 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning for Video Compression with Recurrent Auto-Encoder and Recurrent Probability Model
Jun 29, 2020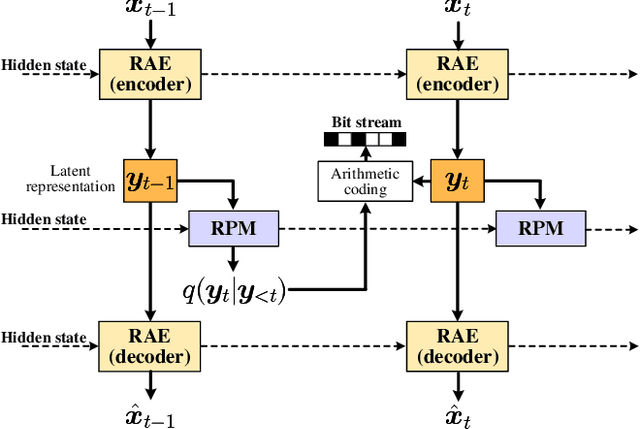
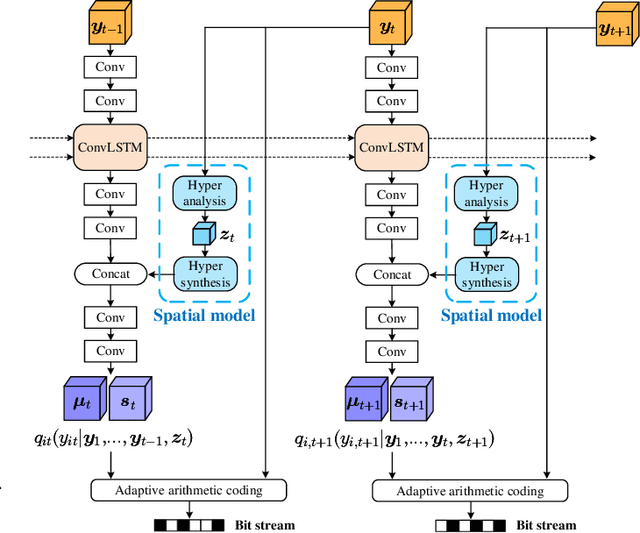
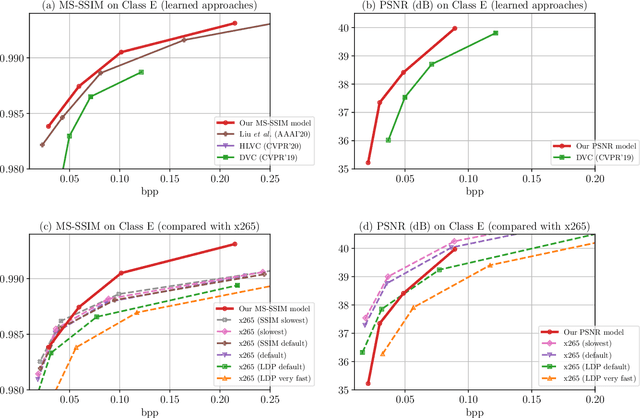
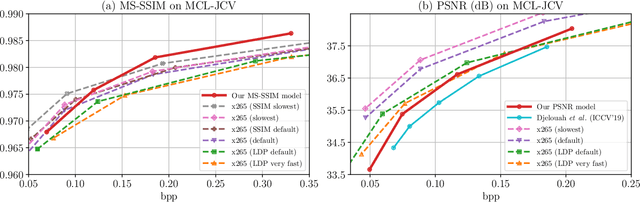
The past few years have witnessed increasing interests in applying deep learning to video compression. However, the existing approaches compress a video frame with only a few number of reference frames, which limits their ability to fully exploit the temporal correlation among video frames. To overcome this shortcoming, this paper proposes a Recurrent Learned Video Compression (RLVC) approach with the Recurrent Auto-Encoder (RAE) and Recurrent Probability Model (RPM). Specifically, the RAE employs recurrent cells in both the encoder and decoder. As such, the temporal information in a large range of frames can be used for generating latent representations and reconstructing compressed outputs. Furthermore, the proposed RPM network recurrently estimates the Probability Mass Function (PMF) of the latent representation, conditioned on the distribution of previous latent representations. Due to the correlation among consecutive frames, the conditional cross entropy can be lower than the independent cross entropy, thus reducing the bit-rate. The experiments show that our approach achieves the state-of-the-art learned video compression performance in terms of both PSNR and MS-SSIM. Moreover, our approach outperforms the default Low-Delay P (LDP) setting of x265 on PSNR, and also has better performance on MS-SSIM than the SSIM-tuned x265 and the slowest setting of x265.
