 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning for Large-Scale Unsupervised Image Clustering
Aug 24, 2020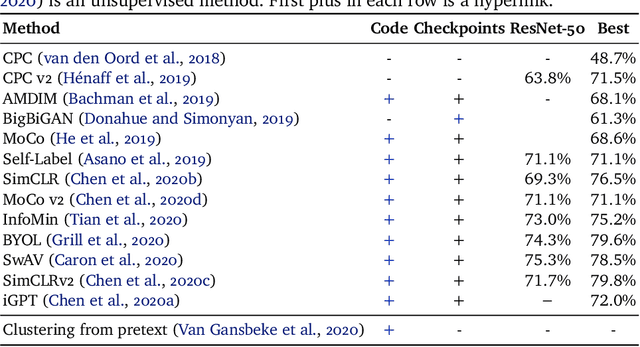
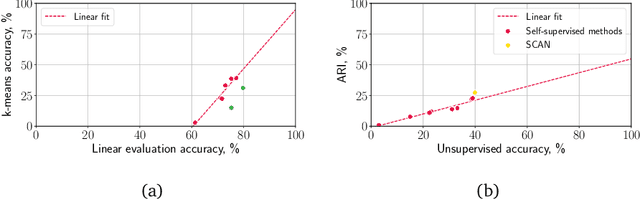
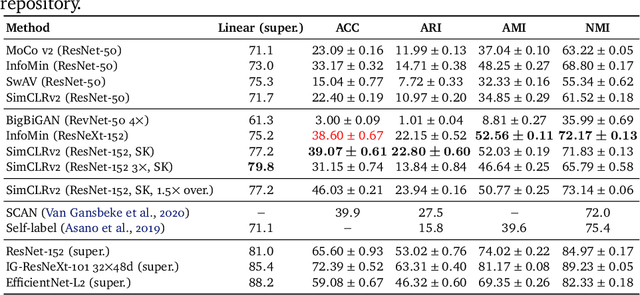
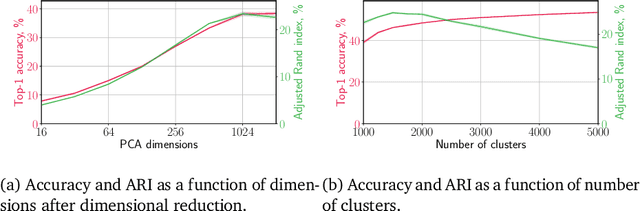
Unsupervised learning has always been appealing to machine learning researchers and practitioners, allowing them to avoid an expensive and complicated process of labeling the data. However, unsupervised learning of complex data is challenging, and even the best approaches show much weaker performance than their supervised counterparts. Self-supervised deep learning has become a strong instrument for representation learning in computer vision. However, those methods have not been evaluated in a fully unsupervised setting. In this paper, we propose a simple scheme for unsupervised classification based on self-supervised representations. We evaluate the proposed approach with several recent self-supervised methods showing that it achieves competitive results for ImageNet classification (39% accuracy on ImageNet with 1000 clusters and 46% with overclustering). We suggest adding the unsupervised evaluation to a set of standard benchmarks for self-supervised learning. The code is available at https://github.com/Randl/kmeans_selfsuper
HCM: Hardware-Aware Complexity Metric for Neural Network Architectures
Apr 26, 2020

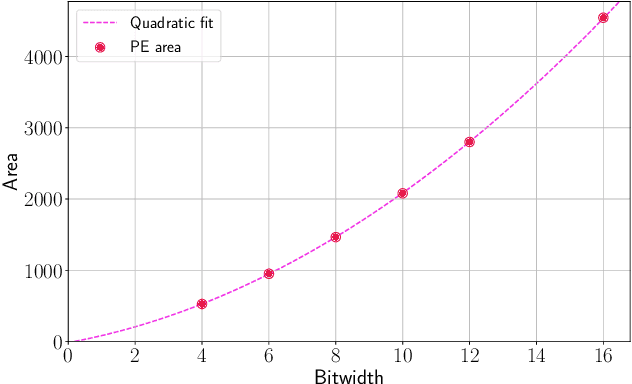
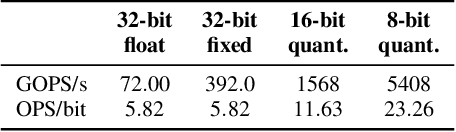
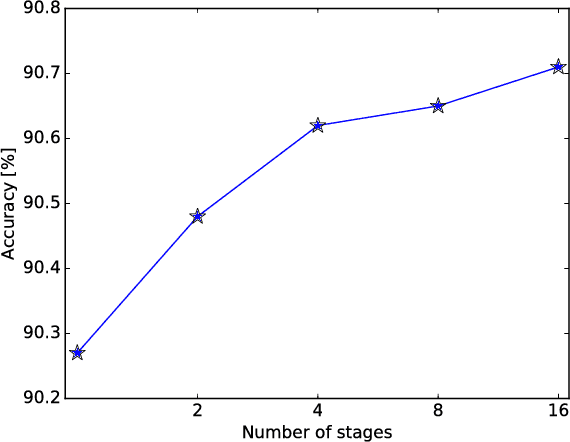
Convolutional Neural Networks (CNNs) have become common in many fields including computer vision, speech recognition, and natural language processing. Although CNN hardware accelerators are already included as part of many SoC architectures, the task of achieving high accuracy on resource-restricted devices is still considered challenging, mainly due to the vast number of design parameters that need to be balanced to achieve an efficient solution. Quantization techniques, when applied to the network parameters, lead to a