 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRABLE: Benchmarking Tabular Machine Learning with Strings
May 12, 2026Benchmarking tabular learning has revealed the benefit of dedicated architectures, pushing the state of the art. But real-world tables often contain string entries, beyond numbers, and these settings have been understudied due to a lack of a solid benchmarking suite. They lead to new research questions: Are dedicated learners needed, with end-to-end modeling of strings and numbers? Or does it suffice to encode strings as numbers, as with a categorical encoding? And if so, do the resulting tables resemble numerical tabular data, calling for the same learners? To enable these studies, we contribute STRABLE, a benchmarking corpus of 108 tables, all real-world learning problems with strings and numbers across diverse application fields. We run the first large-scale empirical study of tabular learning with strings, evaluating 445 pipelines. These pipelines span end-to-end architectures and modular pipelines, where strings are first encoded, then post-processed, and finally passed to a tabular learner. We find that, because most tables in the wild are categorical-dominant, advanced tabular learners paired with simple string embeddings achieve good predictions at low computational cost. On free-text-dominant tables, large LLM encoders become competitive. Their performance also appears sensitive to post-processing, with differences across LLM families. Finally, we show that STRABLE is a good set of tables to study "string tabular" learning as it leads to generalizable pipeline rankings that are close to the oracle rankings. We thus establish STRABLE as a foundation for research on tabular learning with strings, an important yet understudied area.
Scalable Feature Learning on Huge Knowledge Graphs for Downstream Machine Learning
Jul 01, 2025
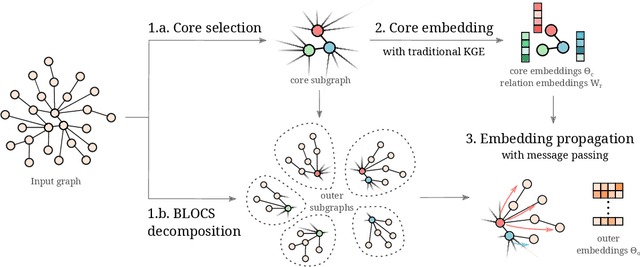
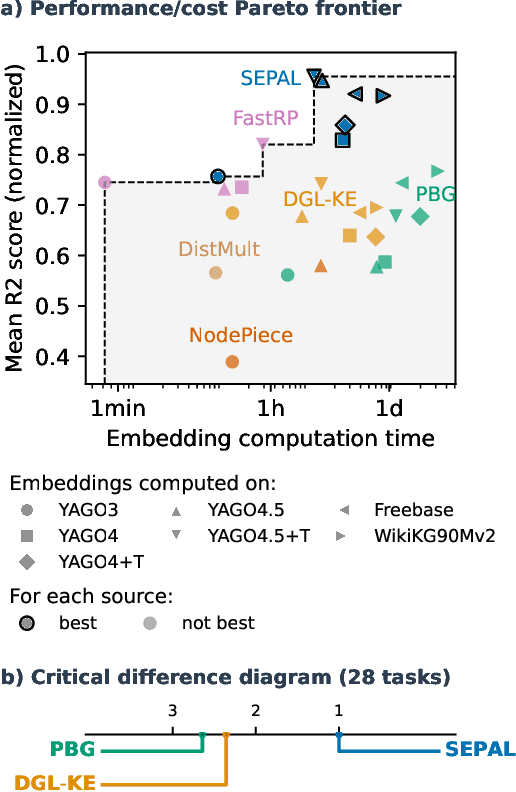
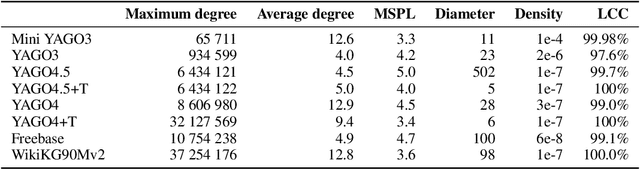
Many machine learning tasks can benefit from external knowledge. Large knowledge graphs store such knowledge, and embedding methods can be used to distill it into ready-to-use vector representations for downstream applications. For this purpose, current models have however two limitations: they are primarily optimized for link prediction, via local contrastive learning, and they struggle to scale to the largest graphs due to GPU memory limits. To address these, we introduce SEPAL: a Scalable Embedding Propagation ALgorithm for large knowledge graphs designed to produce high-quality embeddings for downstream tasks at scale. The key idea of SEPAL is to enforce global embedding alignment by optimizing embeddings only on a small core of entities, and then propagating them to the rest of the graph via message passing. We evaluate SEPAL on 7 large-scale knowledge graphs and 46 downstream machine learning tasks. Our results show that SEPAL significantly outperforms previous methods on downstream tasks. In addition, SEPAL scales up its base embedding model, enabling fitting huge knowledge graphs on commodity hardware.
Table Foundation Models: on knowledge pre-training for tabular learning
May 20, 2025Table foundation models bring high hopes to data science: pre-trained on tabular data to embark knowledge or priors, they should facilitate downstream tasks on tables. One specific challenge is that of data semantics: numerical entries take their meaning from context, e.g., column name. Pre-trained neural networks that jointly model column names and table entries have recently boosted prediction accuracy. While these models outline the promises of world knowledge to interpret table values, they lack the convenience of popular foundation models in text or vision. Indeed, they must be fine-tuned to bring benefits, come with sizeable computation costs, and cannot easily be reused or combined with other architectures. Here we introduce TARTE, a foundation model that transforms tables to knowledge-enhanced vector representations using the string to capture semantics. Pre-trained on large relational data, TARTE yields representations that facilitate subsequent learning with little additional cost. These representations can be fine-tuned or combined with other learners, giving models that push the state-of-the-art prediction performance and improve the prediction/computation performance trade-off. Specialized to a task or a domain, TARTE gives domain-specific representations that facilitate further learning. Our study demonstrates an effective approach to knowledge pre-training for tabular learning.