 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaneRoPE: Positional Encoding for Collaborative Parallel Reasoning and Generation
May 26, 2026Parallel LLM test-time scaling techniques (e.g., best-of-$N$) require drawing $N>1$ sequences conditioned on the same input prompt. These methods boost accuracy while exploiting the computational efficiency of batching $N$ generations. However, each sequence in the batch is traditionally generated independently and hence does not reuse intermediate generations, computations, or observations from other sequences. In this paper, we propose LaneRoPE to enable coordination and collaboration among $N>1$ sequences at generation time. LaneRoPE involves two key ideas: (a) an inter-sequence attention mask to make sampling of sequences dependent on one another; and (b) a RoPE extension that injects positional information that captures relative positions between tokens, both within and outside a particular sequence. We evaluate our approach on mathematical reasoning tasks and find promising results: LaneRoPE enables collaboration among sequences, yielding additional accuracy gains under limited generated sequence length. Importantly, since LaneRoPE enables coordination with minimal changes to the underlying LLM architecture and introduces a negligible overhead at inference time, it is appealing to rapidly incorporate parallel reasoning into existing LLM inference pipelines.
Efficient Reasoning on the Edge
Mar 17, 2026Large language models (LLMs) with chain-of-thought reasoning achieve state-of-the-art performance across complex problem-solving tasks, but their verbose reasoning traces and large context requirements make them impractical for edge deployment. These challenges include high token generation costs, large KV-cache footprints, and inefficiencies when distilling reasoning capabilities into smaller models for mobile devices. Existing approaches often rely on distilling reasoning traces from larger models into smaller models, which are verbose and stylistically redundant, undesirable for on-device inference. In this work, we propose a lightweight approach to enable reasoning in small LLMs using LoRA adapters combined with supervised fine-tuning. We further introduce budget forcing via reinforcement learning on these adapters, significantly reducing response length with minimal accuracy loss. To address memory-bound decoding, we exploit parallel test-time scaling, improving accuracy at minor latency increase. Finally, we present a dynamic adapter-switching mechanism that activates reasoning only when needed and a KV-cache sharing strategy during prompt encoding, reducing time-to-first-token for on-device inference. Experiments on Qwen2.5-7B demonstrate that our method achieves efficient, accurate reasoning under strict resource constraints, making LLM reasoning practical for mobile scenarios. Videos demonstrating our solution running on mobile devices are available on our project page.
LUMINA: Long-horizon Understanding for Multi-turn Interactive Agents
Jan 23, 2026Large language models can perform well on many isolated tasks, yet they continue to struggle on multi-turn, long-horizon agentic problems that require skills such as planning, state tracking, and long context processing. In this work, we aim to better understand the relative importance of advancing these underlying capabilities for success on such tasks. We develop an oracle counterfactual framework for multi-turn problems that asks: how would an agent perform if it could leverage an oracle to perfectly perform a specific task? The change in the agent's performance due to this oracle assistance allows us to measure the criticality of such oracle skill in the future advancement of AI agents. We introduce a suite of procedurally generated, game-like tasks with tunable complexity. These controlled environments allow us to provide precise oracle interventions, such as perfect planning or flawless state tracking, and make it possible to isolate the contribution of each oracle without confounding effects present in real-world benchmarks. Our results show that while some interventions (e.g., planning) consistently improve performance across settings, the usefulness of other skills is dependent on the properties of the environment and language model. Our work sheds light on the challenges of multi-turn agentic environments to guide the future efforts in the development of AI agents and language models.
Probabilistic and Differentiable Wireless Simulation with Geometric Transformers
Jun 21, 2024



Modelling the propagation of electromagnetic signals is critical for designing modern communication systems. While there are precise simulators based on ray tracing, they do not lend themselves to solving inverse problems or the integration in an automated design loop. We propose to address these challenges through differentiable neural surrogates that exploit the geometric aspects of the problem. We first introduce the Wireless Geometric Algebra Transformer (Wi-GATr), a generic backbone architecture for simulating wireless propagation in a 3D environment. It uses versatile representations based on geometric algebra and is equivariant with respect to E(3), the symmetry group of the underlying physics. Second, we study two algorithmic approaches to signal prediction and inverse problems based on differentiable predictive modelling and diffusion models. We show how these let us predict received power, localize receivers, and reconstruct the 3D environment from the received signal. Finally, we introduce two large, geometry-focused datasets of wireless signal propagation in indoor scenes. In experiments, we show that our geometry-forward approach achieves higher-fidelity predictions with less data than various baselines.
Simulating, Fast and Slow: Learning Policies for Black-Box Optimization
Jun 06, 2024