reduction of power and area and may also change the ratio between communication and computation. As a result, some algorithmic solutions may suffer from lack of memory bandwidth or computational resources and fail to achieve the expected performance due to hardware constraints. Thus, the system designer and the micro-architect need to understand at early development stages the impact of their high-level decisions (e.g., the architecture of the CNN and the amount of bits used to represent its parameters) on the final product (e.g., the expected power saving, area, and accuracy). Unfortunately, existing tools fall short of supporting such decisions. This paper introduces a hardware-aware complexity metric that aims to assist the system designer of the neural network architectures, through the entire project lifetime (especially at its early stages) by predicting the impact of architectural and micro-architectural decisions on the final product. We demonstrate how the proposed metric can help evaluate different design alternatives of neural network models on resource-restricted devices such as real-time embedded systems, and to avoid making design mistakes at early stages.
Colored Noise Injection for Training Adversarially Robust Neural Networks
Mar 20, 2020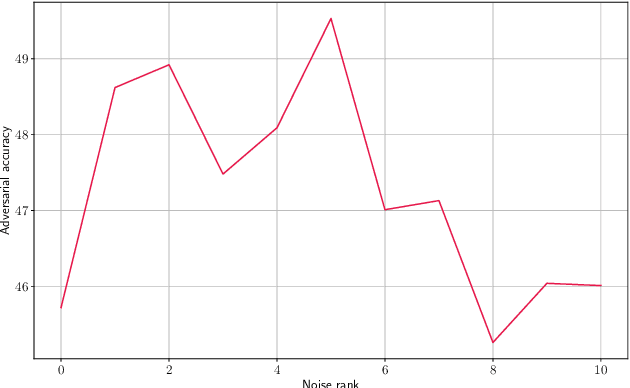
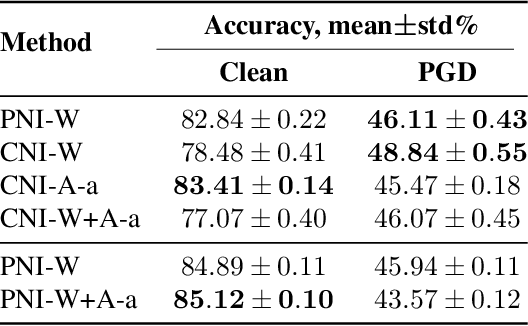
Even though deep learning has shown unmatched performance on various tasks, neural networks have been shown to be vulnerable to small adversarial perturbations of the input that lead to significant performance degradation. In this work we extend the idea of adding white Gaussian noise to the network weights and activations during adversarial training (PNI) to the injection of colored noise for defense against common white-box and black-box attacks. We show that our approach outperforms PNI and various previous approaches in terms of adversarial accuracy on CIFAR-10 and CIFAR-100 datasets. In addition, we provide an extensive ablation study of the proposed method justifying the chosen configurations.