Learning for Video Compression with Hierarchical Quality and Recurrent Enhancement
Apr 08, 2020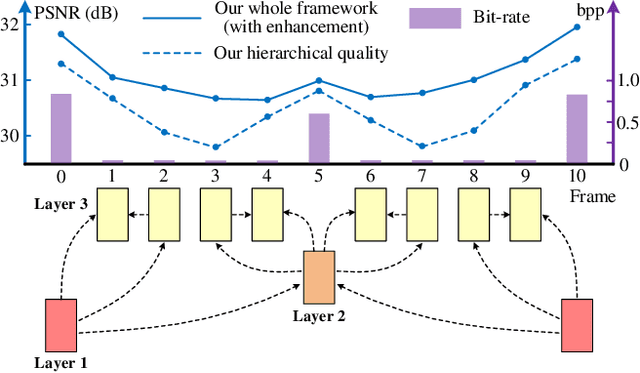
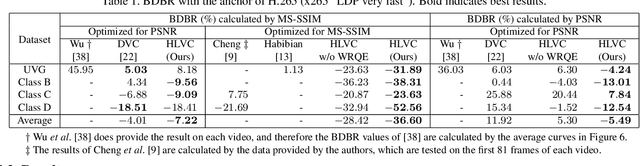
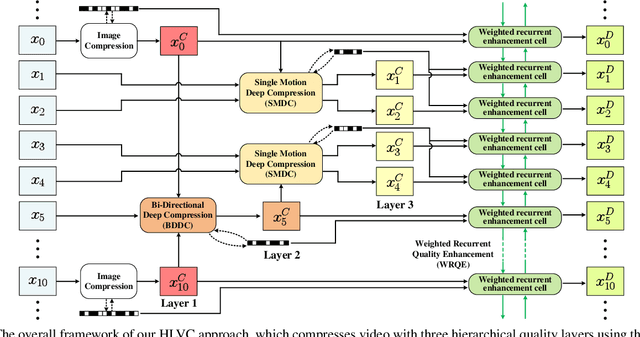
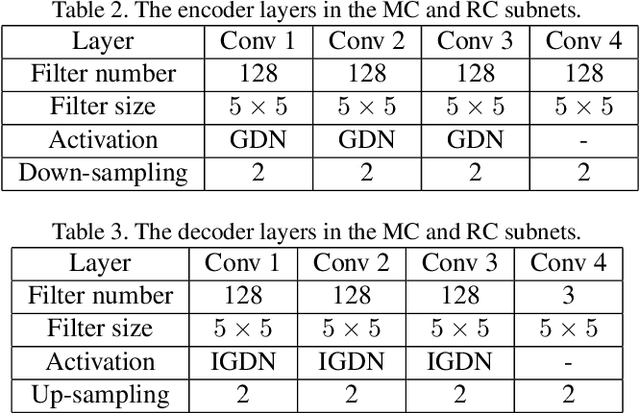
In this paper, we propose a Hierarchical Learned Video Compression (HLVC) method with three hierarchical quality layers and a recurrent enhancement network. The frames in the first layer are compressed by an image compression method with the highest quality. Using these frames as references, we propose the Bi-Directional Deep Compression (BDDC) network to compress the second layer with relatively high quality. Then, the third layer frames are compressed with the lowest quality, by the proposed Single Motion Deep Compression (SMDC) network, which adopts a single motion map to estimate the motions of multiple frames, thus saving bits for motion information. In our deep decoder, we develop the Weighted Recurrent Quality Enhancement (WRQE) network, which takes both compressed frames and the bit stream as inputs. In the recurrent cell of WRQE, the memory and update signal are weighted by quality features to reasonably leverage multi-frame information for enhancement. In our HLVC approach, the hierarchical quality benefits the coding efficiency, since the high quality information facilitates the compression and enhancement of low quality frames at encoder and decoder sides, respectively. Finally, the experiments validate that our HLVC approach advances the state-of-the-art of deep video compression methods, and outperforms the "Low-Delay P (LDP) very fast" mode of x265 in terms of both PSNR and MS-SSIM. The project page is at https://github.com/RenYang-home/HLVC.
