (ACT) framework to integrate these subsets and avoid the domination of the source domain data. Following a divide-and-conquer strategy, we explicitly decouple the label supervisions in SSDA into two asymmetric sub-tasks, including semi-supervised learning (SSL) and UDA, and leverage different knowledge from two segmentors to take into account the distinction between the source and target label supervisions. The knowledge learned in the two modules is then adaptively integrated with ACT, by iteratively teaching each other, based on the confidence-aware pseudo-label. In addition, pseudo label noise is well-controlled with an exponential MixUp decay scheme for smooth propagation. Experiments on cross-modality brain tumor MRI segmentation tasks using the BraTS18 database showed, even with limited labeled target samples, ACT yielded marked improvements over UDA and state-of-the-art SSDA methods and approached an "upper bound" of supervised joint training.
Tagged-MRI Sequence to Audio Synthesis via Self Residual Attention Guided Heterogeneous Translator
Jun 09, 2022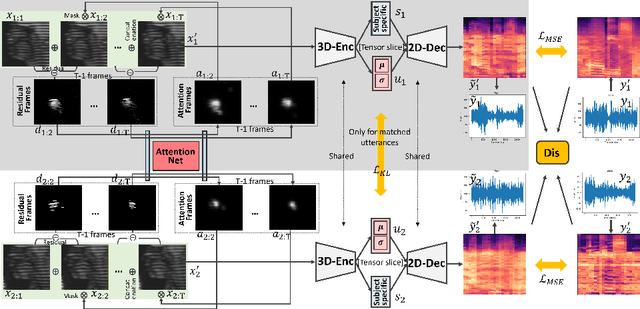
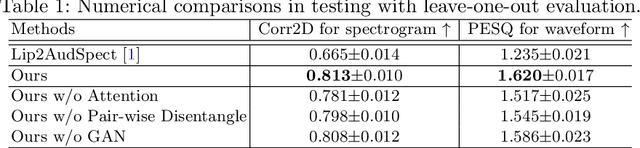
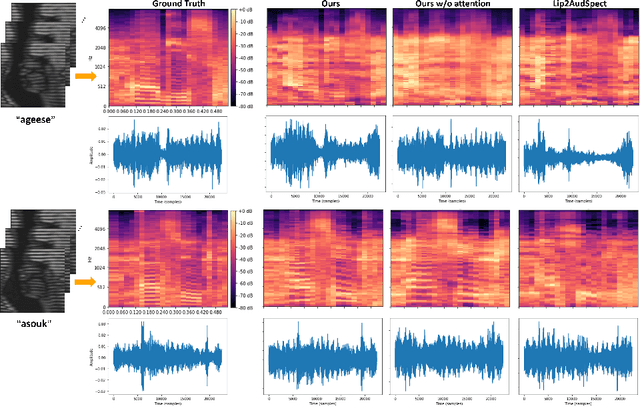
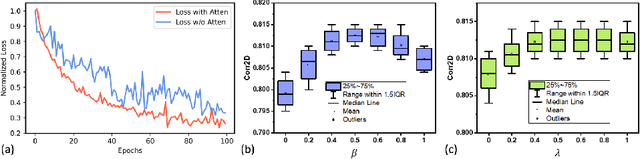
Understanding the underlying relationship between tongue and oropharyngeal muscle deformation seen in tagged-MRI and intelligible speech plays an important role in advancing speech motor control theories and treatment of speech related-disorders. Because of their heterogeneous representations, however, direct mapping between the two modalities -- i.e., two-dimensional (mid-sagittal slice) plus time tagged-MRI sequence and its corresponding one-dimensional waveform -- is not straightforward. Instead, we resort to two-dimensional spectrograms as an intermediate representation, which contains both pitch and resonance, from which to develop an end-to-end deep learning framework to translate from a sequence of tagged-MRI to its corresponding audio waveform with limited dataset size.~Our framework is based on a novel fully convolutional asymmetry translator with guidance of a self residual attention strategy to specifically exploit the moving muscular structures during speech.~In addition, we leverage a pairwise correlation of the samples with the same utterances with a latent space representation disentanglement strategy.~Furthermore, we incorporate an adversarial training approach with generative adversarial networks to offer improved realism on our generated spectrograms.~Our experimental results, carried out with a total of 63 tagged-MRI sequences alongside speech acoustics, showed that our framework enabled the generation of clear audio waveforms from a sequence of tagged-MRI, surpassing competing methods. Thus, our framework provides the great potential to help better understand the relationship between the two modalities.
