 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep evolving semi-supervised anomaly detection
Dec 01, 2024The aim of this paper is to formalise the task of continual semi-supervised anomaly detection (CSAD), with the aim of highlighting the importance of such a problem formulation which assumes as close to real-world conditions as possible. After an overview of the relevant definitions of continual semi-supervised learning, its components, anomaly detection extension, and the training protocols; the paper introduces a baseline model of a variational autoencoder (VAE) to work with semi-supervised data along with a continual learning method of deep generative replay with outlier rejection. The results show that such a use of extreme value theory (EVT) applied to anomaly detection can provide promising results even in comparison to an upper baseline of joint training. The results explore the effects of how much labelled and unlabelled data is present, of which class, and where it is located in the data stream. Outlier rejection shows promising initial results where it often surpasses a baseline method of Elastic Weight Consolidation (EWC). A baseline for CSAD is put forward along with the specific dataset setups used for reproducability and testability for other practitioners. Future research directions include other CSAD settings and further research into efficient continual hyperparameter tuning.
ROAD-Waymo: Action Awareness at Scale for Autonomous Driving
Nov 03, 2024



Autonomous Vehicle (AV) perception systems require more than simply seeing, via e.g., object detection or scene segmentation. They need a holistic understanding of what is happening within the scene for safe interaction with other road users. Few datasets exist for the purpose of developing and training algorithms to comprehend the actions of other road users. This paper presents ROAD-Waymo, an extensive dataset for the development and benchmarking of techniques for agent, action, location and event detection in road scenes, provided as a layer upon the (US) Waymo Open dataset. Considerably larger and more challenging than any existing dataset (and encompassing multiple cities), it comes with 198k annotated video frames, 54k agent tubes, 3.9M bounding boxes and a total of 12.4M labels. The integrity of the dataset has been confirmed and enhanced via a novel annotation pipeline designed for automatically identifying violations of requirements specifically designed for this dataset. As ROAD-Waymo is compatible with the original (UK) ROAD dataset, it provides the opportunity to tackle domain adaptation between real-world road scenarios in different countries within a novel benchmark: ROAD++.
Credal Wrapper of Model Averaging for Uncertainty Estimation on Out-Of-Distribution Detection
May 23, 2024



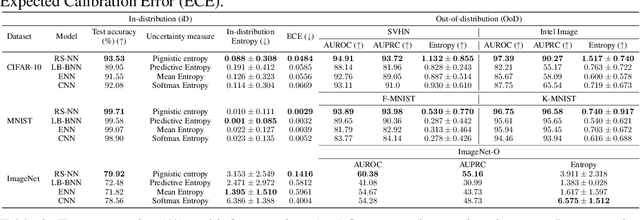
This paper presents an innovative approach, called credal wrapper, to formulating a credal set representation of model averaging for Bayesian neural networks (BNNs) and deep ensembles, capable of improving uncertainty estimation in classification tasks. Given a finite collection of single distributions derived from BNNs or deep ensembles, the proposed approach extracts an upper and a lower probability bound per class, acknowledging the epistemic uncertainty due to the availability of a limited amount of sampled predictive distributions. Such probability intervals over classes can be mapped on a convex set of probabilities (a 'credal set') from which, in turn, a unique prediction can be obtained using a transformation called 'intersection probability transformation'. In this article, we conduct extensive experiments on multiple out-of-distribution (OOD) detection benchmarks, encompassing various dataset pairs (CIFAR10/100 vs SVHN/Tiny-ImageNet, CIFAR10 vs CIFAR10-C, CIFAR100 vs CIFAR100-C and ImageNet vs ImageNet-O) and using different network architectures (such as VGG16, Res18/50, EfficientNet B2, and ViT Base). Compared to BNN and deep ensemble baselines, the proposed credal representation methodology exhibits superior performance in uncertainty estimation and achieves lower expected calibration error on OOD samples.
Feature boosting with efficient attention for scene parsing
Feb 29, 2024The complexity of scene parsing grows with the number of object and scene classes, which is higher in unrestricted open scenes. The biggest challenge is to model the spatial relation between scene elements while succeeding in identifying objects at smaller scales. This paper presents a novel feature-boosting network that gathers spatial context from multiple levels of feature extraction and computes the attention weights for each level of representation to generate the final class labels. A novel `channel attention module' is designed to compute the attention weights, ensuring that features from the relevant extraction stages are boosted while the others are attenuated. The model also learns spatial context information at low resolution to preserve the abstract spatial relationships among scene elements and reduce computation cost. Spatial attention is subsequently concatenated into a final feature set before applying feature boosting. Low-resolution spatial attention features are trained using an auxiliary task that helps learning a coarse global scene structure. The proposed model outperforms all state-of-the-art models on both the ADE20K and the Cityscapes datasets.