Smoothed Inference for Adversarially-Trained Models
Nov 17, 2019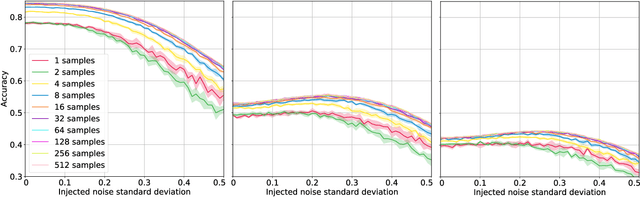
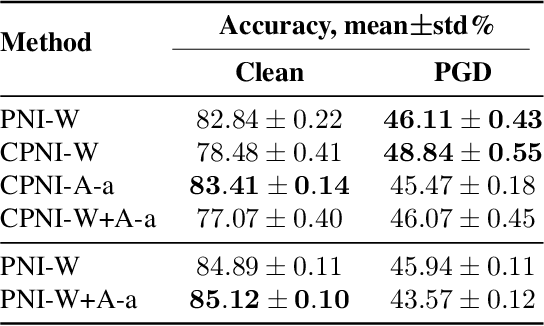
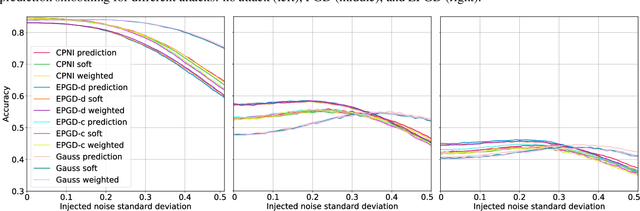
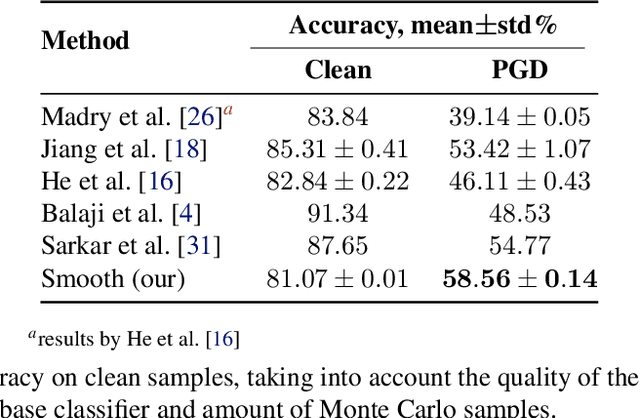
Deep neural networks are known to be vulnerable to inputs with maliciously constructed adversarial perturbations aimed at forcing misclassification. We study randomized smoothing as a way to both improve performance on unperturbed data as well as increase robustness to adversarial attacks. Moreover, we extend the method proposed by arXiv:1811.09310 by adding low-rank multivariate noise, which we then use as a base model for smoothing. The proposed method achieves 58.5% top-1 accuracy on CIFAR-10 under PGD attack and outperforms previous works by 4%. In addition, we consider a family of attacks, which were previously used for training purposes in the certified robustness scheme. We demonstrate that the proposed attacks are more effective than PGD against both smoothed and non-smoothed models. Since our method is based on sampling, it lends itself well for trading-off between the model inference complexity and its performance. A reference implementation of the proposed techniques is provided at https://github.com/yanemcovsky/SIAM.