Structure-aware Unsupervised Tagged-to-Cine MRI Synthesis with Self Disentanglement
Feb 25, 2022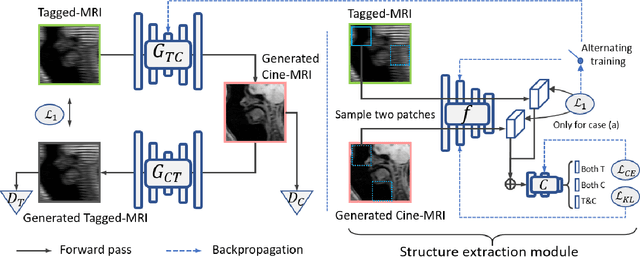

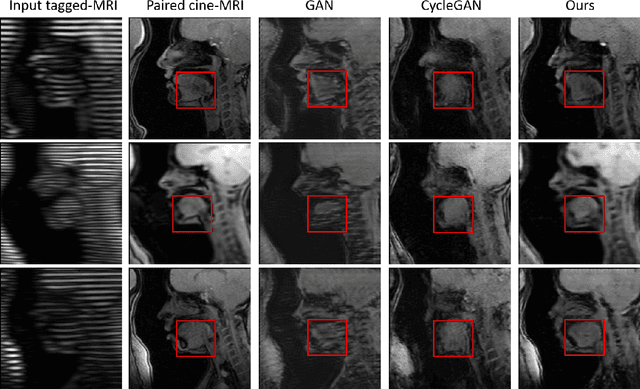
Cycle reconstruction regularized adversarial training -- e.g., CycleGAN, DiscoGAN, and DualGAN -- has been widely used for image style transfer with unpaired training data. Several recent works, however, have shown that local distortions are frequent, and structural consistency cannot be guaranteed. Targeting this issue, prior works usually relied on additional segmentation or consistent feature extraction steps that are task-specific. To counter this, this work aims to learn a general add-on structural feature extractor, by explicitly enforcing the structural alignment between an input and its synthesized image. Specifically, we propose a novel input-output image patches self-training scheme to achieve a disentanglement of underlying anatomical structures and imaging modalities. The translator and structure encoder are updated, following an alternating training protocol. In addition, the information w.r.t. imaging modality can be eliminated with an asymmetric adversarial game. We train, validate, and test our network on 1,768, 416, and 1,560 unpaired subject-independent slices of tagged and cine magnetic resonance imaging from a total of twenty healthy subjects, respectively, demonstrating superior performance over competing methods.