Generalising realisability in statistical learning theory under epistemic uncertainty
Feb 22, 2024The purpose of this paper is to look into how central notions in statistical learning theory, such as realisability, generalise under the assumption that train and test distribution are issued from the same credal set, i.e., a convex set of probability distributions. This can be considered as a first step towards a more general treatment of statistical learning under epistemic uncertainty.
Credal Learning Theory
Feb 01, 2024
Statistical learning theory is the foundation of machine learning, providing theoretical bounds for the risk of models learnt from a (single) training set, assumed to issue from an unknown probability distribution. In actual deployment, however, the data distribution may (and often does) vary, causing domain adaptation/generalization issues. In this paper we lay the foundations for a `credal' theory of learning, using convex sets of probabilities (credal sets) to model the variability in the data-generating distribution. Such credal sets, we argue, may be inferred from a finite sample of training sets. Bounds are derived for the case of finite hypotheses spaces (both assuming realizability or not) as well as infinite model spaces, which directly generalize classical results.
CreINNs: Credal-Set Interval Neural Networks for Uncertainty Estimation in Classification Tasks
Jan 10, 2024
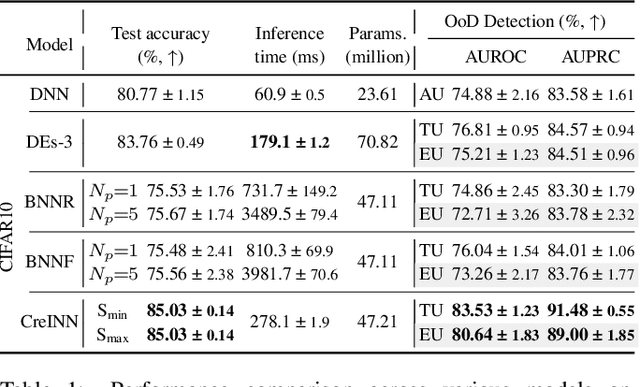
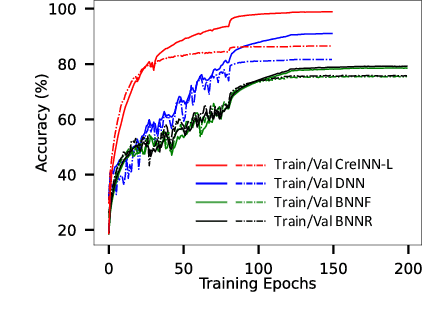
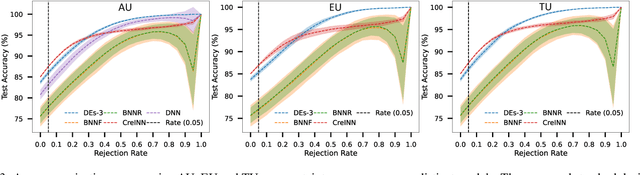
Uncertainty estimation is increasingly attractive for improving the reliability of neural networks. In this work, we present novel credal-set interval neural networks (CreINNs) designed for classification tasks. CreINNs preserve the traditional interval neural network structure, capturing weight uncertainty through deterministic intervals, while forecasting credal sets using the mathematical framework of probability intervals. Experimental validations on an out-of-distribution detection benchmark (CIFAR10 vs SVHN) showcase that CreINNs outperform epistemic uncertainty estimation when compared to variational Bayesian neural networks (BNNs) and deep ensembles (DEs). Furthermore, CreINNs exhibit a notable reduction in computational complexity compared to variational BNNs and demonstrate smaller model sizes than DEs.
A Hybrid Graph Network for Complex Activity Detection in Video
Oct 30, 2023Interpretation and understanding of video presents a challenging computer vision task in numerous fields - e.g. autonomous driving and sports analytics. Existing approaches to interpreting the actions taking place within a video clip are based upon Temporal Action Localisation (TAL), which typically identifies short-term actions. The emerging field of Complex Activity Detection (CompAD) extends this analysis to long-term activities, with a deeper understanding obtained by modelling the internal structure of a complex activity taking place within the video. We address the CompAD problem using a hybrid graph neural network which combines attention applied to a graph encoding the local (short-term) dynamic scene with a temporal graph modelling the overall long-duration activity. Our approach is as follows: i) Firstly, we propose a novel feature extraction technique which, for each video snippet, generates spatiotemporal `tubes' for the active elements (`agents') in the (local) scene by detecting individual objects, tracking them and then extracting 3D features from all the agent tubes as well as the overall scene. ii) Next, we construct a local scene graph where each node (representing either an agent tube or the scene) is connected to all other nodes. Attention is then applied to this graph to obtain an overall representation of the local dynamic scene. iii) Finally, all local scene graph representations are interconnected via a temporal graph, to estimate the complex activity class together with its start and end time. The proposed framework outperforms all previous state-of-the-art methods on all three datasets including ActivityNet-1.3, Thumos-14, and ROAD.