Learning Better Lossless Compression Using Lossy Compression
Mar 23, 2020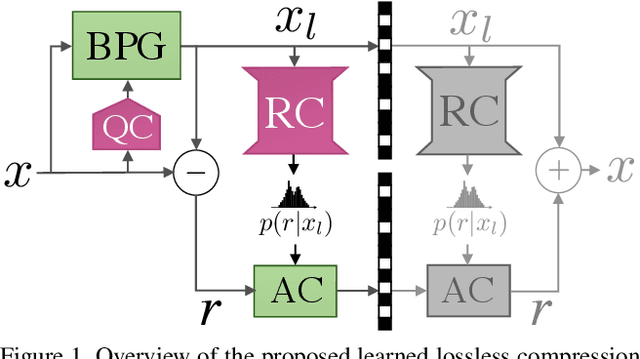
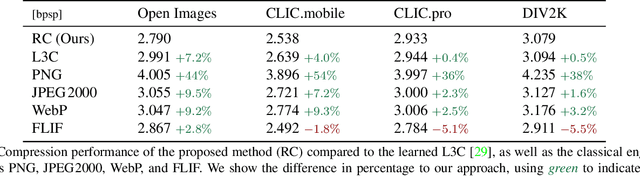
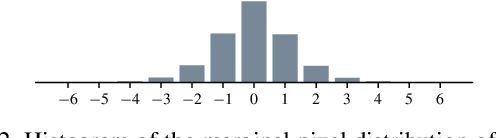
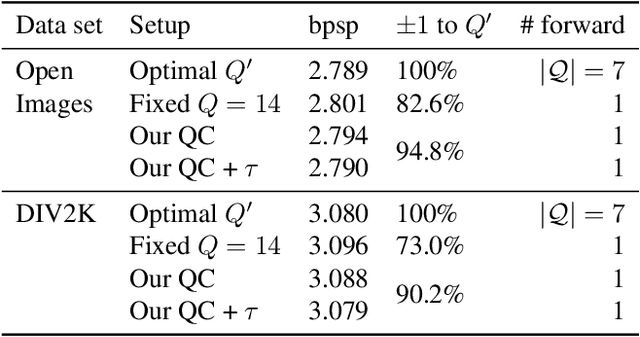
We leverage the powerful lossy image compression algorithm BPG to build a lossless image compression system. Specifically, the original image is first decomposed into the lossy reconstruction obtained after compressing it with BPG and the corresponding residual. We then model the distribution of the residual with a convolutional neural network-based probabilistic model that is conditioned on the BPG reconstruction, and combine it with entropy coding to losslessly encode the residual. Finally, the image is stored using the concatenation of the bitstreams produced by BPG and the learned residual coder. The resulting compression system achieves state-of-the-art performance in learned lossless full-resolution image compression, outperforming previous learned approaches as well as PNG, WebP, and JPEG2000.