Loss Aware Post-training Quantization
Nov 17, 2019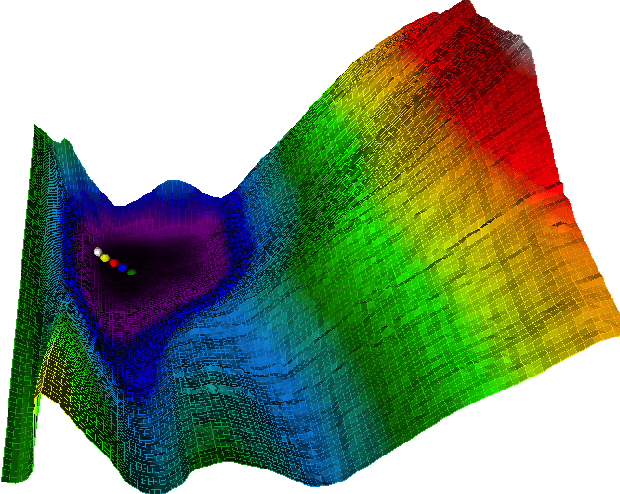
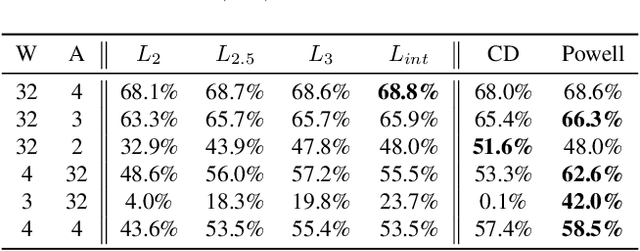
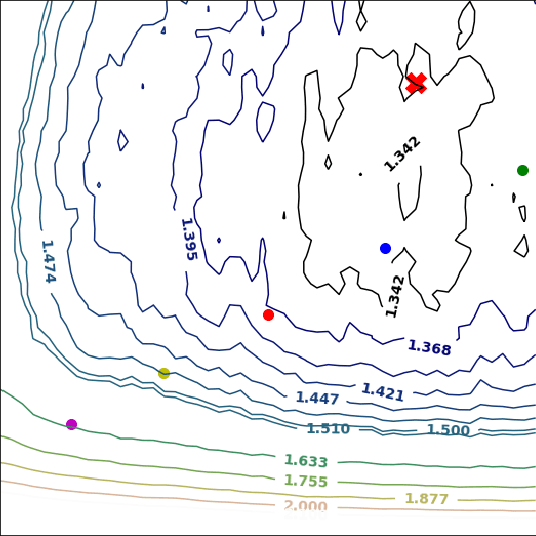
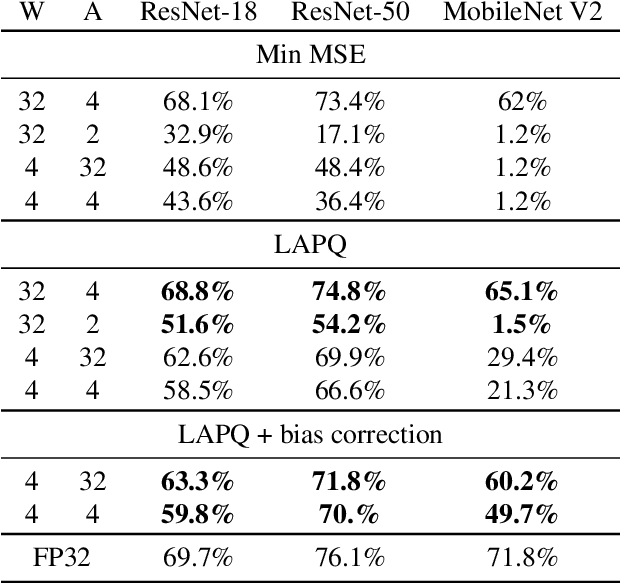
Neural network quantization enables the deployment of large models on resource-constrained devices. Current post-training quantization methods fall short in terms of accuracy for INT4 (or lower) but provide reasonable accuracy for INT8 (or above). In this work, we study the effect of quantization on the structure of the loss landscape. We show that the structure is flat and separable for mild quantization, enabling straightforward post-training quantization methods to achieve good results. On the other hand, we show that with more aggressive quantization, the loss landscape becomes highly non-separable with sharp minima points, making the selection of quantization parameters more challenging. Armed with this understanding, we design a method that quantizes the layer parameters jointly, enabling significant accuracy improvement over current post-training quantization methods. Reference implementation accompanies the paper at https://github.com/ynahshan/nn-quantization-pytorch/tree/master/lapq
CAT: Compression-Aware Training for bandwidth reduction
Sep 25, 2019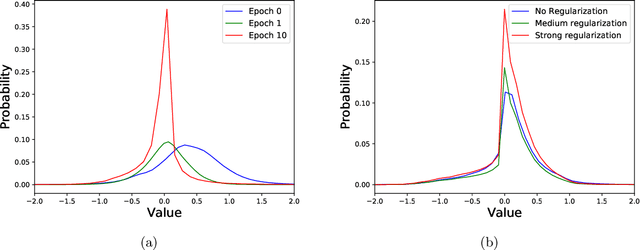
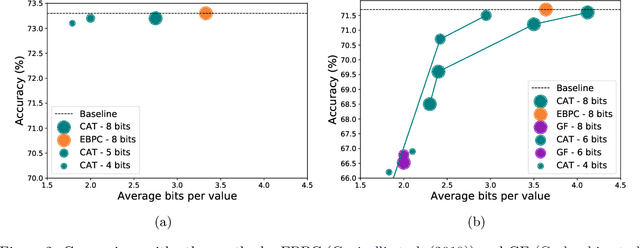

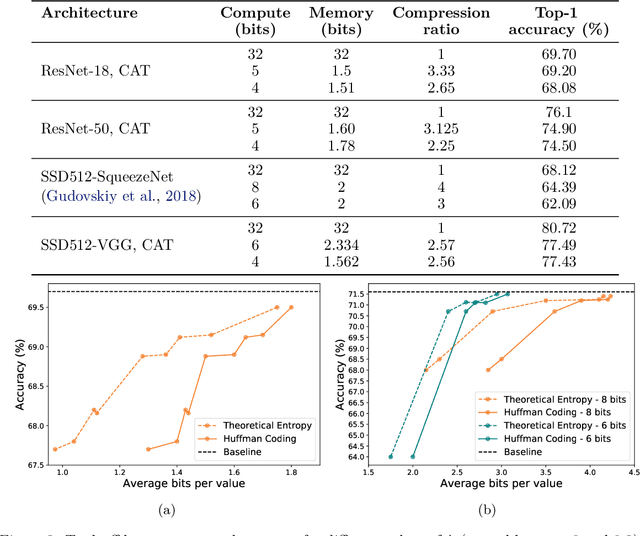