Temporal DINO: A Self-supervised Video Strategy to Enhance Action Prediction
Aug 20, 2023The emerging field of action prediction plays a vital role in various computer vision applications such as autonomous driving, activity analysis and human-computer interaction. Despite significant advancements, accurately predicting future actions remains a challenging problem due to high dimensionality, complex dynamics and uncertainties inherent in video data. Traditional supervised approaches require large amounts of labelled data, which is expensive and time-consuming to obtain. This paper introduces a novel self-supervised video strategy for enhancing action prediction inspired by DINO (self-distillation with no labels). The Temporal-DINO approach employs two models; a 'student' processing past frames; and a 'teacher' processing both past and future frames, enabling a broader temporal context. During training, the teacher guides the student to learn future context by only observing past frames. The strategy is evaluated on ROAD dataset for the action prediction downstream task using 3D-ResNet, Transformer, and LSTM architectures. The experimental results showcase significant improvements in prediction performance across these architectures, with our method achieving an average enhancement of 9.9% Precision Points (PP), highlighting its effectiveness in enhancing the backbones' capabilities of capturing long-term dependencies. Furthermore, our approach demonstrates efficiency regarding the pretraining dataset size and the number of epochs required. This method overcomes limitations present in other approaches, including considering various backbone architectures, addressing multiple prediction horizons, reducing reliance on hand-crafted augmentations, and streamlining the pretraining process into a single stage. These findings highlight the potential of our approach in diverse video-based tasks such as activity recognition, motion planning, and scene understanding.
Random-Set Convolutional Neural Network (RS-CNN) for Epistemic Deep Learning
Jul 11, 2023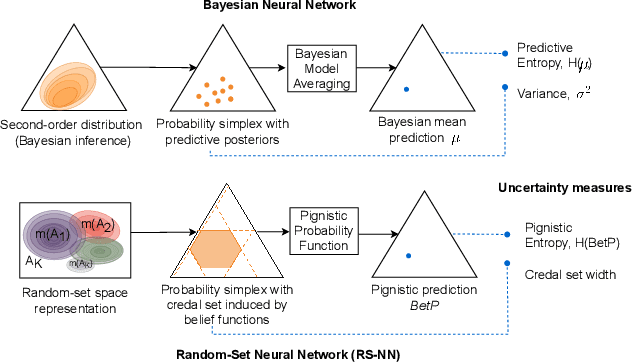
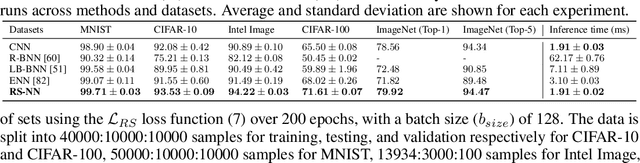
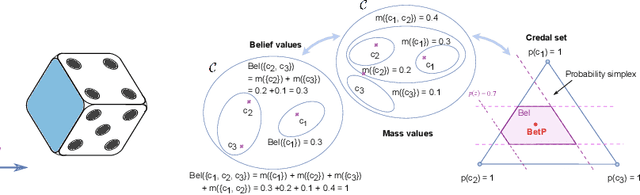
Machine learning is increasingly deployed in safety-critical domains where robustness against adversarial attacks is crucial and erroneous predictions could lead to potentially catastrophic consequences. This highlights the need for learning systems to be equipped with the means to determine a model's confidence in its prediction and the epistemic uncertainty associated with it, 'to know when a model does not know'. In this paper, we propose a novel Random-Set Convolutional Neural Network (RS-CNN) for classification which predicts belief functions rather than probability vectors over the set of classes, using the mathematics of random sets, i.e., distributions over the power set of the sample space. Based on the epistemic deep learning approach, random-set models are capable of representing the 'epistemic' uncertainty induced in machine learning by limited training sets. We estimate epistemic uncertainty by approximating the size of credal sets associated with the predicted belief functions, and experimentally demonstrate how our approach outperforms competing uncertainty-aware approaches in a classical evaluation setting. The performance of RS-CNN is best demonstrated on OOD samples where it manages to capture the true prediction while standard CNNs fail.