 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Binary Encoded Crime Linkage Analysis Using Siamese Network
Nov 10, 2025Effective crime linkage analysis is crucial for identifying serial offenders and enhancing public safety. To address limitations of traditional crime linkage methods in handling high-dimensional, sparse, and heterogeneous data, we propose a Siamese Autoencoder framework that learns meaningful latent representations and uncovers correlations in complex crime data. Using data from the Violent Crime Linkage Analysis System (ViCLAS), maintained by the Serious Crime Analysis Section of the UK's National Crime Agency, our approach mitigates signal dilution in sparse feature spaces by integrating geographic-temporal features at the decoder stage. This design amplifies behavioral representations rather than allowing them to be overshadowed at the input level, yielding consistent improvements across multiple evaluation metrics. We further analyze how different domain-informed data reduction strategies influence model performance, providing practical guidance for preprocessing in crime linkage contexts. Our results show that advanced machine learning approaches can substantially enhance linkage accuracy, improving AUC by up to 9% over traditional methods while offering interpretable insights to support investigative decision-making.
BAPPA: Benchmarking Agents, Plans, and Pipelines for Automated Text-to-SQL Generation
Nov 06, 2025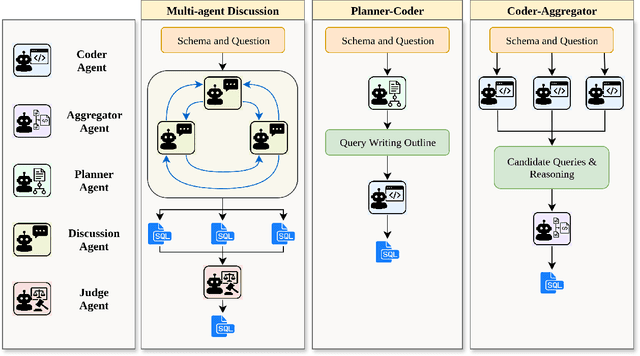
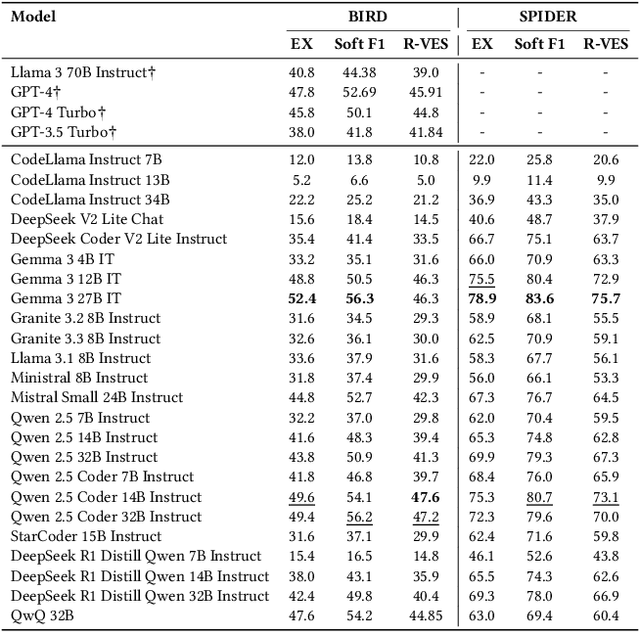
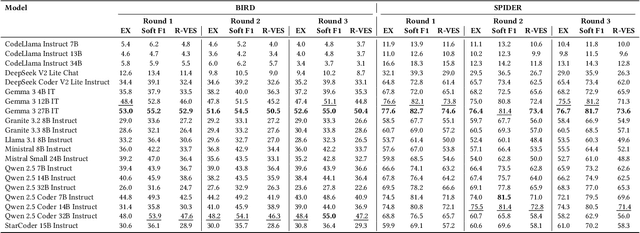

Text-to-SQL systems provide a natural language interface that can enable even laymen to access information stored in databases. However, existing Large Language Models (LLM) struggle with SQL generation from natural instructions due to large schema sizes and complex reasoning. Prior work often focuses on complex, somewhat impractical pipelines using flagship models, while smaller, efficient models remain overlooked. In this work, we explore three multi-agent LLM pipelines, with systematic performance benchmarking across a range of small to large open-source models: (1) Multi-agent discussion pipeline, where agents iteratively critique and refine SQL queries, and a judge synthesizes the final answer; (2) Planner-Coder pipeline, where a thinking model planner generates stepwise SQL generation plans and a coder synthesizes queries; and (3) Coder-Aggregator pipeline, where multiple coders independently generate SQL queries, and a reasoning agent selects the best query. Experiments on the Bird-Bench Mini-Dev set reveal that Multi-Agent discussion can improve small model performance, with up to 10.6% increase in Execution Accuracy for Qwen2.5-7b-Instruct seen after three rounds of discussion. Among the pipelines, the LLM Reasoner-Coder pipeline yields the best results, with DeepSeek-R1-32B and QwQ-32B planners boosting Gemma 3 27B IT accuracy from 52.4% to the highest score of 56.4%. Codes are available at https://github.com/treeDweller98/bappa-sql.