Variational Inference for Quantifying Inter-observer Variability in Segmentation of Anatomical Structures
Jan 18, 2022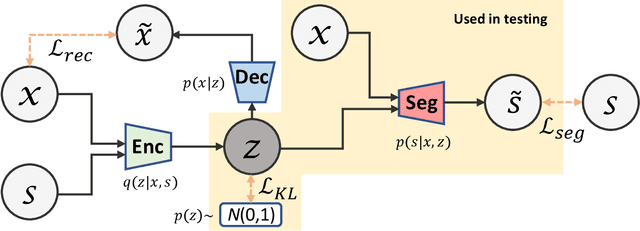

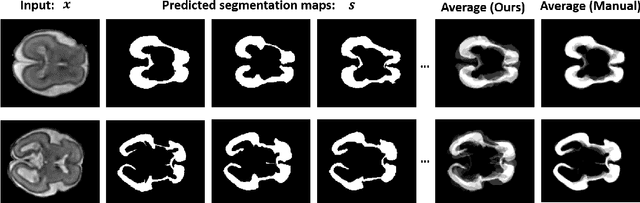

Lesions or organ boundaries visible through medical imaging data are often ambiguous, thus resulting in significant variations in multi-reader delineations, i.e., the source of aleatoric uncertainty. In particular, quantifying the inter-observer variability of manual annotations with Magnetic Resonance (MR) Imaging data plays a crucial role in establishing a reference standard for various diagnosis and treatment tasks. Most segmentation methods, however, simply model a mapping from an image to its single segmentation map and do not take the disagreement of annotators into consideration. In order to account for inter-observer variability, without sacrificing accuracy, we propose a novel variational inference framework to model the distribution of plausible segmentation maps, given a specific MR image, which explicitly represents the multi-reader variability. Specifically, we resort to a latent vector to encode the multi-reader variability and counteract the inherent information loss in the imaging data. Then, we apply a variational autoencoder network and optimize its evidence lower bound (ELBO) to efficiently approximate the distribution of the segmentation map, given an MR image. Experimental results, carried out with the QUBIQ brain growth MRI segmentation datasets with seven annotators, demonstrate the effectiveness of our approach.
Self-semantic contour adaptation for cross modality brain tumor segmentation
Jan 13, 2022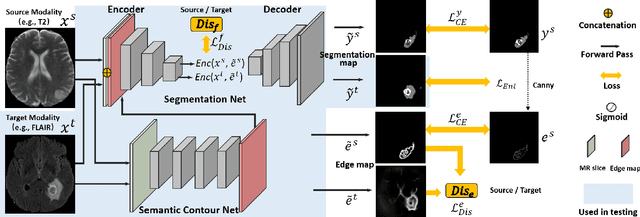
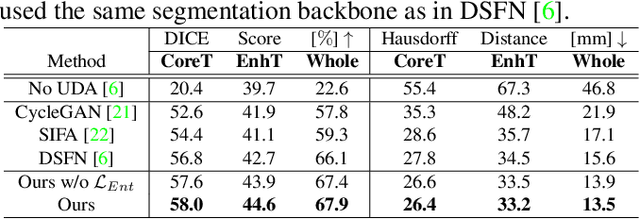
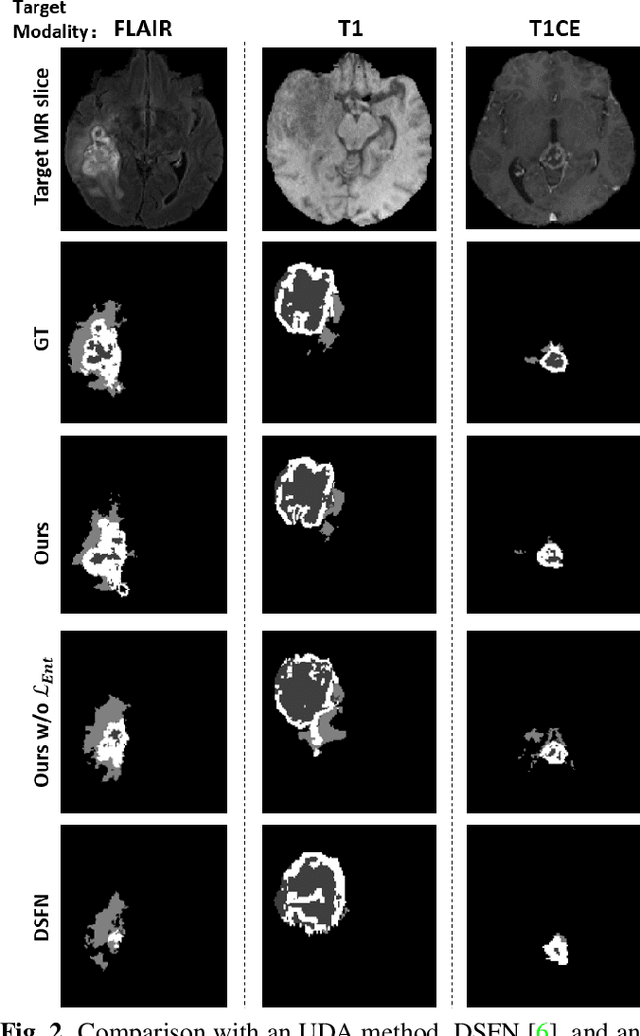
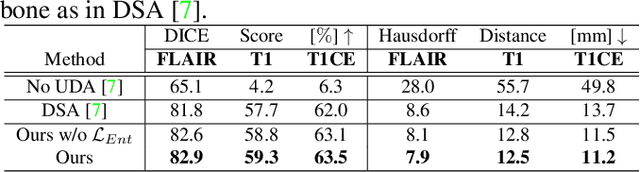