Convolutional neural networks (CNNs) have become the dominant neural network architecture for solving visual processing tasks. One of the major obstacles hindering the ubiquitous use of CNNs for inference is their relatively high memory bandwidth requirements, which can be a main energy consumer and throughput bottleneck in hardware accelerators. Accordingly, an efficient feature map compression method can result in substantial performance gains. Inspired by quantization-aware training approaches, we propose a compression-aware training (CAT) method that involves training the model in a way that allows better compression of feature maps during inference. Our method trains the model to achieve low-entropy feature maps, which enables efficient compression at inference time using classical transform coding methods. CAT significantly improves the state-of-the-art results reported for quantization. For example, on ResNet-34 we achieve 73.1% accuracy (0.2% degradation from the baseline) with an average representation of only 1.79 bits per value. Reference implementation accompanies the paper at https://github.com/CAT-teams/CAT
Feature Map Transform Coding for Energy-Efficient CNN Inference
May 26, 2019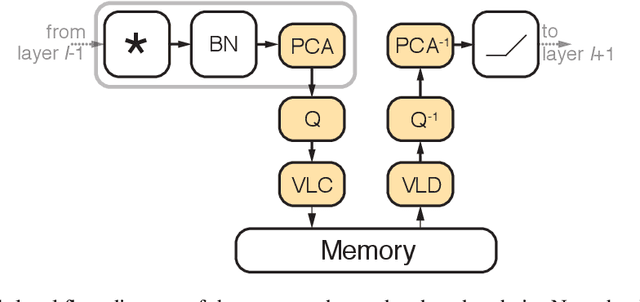
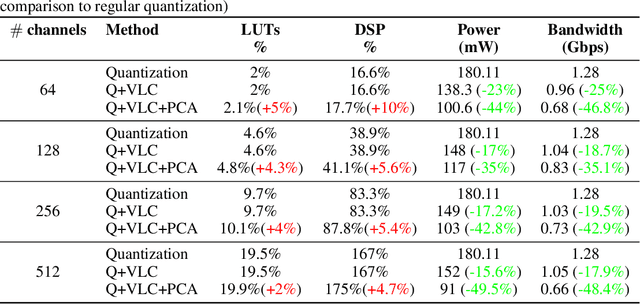
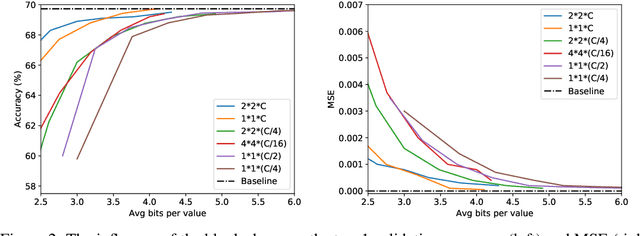
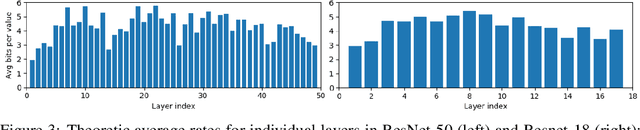
Convolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their relatively high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method exploits the high correlations between feature maps and adjacent pixels and allows to