Hybrid Classical-Quantum Deep Learning Models for Autonomous Vehicle Traffic Image Classification Under Adversarial Attack
Aug 02, 2021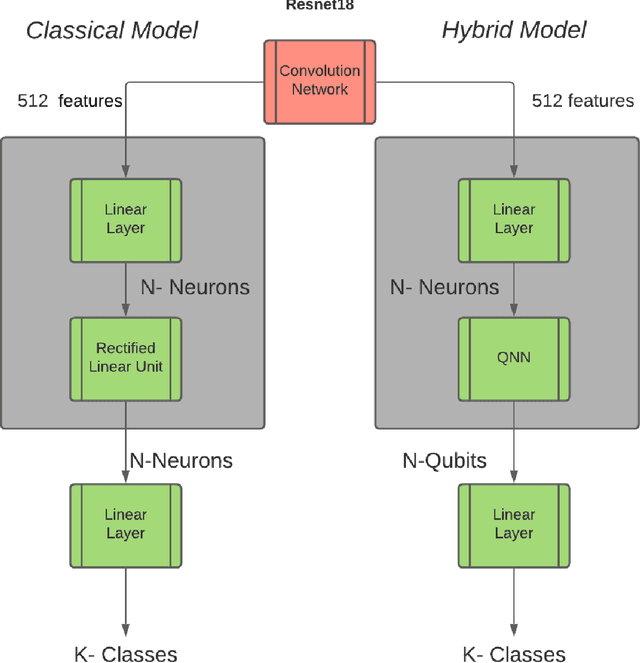
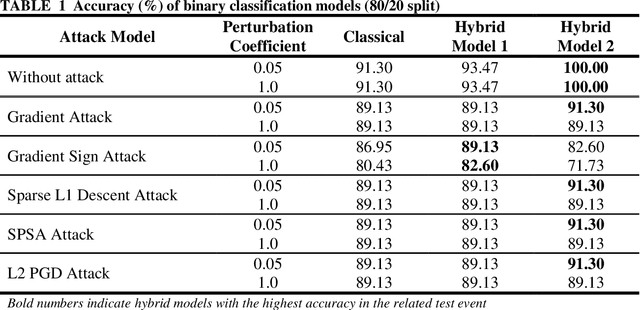
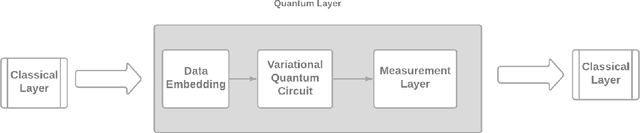
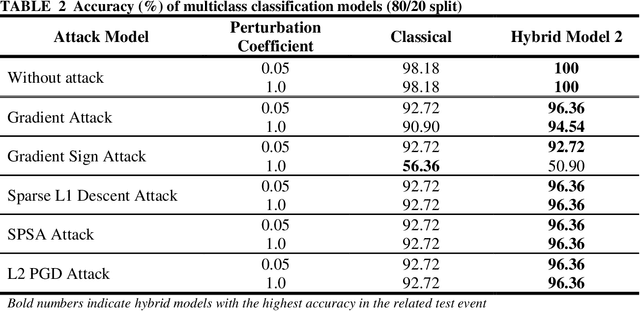
Image classification must work for autonomous vehicles (AV) operating on public roads, and actions performed based on image misclassification can have serious consequences. Traffic sign images can be misclassified by an adversarial attack on machine learning models used by AVs for traffic sign recognition. To make classification models resilient against adversarial attacks, we used a hybrid deep-learning model with both the quantum and classical layers. Our goal is to study the hybrid deep-learning architecture for classical-quantum transfer learning models to support the current era of intermediate-scale quantum technology. We have evaluated the impacts of various white box adversarial attacks on these hybrid models. The classical part of hybrid models includes a convolution network from the pre-trained Resnet18 model, which extracts informative features from a high dimensional LISA traffic sign image dataset. The output from the classical processor is processed further through the quantum layer, which is composed of various quantum gates and provides support to various quantum mechanical features like entanglement and superposition. We have tested multiple combinations of quantum circuits to provide better classification accuracy with decreasing training data and found better resiliency for our hybrid classical-quantum deep learning model during attacks compared to the classical-only machine learning models.