Unsupervised domain adaptation (UDA) between two significantly disparate domains to learn high-level semantic alignment is a crucial yet challenging task.~To this end, in this work, we propose exploiting low-level edge information to facilitate the adaptation as a precursor task, which has a small cross-domain gap, compared with semantic segmentation.~The precise contour then provides spatial information to guide the semantic adaptation. More specifically, we propose a multi-task framework to learn a contouring adaptation network along with a semantic segmentation adaptation network, which takes both magnetic resonance imaging (MRI) slice and its initial edge map as input.~These two networks are jointly trained with source domain labels, and the feature and edge map level adversarial learning is carried out for cross-domain alignment. In addition, self-entropy minimization is incorporated to further enhance segmentation performance. We evaluated our framework on the BraTS2018 database for cross-modality segmentation of brain tumors, showing the validity and superiority of our approach, compared with competing methods.
Adversarial Unsupervised Domain Adaptation with Conditional and Label Shift: Infer, Align and Iterate
Aug 02, 2021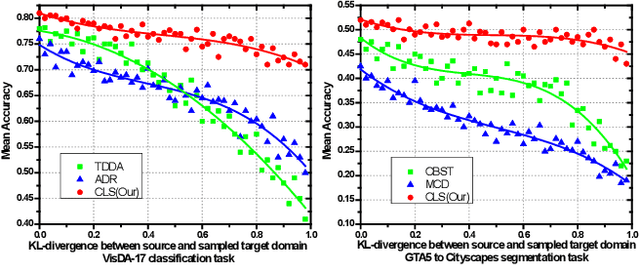
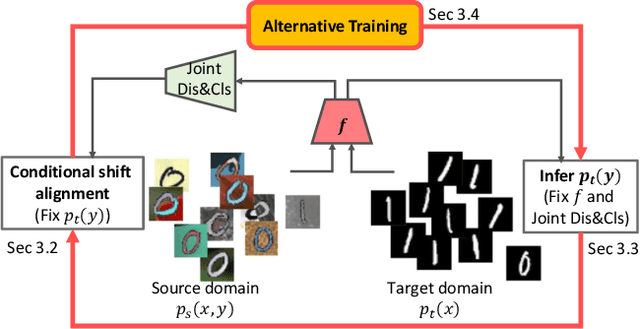
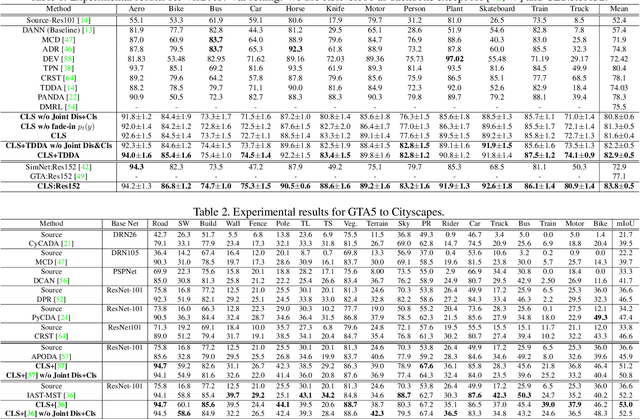
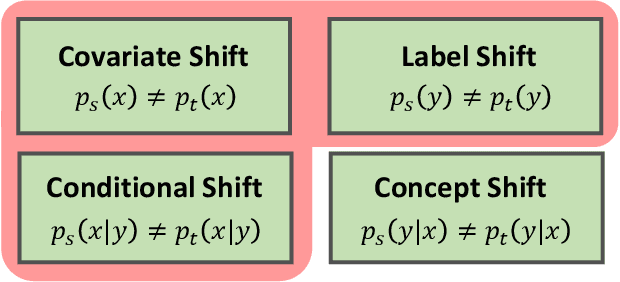
In this work, we propose an adversarial unsupervised domain adaptation (UDA) approach with the inherent conditional and label shifts, in which we aim to align the distributions w.r.t. both $p(x|y)$ and $p(y)$. Since the label is inaccessible in the target domain, the conventional adversarial UDA assumes $p(y)$ is invariant across domains, and relies on aligning $p(x)$ as an alternative