 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Feature Learning on Huge Knowledge Graphs for Downstream Machine Learning
Paper and Code
Jul 01, 2025
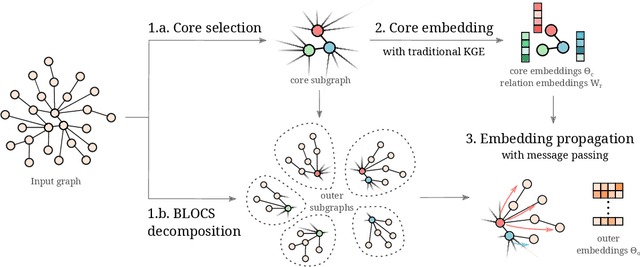
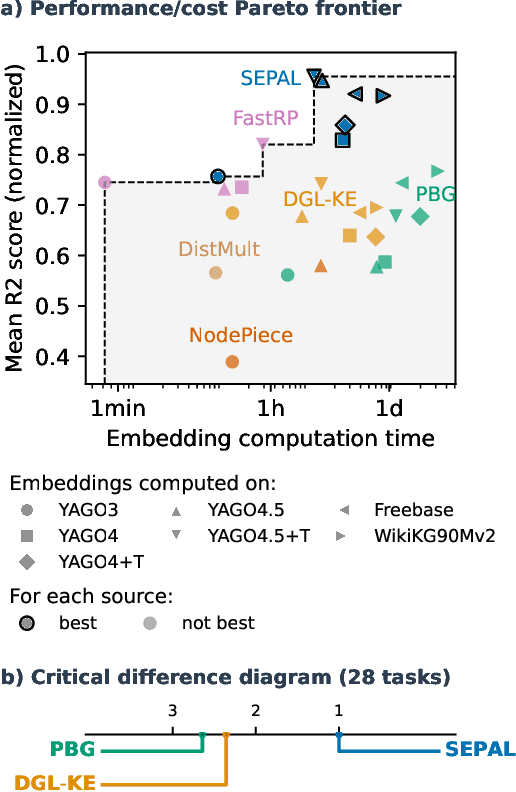
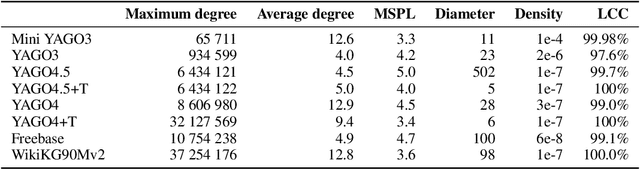
Many machine learning tasks can benefit from external knowledge. Large knowledge graphs store such knowledge, and embedding methods can be used to distill it into ready-to-use vector representations for downstream applications. For this purpose, current models have however two limitations: they are primarily optimized for link prediction, via local contrastive learning, and they struggle to scale to the largest graphs due to GPU memory limits. To address these, we introduce SEPAL: a Scalable Embedding Propagation ALgorithm for large knowledge graphs designed to produce high-quality embeddings for downstream tasks at scale. The key idea of SEPAL is to enforce global embedding alignment by optimizing embeddings only on a small core of entities, and then propagating them to the rest of the graph via message passing. We evaluate SEPAL on 7 large-scale knowledge graphs and 46 downstream machine learning tasks. Our results show that SEPAL significantly outperforms previous methods on downstream tasks. In addition, SEPAL scales up its base embedding model, enabling fitting huge knowledge graphs on commodity hardware.