In recent years, solving optimization problems involving black-box simulators has become a point of focus for the machine learning community due to their ubiquity in science and engineering. The simulators describe a forward process $f_{\mathrm{sim}}: (\psi, x) \rightarrow y$ from simulation parameters $\psi$ and input data $x$ to observations $y$, and the goal of the optimization problem is to find parameters $\psi$ that minimize a desired loss function. Sophisticated optimization algorithms typically require gradient information regarding the forward process, $f_{\mathrm{sim}}$, with respect to the parameters $\psi$. However, obtaining gradients from black-box simulators can often be prohibitively expensive or, in some cases, impossible. Furthermore, in many applications, practitioners aim to solve a set of related problems. Thus, starting the optimization ``ab initio", i.e. from scratch, each time might be inefficient if the forward model is expensive to evaluate. To address those challenges, this paper introduces a novel method for solving classes of similar black-box optimization problems by learning an active learning policy that guides a differentiable surrogate's training and uses the surrogate's gradients to optimize the simulation parameters with gradient descent. After training the policy, downstream optimization of problems involving black-box simulators requires up to $\sim$90\% fewer expensive simulator calls compared to baselines such as local surrogate-based approaches, numerical optimization, and Bayesian methods.
End-to-end Learning of Deterministic Decision Trees
Dec 07, 2017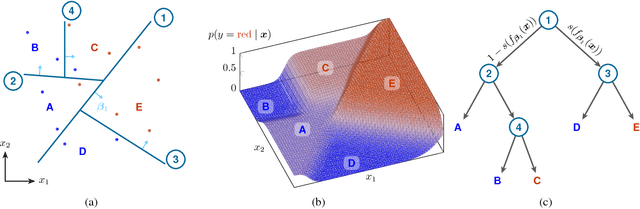
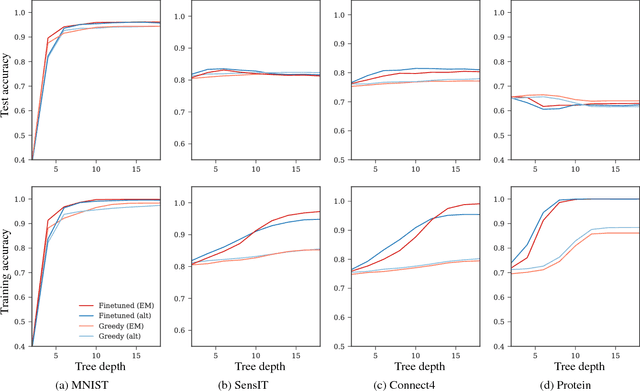
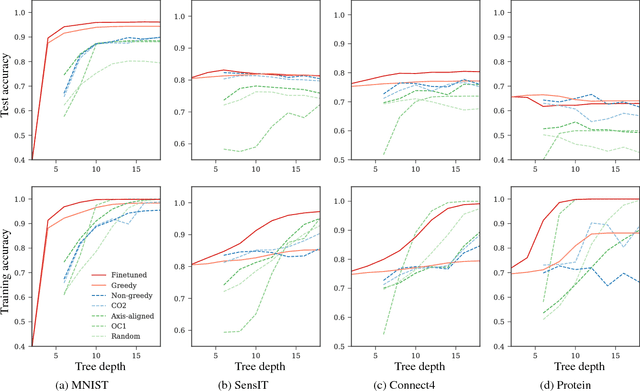

Conventional decision trees have a number of favorable properties, including interpretability, a small computational footprint and the ability to learn from little training data. However, they lack a key quality that has helped fuel the deep learning revolution: that of being end-to-end trainable, and to learn from scratch those features that best allow to solve a given supervised learning problem. Recent work (Kontschieder 2015) has addressed this deficit, but at the cost of losing a main attractive trait of decision trees: the fact that each sample is routed along a small subset of tree nodes only. We here propose a model and Expectation-Maximization training scheme for decision trees that are fully probabilistic at train time, but after a deterministic annealing process become deterministic at test time. We also analyze the learned oblique split parameters on image datasets and show that Neural Networks can be trained at each split node. In summary, we present the first end-to-end learning scheme for deterministic decision trees and present results on par with or superior to published standard oblique decision tree algorithms.