to the $p(x|y)$ alignment. To address this, we provide a thorough theoretical and empirical analysis of the conventional adversarial UDA methods under both conditional and label shifts, and propose a novel and practical alternative optimization scheme for adversarial UDA. Specifically, we infer the marginal $p(y)$ and align $p(x|y)$ iteratively in the training, and precisely align the posterior $p(y|x)$ in testing. Our experimental results demonstrate its effectiveness on both classification and segmentation UDA, and partial UDA.
Domain Generalization under Conditional and Label Shifts via Variational Bayesian Inference
Jul 22, 2021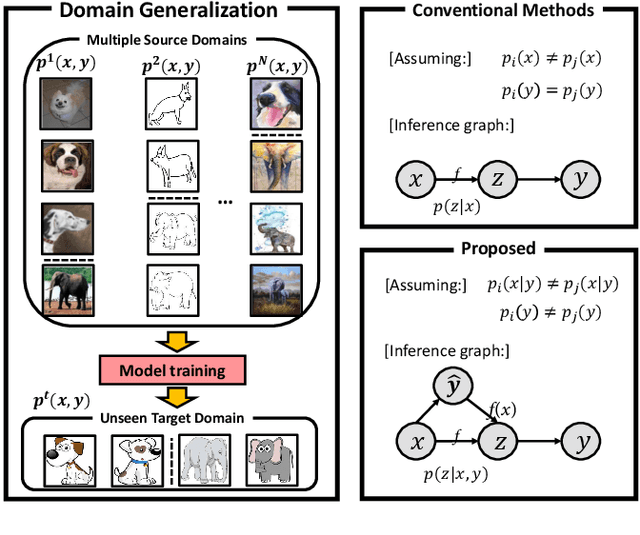
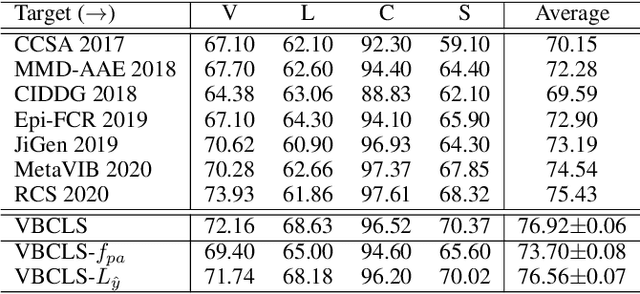
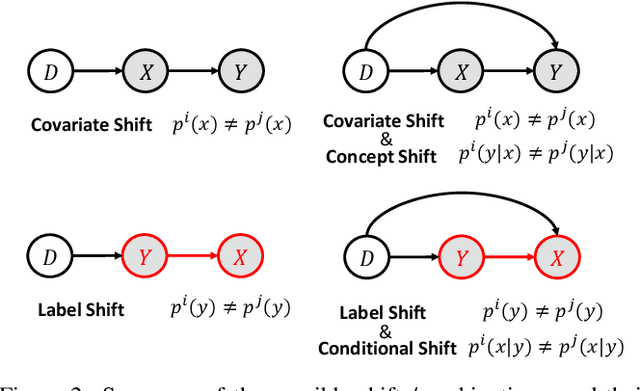
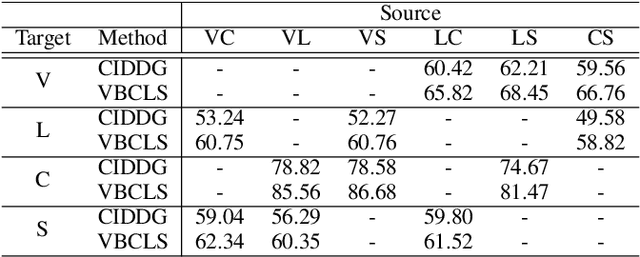
In this work, we propose a domain generalization (DG) approach to learn on several labeled source domains and transfer knowledge to a target domain that is inaccessible in training. Considering the inherent conditional and label shifts, we would expect the alignment of $p(x|y)$ and $p(y)$. However, the widely used domain invariant feature learning (IFL) methods relies on aligning the marginal concept shift w.r.t. $p(x)$, which rests on an unrealistic assumption that $p(y)$ is invariant across domains. We thereby propose a novel variational Bayesian inference framework to enforce the conditional distribution alignment w.r.t. $p(x|y)$ via the prior distribution matching in a latent space, which also takes the marginal label shift w.r.t. $p(y)$ into consideration with the posterior alignment. Extensive experiments on various benchmarks demonstrate that our framework is robust to the label shift and the cross-domain accuracy is significantly improved, thereby achieving superior performance over the conventional IFL counterparts.