halve the data transfer volumes to the main memory without re-training. We analyze the performance of our approach on a variety of CNN architectures and demonstrated FPGA implementation of ResNet18 with our approach results in reduction of around 40% in the memory energy footprint compared to quantized network with negligible impact on accuracy. A reference implementation is available at https://github.com/CompressTeam/TransformCodingInference
Towards Learning of Filter-Level Heterogeneous Compression of Convolutional Neural Networks
Apr 29, 2019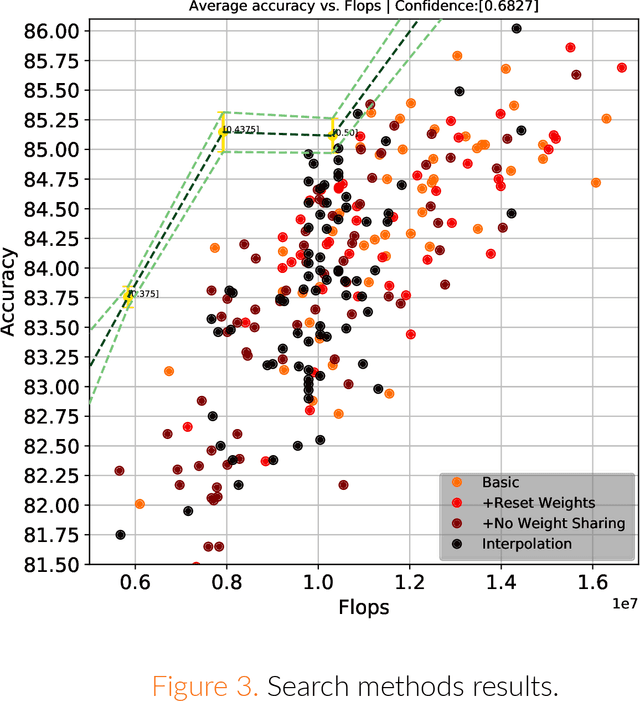
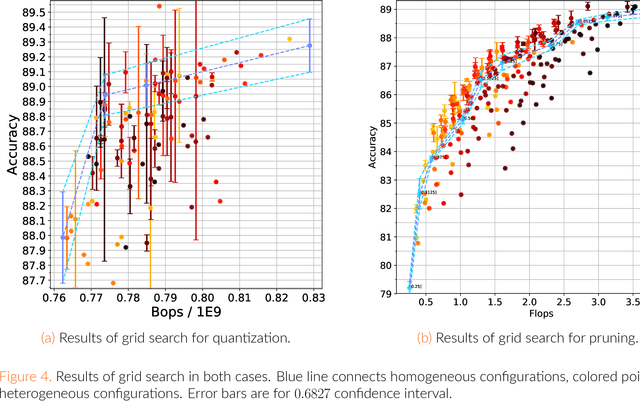
Recently, deep learning has become a de facto standard in machine learning with convolutional neural networks (CNNs) demonstrating spectacular success on a wide variety of tasks. However, CNNs are typically very demanding computationally at inference time. One of the ways to alleviate this burden on certain hardware platforms is quantization relying on the use of low-precision arithmetic representation for the weights and the activations. Another popular method is the pruning of the number of filters in each layer. While mainstream deep learning methods train the neural networks weights while keeping the network architecture fixed, the emerging neural architecture search (NAS) techniques make the latter also amenable to training. In this paper, we formulate optimal arithmetic bit length allocation and neural network pruning as a NAS problem, searching for the