Practical Full Resolution Learned Lossless Image Compression
Nov 30, 2018
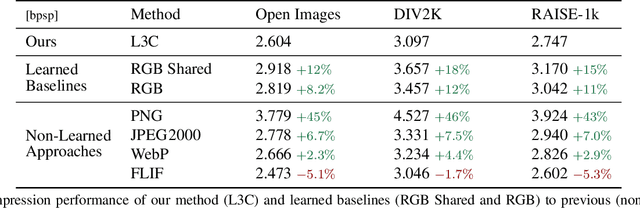
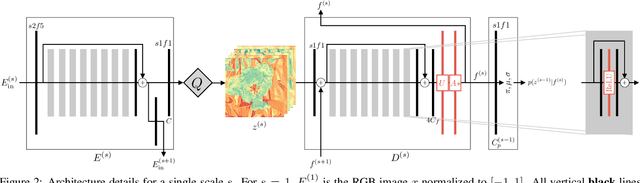
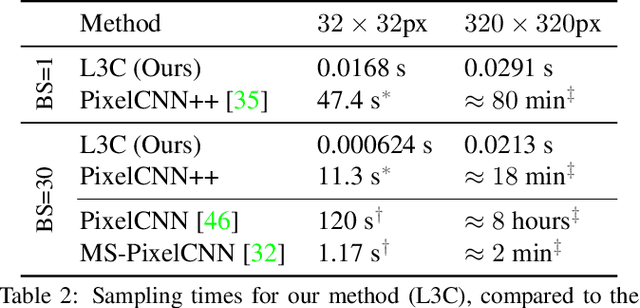
We propose the first practical learned lossless image compression system, L3C, and show that it outperforms the popular engineered codecs, PNG, WebP and JPEG2000. At the core of our method is a fully parallelizable hierarchical probabilistic model for adaptive entropy coding which is optimized end-to-end for the compression task. In contrast to recent autoregressive discrete probabilistic models such as PixelCNN, our method i) models the image distribution jointly with learned auxiliary representations instead of exclusively modeling the image distribution in RGB space, and ii) only requires three forward-passes to predict all pixel probabilities instead of one for each pixel. As a result, L3C obtains over three orders of magnitude speedups compared to the fastest PixelCNN variant (Multiscale-PixelCNN). Furthermore, we find that learning the auxiliary representation is crucial and outperforms predefined auxiliary representations such as an RGB pyramid significantly.
Generative Adversarial Networks for Extreme Learned Image Compression
Oct 23, 2018
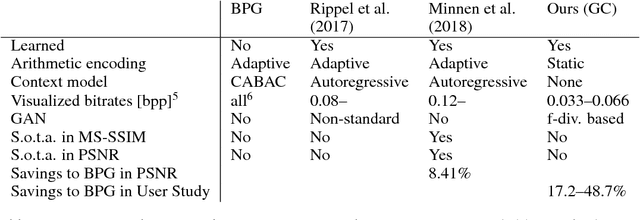


We propose a framework for extreme learned image compression based on Generative Adversarial Networks (GANs), obtaining visually pleasing images at significantly lower bitrates than previous methods. This is made possible through our GAN formulation of learned compression combined with a generator/decoder which operates on the full-resolution image and is trained in combination with a multi-scale discriminator. Additionally, if a semantic label map of the original image is available, our method can fully synthesize unimportant regions in the decoded image such as streets and trees from the label map, therefore only requiring the storage of the preserved region and the semantic label map. A user study confirms that for low bitrates, our approach is preferred to state-of-the-art methods, even when they use more than double the bits.