Segmentation of Cardiac Structures via Successive Subspace Learning with Saab Transform from Cine MRI
Jul 22, 2021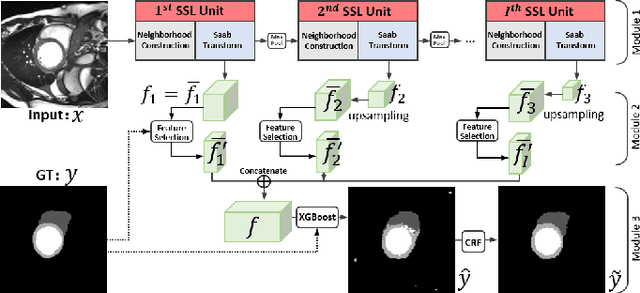

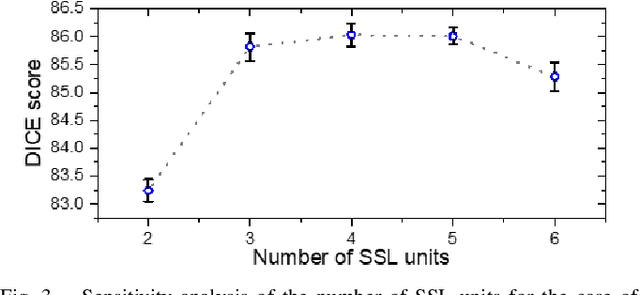

Assessment of cardiovascular disease (CVD) with cine magnetic resonance imaging (MRI) has been used to non-invasively evaluate detailed cardiac structure and function. Accurate segmentation of cardiac structures from cine MRI is a crucial step for early diagnosis and prognosis of CVD, and has been greatly improved with convolutional neural networks (CNN). There, however, are a number of limitations identified in CNN models, such as limited interpretability and high complexity, thus limiting their use in clinical practice. In this work, to address the limitations, we propose a lightweight and interpretable machine learning model, successive subspace learning with the subspace approximation with adjusted bias (Saab) transform, for accurate and efficient segmentation from cine MRI. Specifically, our segmentation framework is comprised of the following steps: (1) sequential expansion of near-to-far neighborhood at different resolutions; (2) channel-wise subspace approximation using the Saab transform for unsupervised dimension reduction; (3) class-wise entropy guided feature selection for supervised dimension reduction; (4) concatenation of features and pixel-wise classification with gradient boost; and (5) conditional random field for post-processing. Experimental results on the ACDC 2017 segmentation database, showed that our framework performed better than state-of-the-art U-Net models with 200$\times$ fewer parameters in delineating the left ventricle, right ventricle, and myocardium, thus showing its potential to be used in clinical practice.
