 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Vision-Language Models via Tensor Decomposition: A Defense Against Adversarial Attacks
Sep 19, 2025



Vision language models (VLMs) excel in multimodal understanding but are prone to adversarial attacks. Existing defenses often demand costly retraining or significant architecture changes. We introduce a lightweight defense using tensor decomposition suitable for any pre-trained VLM, requiring no retraining. By decomposing and reconstructing vision encoder representations, it filters adversarial noise while preserving meaning. Experiments with CLIP on COCO and Flickr30K show improved robustness. On Flickr30K, it restores 12.3\% performance lost to attacks, raising Recall@1 accuracy from 7.5\% to 19.8\%. On COCO, it recovers 8.1\% performance, improving accuracy from 3.8\% to 11.9\%. Analysis shows Tensor Train decomposition with low rank (8-32) and low residual strength ($\alpha=0.1-0.2$) is optimal. This method is a practical, plug-and-play solution with minimal overhead for existing VLMs.
Multi-view Graph Condensation via Tensor Decomposition
Aug 20, 2025Graph Neural Networks (GNNs) have demonstrated remarkable results in various real-world applications, including drug discovery, object detection, social media analysis, recommender systems, and text classification. In contrast to their vast potential, training them on large-scale graphs presents significant computational challenges due to the resources required for their storage and processing. Graph Condensation has emerged as a promising solution to reduce these demands by learning a synthetic compact graph that preserves the essential information of the original one while maintaining the GNN's predictive performance. Despite their efficacy, current graph condensation approaches frequently rely on a computationally intensive bi-level optimization. Moreover, they fail to maintain a mapping between synthetic and original nodes, limiting the interpretability of the model's decisions. In this sense, a wide range of decomposition techniques have been applied to learn linear or multi-linear functions from graph data, offering a more transparent and less resource-intensive alternative. However, their applicability to graph condensation remains unexplored. This paper addresses this gap and proposes a novel method called Multi-view Graph Condensation via Tensor Decomposition (GCTD) to investigate to what extent such techniques can synthesize an informative smaller graph and achieve comparable downstream task performance. Extensive experiments on six real-world datasets demonstrate that GCTD effectively reduces graph size while preserving GNN performance, achieving up to a 4.0\ improvement in accuracy on three out of six datasets and competitive performance on large graphs compared to existing approaches. Our code is available at https://anonymous.4open.science/r/gctd-345A.
Improving Group Fairness in Tensor Completion via Imbalance Mitigating Entity Augmentation
Jul 28, 2025Group fairness is important to consider in tensor decomposition to prevent discrimination based on social grounds such as gender or age. Although few works have studied group fairness in tensor decomposition, they suffer from performance degradation. To address this, we propose STAFF(Sparse Tensor Augmentation For Fairness) to improve group fairness by minimizing the gap in completion errors of different groups while reducing the overall tensor completion error. Our main idea is to augment a tensor with augmented entities including sufficient observed entries to mitigate imbalance and group bias in the sparse tensor. We evaluate \method on tensor completion with various datasets under conventional and deep learning-based tensor models. STAFF consistently shows the best trade-off between completion error and group fairness; at most, it yields 36% lower MSE and 59% lower MADE than the second-best baseline.
Global and Local Structure Learning for Sparse Tensor Completion
Mar 26, 2025How can we accurately complete tensors by learning relationships of dimensions along each mode? Tensor completion, a widely studied problem, is to predict missing entries in incomplete tensors. Tensor decomposition methods, fundamental tensor analysis tools, have been actively developed to solve tensor completion tasks. However, standard tensor decomposition models have not been designed to learn relationships of dimensions along each mode, which limits to accurate tensor completion. Also, previously developed tensor decomposition models have required prior knowledge between relations within dimensions to model the relations, expensive to obtain. This paper proposes TGL (Tensor Decomposition Learning Global and Local Structures) to accurately predict missing entries in tensors. TGL reconstructs a tensor with factor matrices which learn local structures with GNN without prior knowledges. Extensive experiments are conducted to evaluate TGL with baselines and datasets.
ExpertGenQA: Open-ended QA generation in Specialized Domains
Mar 04, 2025
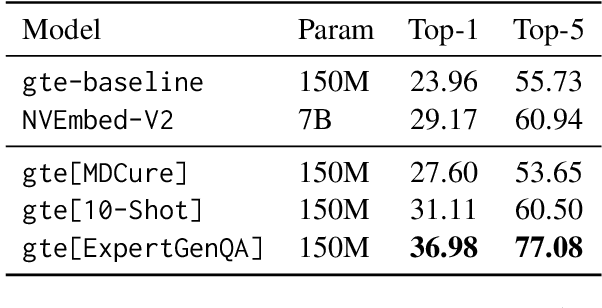
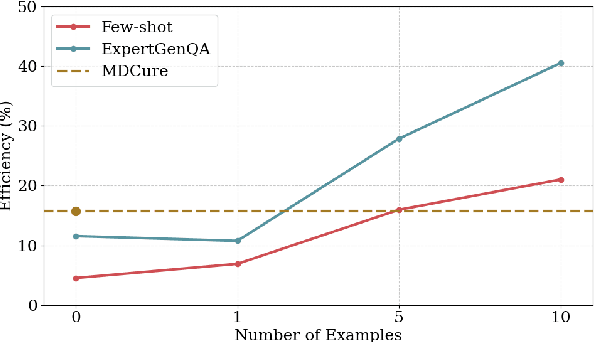
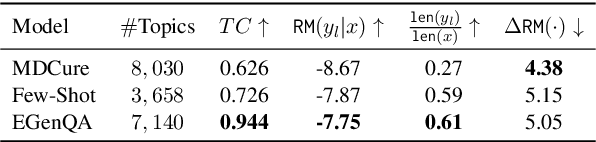
Generating high-quality question-answer pairs for specialized technical domains remains challenging, with existing approaches facing a tradeoff between leveraging expert examples and achieving topical diversity. We present ExpertGenQA, a protocol that combines few-shot learning with structured topic and style categorization to generate comprehensive domain-specific QA pairs. Using U.S. Federal Railroad Administration documents as a test bed, we demonstrate that ExpertGenQA achieves twice the efficiency of baseline few-shot approaches while maintaining $94.4\%$ topic coverage. Through systematic evaluation, we show that current LLM-based judges and reward models exhibit strong bias toward superficial writing styles rather than content quality. Our analysis using Bloom's Taxonomy reveals that ExpertGenQA better preserves the cognitive complexity distribution of expert-written questions compared to template-based approaches. When used to train retrieval models, our generated queries improve top-1 accuracy by $13.02\%$ over baseline performance, demonstrating their effectiveness for downstream applications in technical domains.
ACTGNN: Assessment of Clustering Tendency with Synthetically-Trained Graph Neural Networks
Jan 30, 2025