configurations satisfying a computational complexity budget while maximizing the accuracy. We use a differentiable search method based on the continuous relaxation of the search space proposed by Liu et al. (arXiv:1806.09055). We show, by grid search, that heterogeneous quantized networks suffer from a high variance which renders the benefit of the search questionable. For pruning, improvement over homogeneous cases is possible, but it is still challenging to find those configurations with the proposed method. The code is publicly available at https://github.com/yochaiz/Slimmable and https://github.com/yochaiz/darts-UNIQ
UNIQ: Uniform Noise Injection for Non-Uniform Quantization of Neural Networks
Oct 02, 2018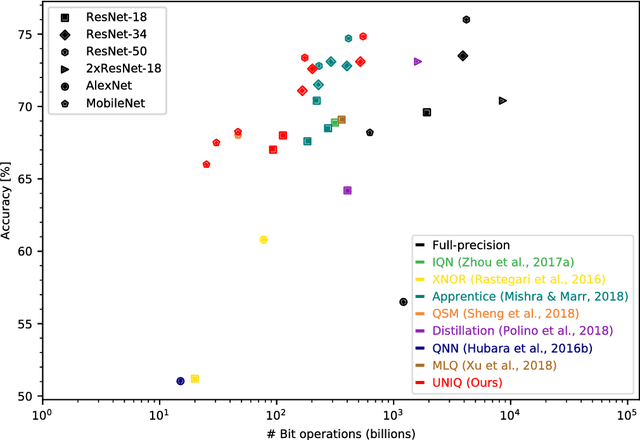
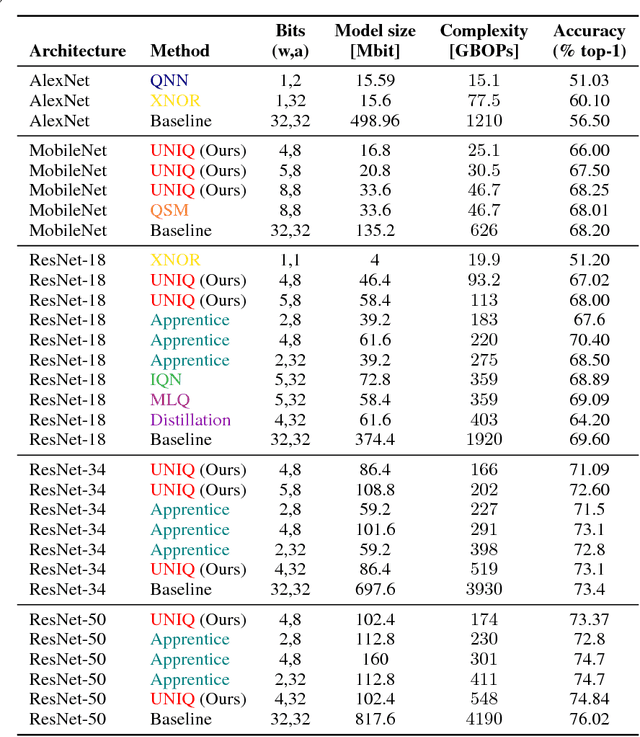
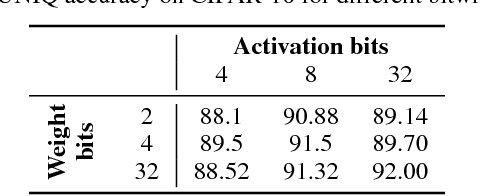
We present a novel method for neural network quantization that emulates a non-uniform $k$-quantile quantizer, which adapts to the distribution of the quantized parameters. Our approach provides a novel alternative to the existing uniform quantization techniques for neural networks. We suggest to compare the results as a function of the bit-operations (BOPS) performed, assuming a look-up table availability for the non-uniform case. In this setup, we show the advantages of our strategy in the low computational budget regime. While the proposed solution is harder to implement in hardware, we believe it sets a basis for new alternatives to neural networks quantization.