Generative Self-training for Cross-domain Unsupervised Tagged-to-Cine MRI Synthesis
Jun 23, 2021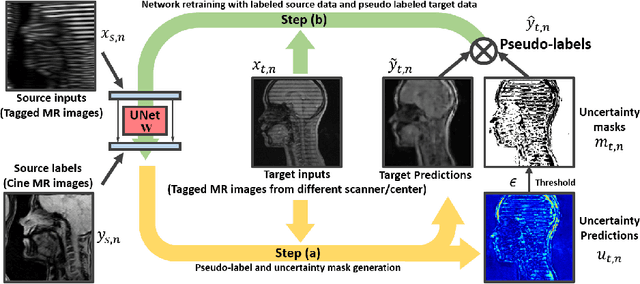
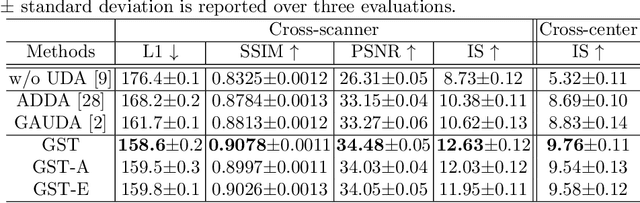
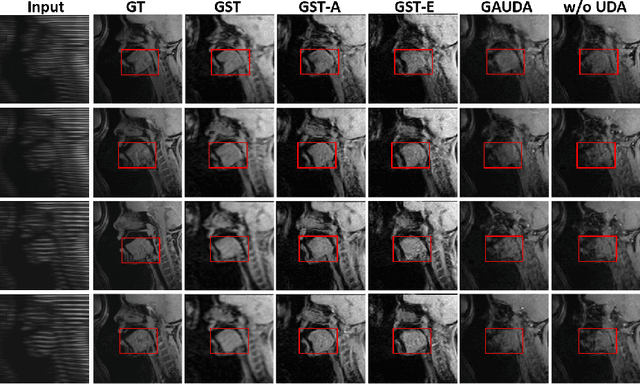
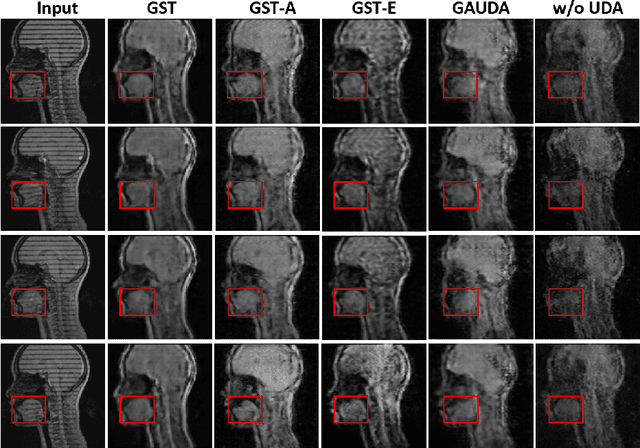
Self-training based unsupervised domain adaptation (UDA) has shown great potential to address the problem of domain shift, when applying a trained deep learning model in a source domain to unlabeled target domains. However, while the self-training UDA has demonstrated its effectiveness on discriminative tasks, such as classification and segmentation, via the reliable pseudo-label selection based on the softmax discrete histogram, the self-training UDA for generative tasks, such as image synthesis, is not fully investigated. In this work, we propose a novel generative self-training (GST) UDA framework with continuous value prediction and regression objective for cross-domain image synthesis. Specifically, we propose to filter the pseudo-label with an uncertainty mask, and quantify the predictive confidence of generated images with practical variational Bayes learning. The fast test-time adaptation is achieved by a round-based alternative optimization scheme. We validated our framework on the tagged-to-cine magnetic resonance imaging (MRI) synthesis problem, where datasets in the source and target domains were acquired from different scanners or centers. Extensive validations were carried out to verify our framework against popular adversarial training UDA methods. Results show that our GST, with tagged MRI of test subjects in new target domains, improved the synthesis quality by a large margin, compared with the adversarial training UDA methods.