Accepted or Abandoned? Predicting the Fate of Code Changes
Dec 07, 2019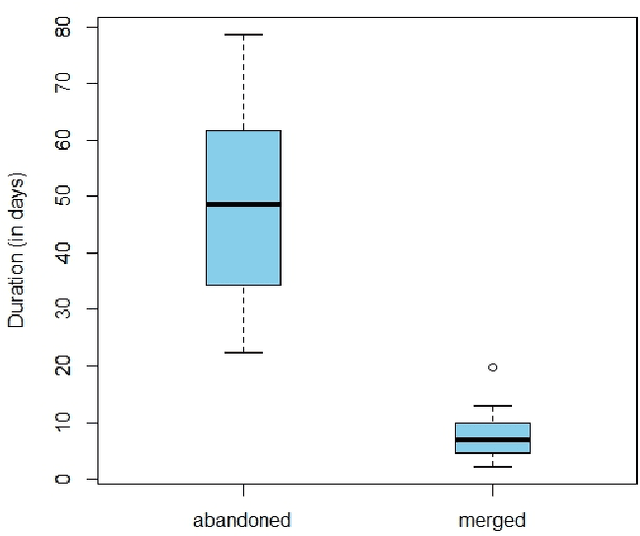
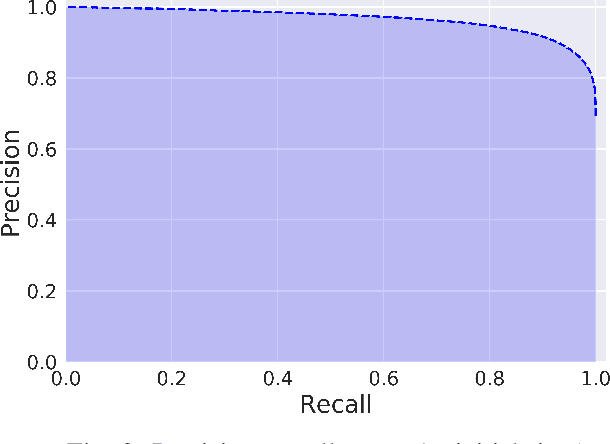
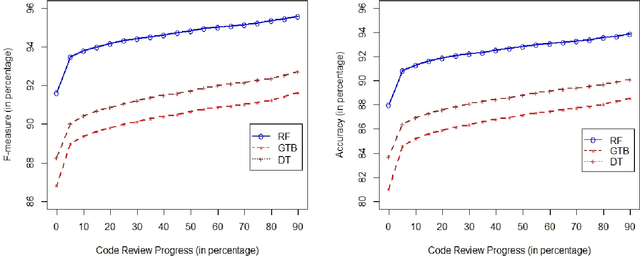
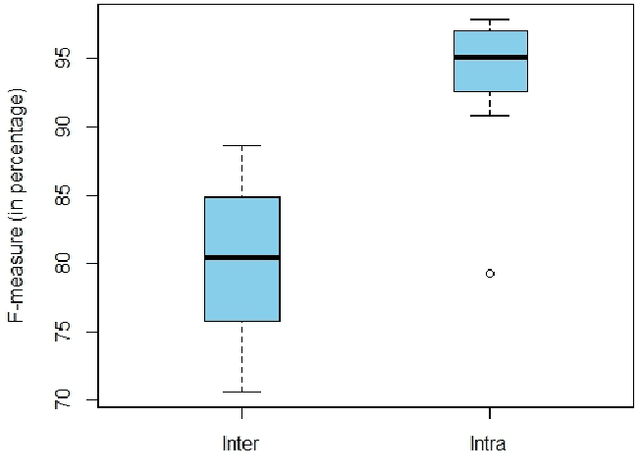
Many mature Open-Source Software (OSS), as well as commercial, organizations have adopted peer code review as an integral part of the development process to ensure the quality of the product. Of particular interest are code changes that end up "abandoned," either because they are rejected, or (more commonly) because they are never accepted at all (at least not through the review tool). Several factors such as resource allocation, job environment, and efficiency mismatch between the author and the reviewer may cause a code change to be abandoned even after months of efforts from the developers and the reviewers. Predicting the review outcome of such code changes can ease the prioritization of tasks and the utilization of limited resources by saving time spent on low-quality code changes. In this paper, we conducted a comprehensive study to predict whether a code change is merged or abandoned and applied various well-known supervised machine learning algorithms. We propose PredCR, a Random Forest based model that predicts the review outcome of a code change with 0.91 f-measure at the beginning of the code change on the test set. Also, it improves predictions of abandoned changes by 27\%-103\% and merged changes by 5\%-11\%. Our model accurately classifies 93\% of the top 25\% code changes (with average 196 days duration) that go longest without being merged. PredCR can also adapt to the changes in feature values at different stages of the review process although it achieves very high performance at the very early stage (within 10\% of the review process). This way, prediction quality for a particular code change can improve as the code review progresses. We also conducted a study to find out the properties of an ideal training set for our tool. We found that training with the instances from the same projects ensures 9\%-25\% performance increase.