NICE: Noise Injection and Clamping Estimation for Neural Network Quantization
Oct 02, 2018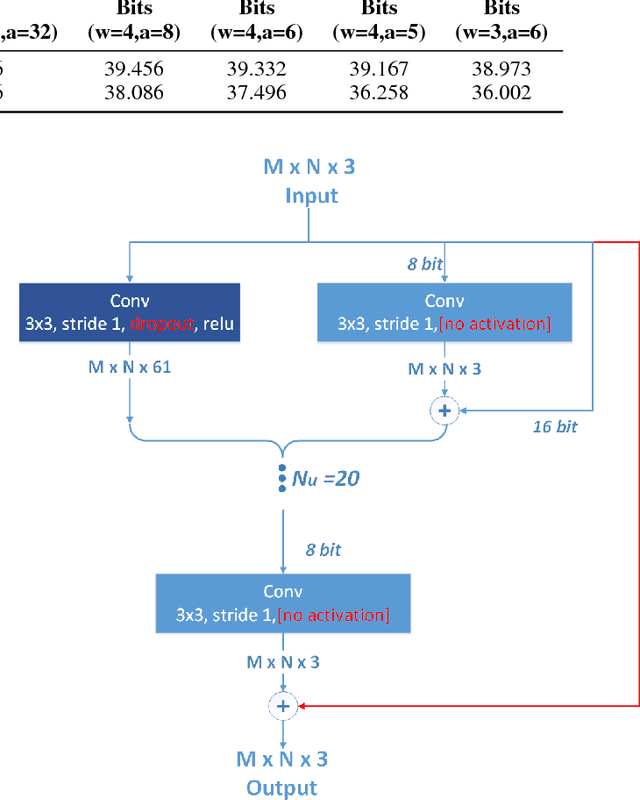
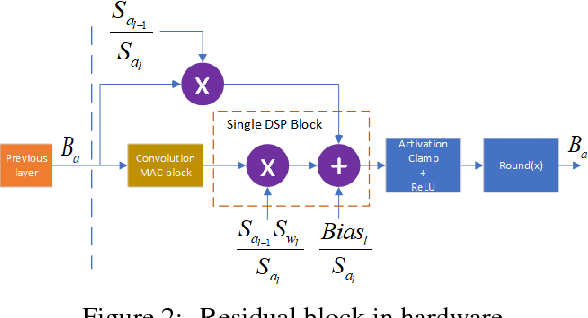
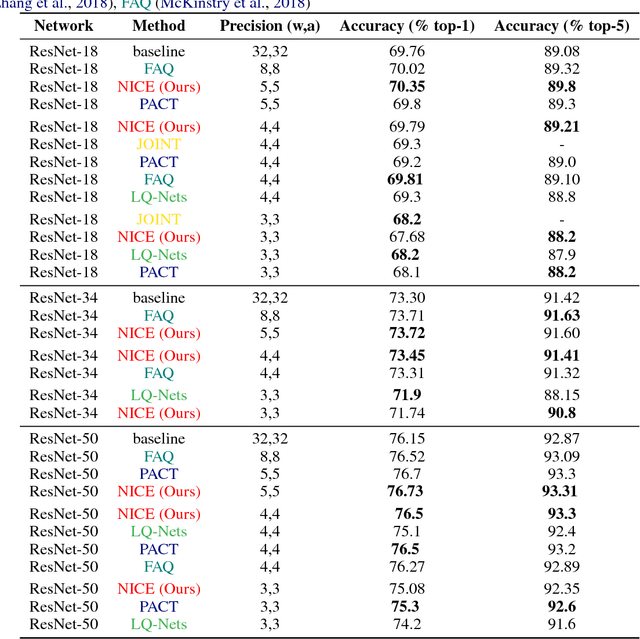

Convolutional Neural Networks (CNN) are very popular in many fields including computer vision, speech recognition, natural language processing, to name a few. Though deep learning leads to groundbreaking performance in these domains, the networks used are very demanding computationally and are far from real-time even on a GPU, which is not power efficient and therefore does not suit low power systems such as mobile devices. To overcome this challenge, some solutions have been proposed for quantizing the weights and activations of these networks, which accelerate the runtime significantly. Yet, this acceleration comes at the cost of a larger error. The \uniqname method proposed in this work trains quantized neural networks by noise injection and a learned clamping, which improve the accuracy. This leads to state-of-the-art results on various regression and classification tasks, e.g., ImageNet classification with architectures such as ResNet-18/34/50 with low as 3-bit weights and activations. We implement the proposed solution on an FPGA to demonstrate its applicability for low power real-time applications. The implementation of the paper is available at https://github.com/Lancer555/NICE