Adapting Off-the-Shelf Source Segmenter for Target Medical Image Segmentation
Jun 23, 2021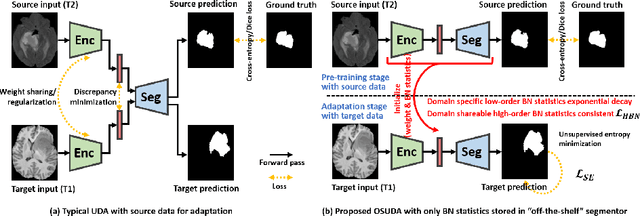
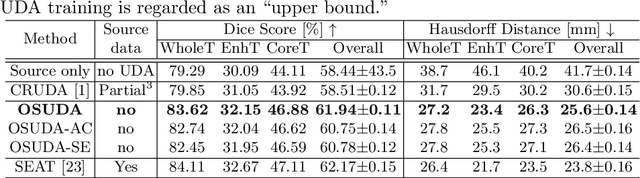
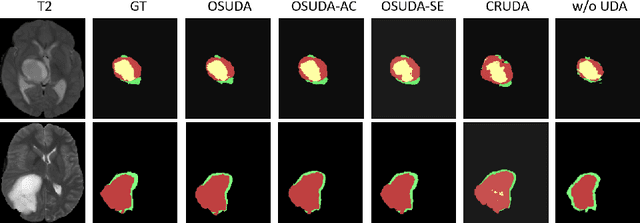
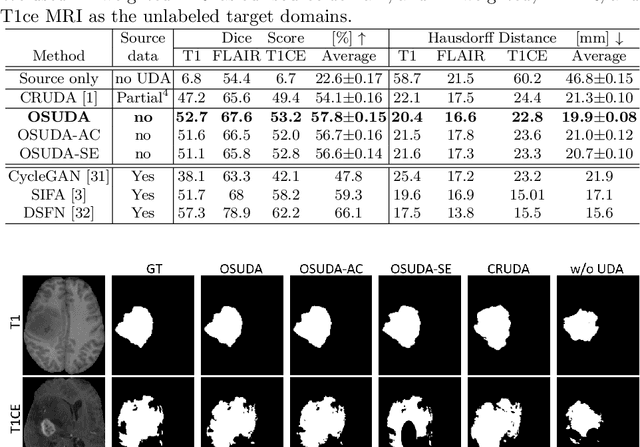
Unsupervised domain adaptation (UDA) aims to transfer knowledge learned from a labeled source domain to an unlabeled and unseen target domain, which is usually trained on data from both domains. Access to the source domain data at the adaptation stage, however, is often limited, due to data storage or privacy issues. To alleviate this, in this work, we target source free UDA for segmentation, and propose to adapt an ``off-the-shelf" segmentation model pre-trained in the source domain to the target domain, with an adaptive batch-wise normalization statistics adaptation framework. Specifically, the domain-specific low-order batch statistics, i.e., mean and variance, are gradually adapted with an exponential momentum decay scheme, while the consistency of domain shareable high-order batch statistics, i.e., scaling and shifting parameters, is explicitly enforced by our optimization objective. The transferability of each channel is adaptively measured first from which to balance the contribution of each channel. Moreover, the proposed source free UDA framework is orthogonal to unsupervised learning methods, e.g., self-entropy minimization, which can thus be simply added on top of our framework. Extensive experiments on the BraTS 2018 database show that our source free UDA framework outperformed existing source-relaxed UDA methods for the cross-subtype UDA segmentation task and yielded comparable results for the cross-modality UDA segmentation task, compared with a supervised UDA methods with the source data.