Conditional Probability Models for Deep Image Compression
Jun 04, 2018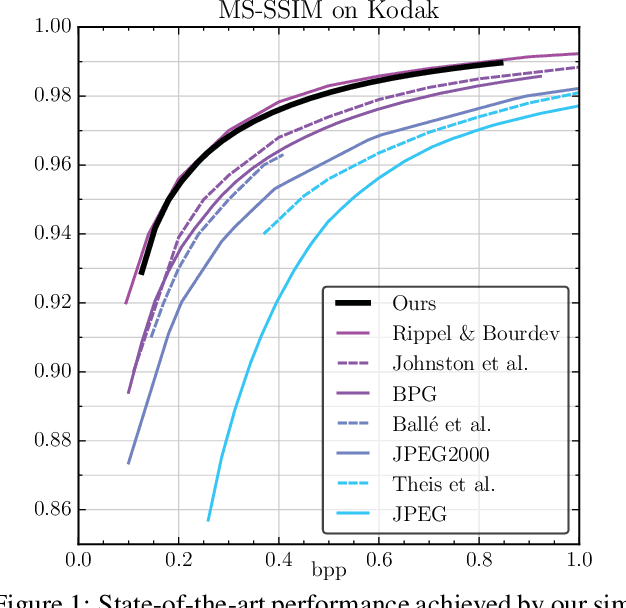
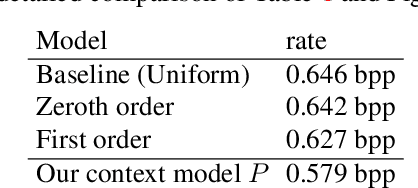
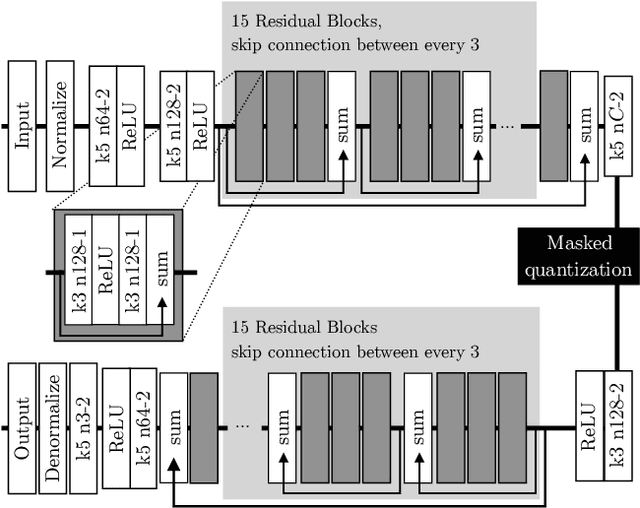
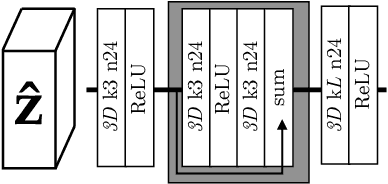
Deep Neural Networks trained as image auto-encoders have recently emerged as a promising direction for advancing the state-of-the-art in image compression. The key challenge in learning such networks is twofold: To deal with quantization, and to control the trade-off between reconstruction error (distortion) and entropy (rate) of the latent image representation. In this paper, we focus on the latter challenge and propose a new technique to navigate the rate-distortion trade-off for an image compression auto-encoder. The main idea is to directly model the entropy of the latent representation by using a context model: A 3D-CNN which learns a conditional probability model of the latent distribution of the auto-encoder. During training, the auto-encoder makes use of the context model to estimate the entropy of its representation, and the context model is concurrently updated to learn the dependencies between the symbols in the latent representation. Our experiments show that this approach, when measured in MS-SSIM, yields a state-of-the-art image compression system based on a simple convolutional auto-encoder.
Towards Image Understanding from Deep Compression without Decoding
Mar 16, 2018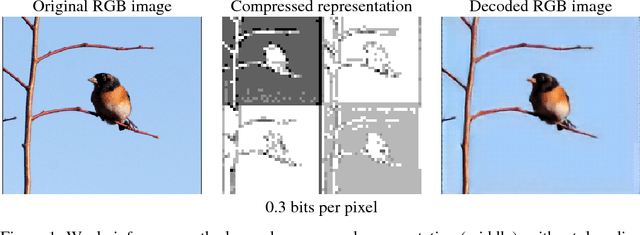
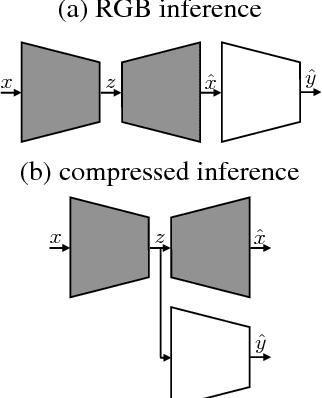
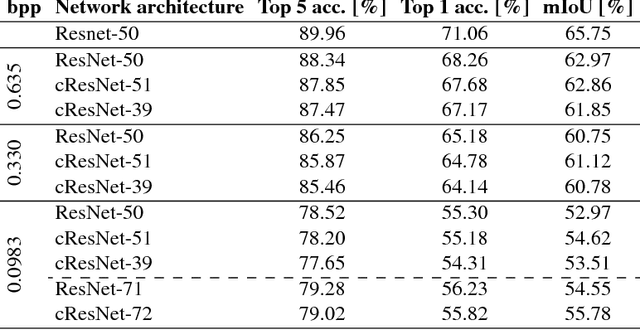
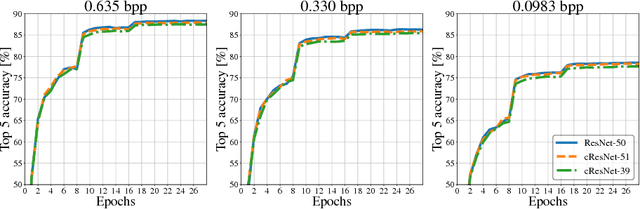
Motivated by recent work on deep neural network (DNN)-based image compression methods showing potential improvements in image quality, savings in storage, and bandwidth reduction, we propose to perform image understanding tasks such as classification and segmentation directly on the compressed representations produced by these compression methods. Since the encoders and decoders in DNN-based compression methods are neural networks with feature-maps as internal representations of the images, we directly integrate these with architectures for image understanding. This bypasses decoding of the compressed representation into RGB space and reduces computational cost. Our study shows that accuracies comparable to networks that operate on compressed RGB images can be achieved while reducing the computational complexity up to $2\times$. Furthermore, we show that synergies are obtained by jointly training compression networks with classification networks on the compressed representations, improving image quality, classification accuracy, and segmentation performance. We find that inference from compressed representations is particularly advantageous compared to inference from compressed RGB images for aggressive compression rates.
Deep Structured Features for Semantic Segmentation
Jun 16, 2017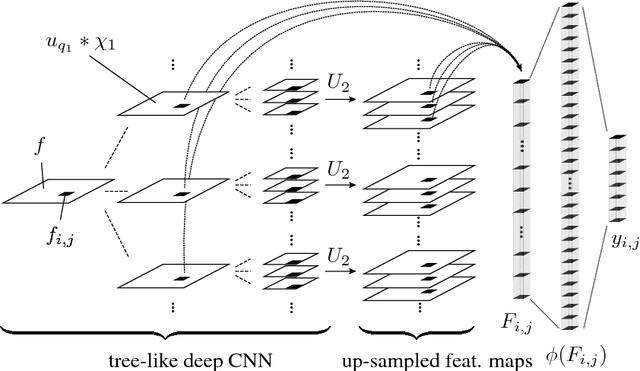
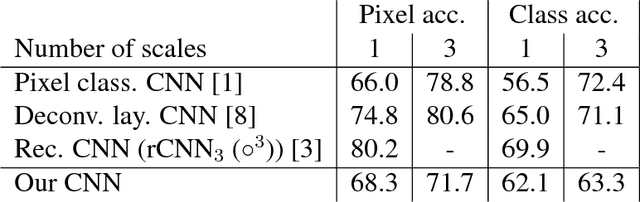

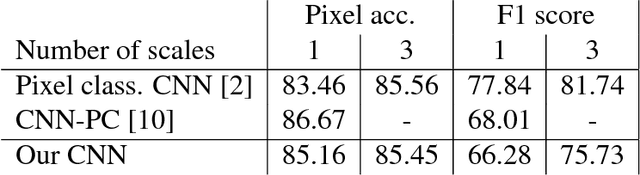
We propose a highly structured neural network architecture for semantic segmentation with an extremely small model size, suitable for low-power embedded and mobile platforms. Specifically, our architecture combines i) a Haar wavelet-based tree-like convolutional neural network (CNN), ii) a random layer realizing a radial basis function kernel approximation, and iii) a linear classifier. While stages i) and ii) are completely pre-specified, only the linear classifier is learned from data. We apply the proposed architecture to outdoor scene and aerial image semantic segmentation and show that the accuracy of our architecture is competitive with conventional pixel classification CNNs. Furthermore, we demonstrate that the proposed architecture is data efficient in the sense of matching the accuracy of pixel classification CNNs when trained on a much smaller data set.
Soft-to-Hard Vector Quantization for End-to-End Learning Compressible Representations
Jun 08, 2017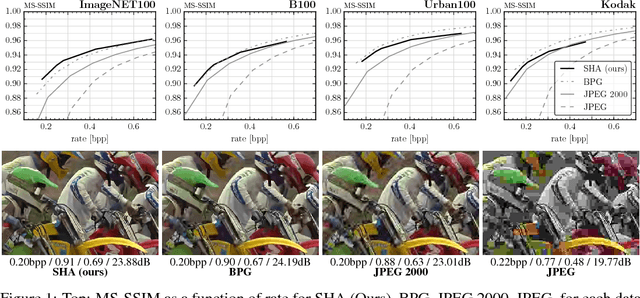

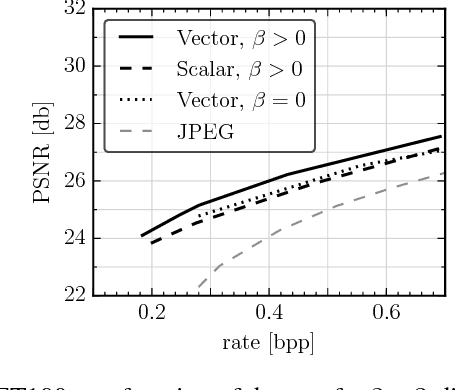
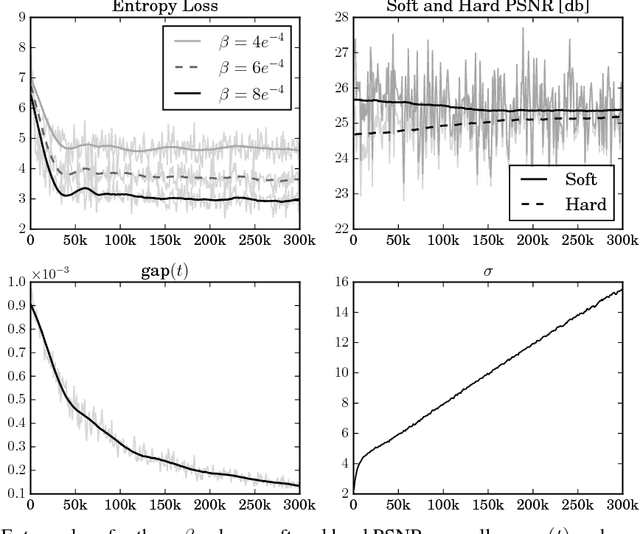
We present a new approach to learn compressible representations in deep architectures with an end-to-end training strategy. Our method is based on a soft (continuous) relaxation of quantization and entropy, which we anneal to their discrete counterparts throughout training. We showcase this method for two challenging applications: Image compression and neural network compression. While these tasks have typically been approached with different methods, our soft-to-hard quantization approach gives results competitive with the state-of-the-art for both.