Determining clustering tendency in datasets is a fundamental but challenging task, especially in noisy or high-dimensional settings where traditional methods, such as the Hopkins Statistic and Visual Assessment of Tendency (VAT), often struggle to produce reliable results. In this paper, we propose ACTGNN, a graph-based framework designed to assess clustering tendency by leveraging graph representations of data. Node features are constructed using Locality-Sensitive Hashing (LSH), which captures local neighborhood information, while edge features incorporate multiple similarity metrics, such as the Radial Basis Function (RBF) kernel, to model pairwise relationships. A Graph Neural Network (GNN) is trained exclusively on synthetic datasets, enabling robust learning of clustering structures under controlled conditions. Extensive experiments demonstrate that ACTGNN significantly outperforms baseline methods on both synthetic and real-world datasets, exhibiting superior performance in detecting faint clustering structures, even in high-dimensional or noisy data. Our results highlight the generalizability and effectiveness of the proposed approach, making it a promising tool for robust clustering tendency assessment.
Multi-View Spectral Clustering for Graphs with Multiple View Structures
Jan 20, 2025



Despite the fundamental importance of clustering, to this day, much of the relevant research is still based on ambiguous foundations, leading to an unclear understanding of whether or how the various clustering methods are connected with each other. In this work, we provide an additional stepping stone towards resolving such ambiguities by presenting a general clustering framework that subsumes a series of seemingly disparate clustering methods, including various methods belonging to the wildly popular spectral clustering framework. In fact, the generality of the proposed framework is additionally capable of shedding light to the largely unexplored area of multi-view graphs whose each view may have differently clustered nodes. In turn, we propose GenClus: a method that is simultaneously an instance of this framework and a generalization of spectral clustering, while also being closely related to k-means as well. This results in a principled alternative to the few existing methods studying this special type of multi-view graphs. Then, we conduct in-depth experiments, which demonstrate that GenClus is more computationally efficient than existing methods, while also attaining similar or better clustering performance. Lastly, a qualitative real-world case-study further demonstrates the ability of GenClus to produce meaningful clusterings.
Can a Large Language Model Learn Matrix Functions In Context?
Nov 24, 2024



Large Language Models (LLMs) have demonstrated the ability to solve complex tasks through In-Context Learning (ICL), where models learn from a few input-output pairs without explicit fine-tuning. In this paper, we explore the capacity of LLMs to solve non-linear numerical computations, with specific emphasis on functions of the Singular Value Decomposition. Our experiments show that while LLMs perform comparably to traditional models such as Stochastic Gradient Descent (SGD) based Linear Regression and Neural Networks (NN) for simpler tasks, they outperform these models on more complex tasks, particularly in the case of top-k Singular Values. Furthermore, LLMs demonstrate strong scalability, maintaining high accuracy even as the matrix size increases. Additionally, we found that LLMs can achieve high accuracy with minimal prior examples, converging quickly and avoiding the overfitting seen in classical models. These results suggest that LLMs could provide an efficient alternative to classical methods for solving high-dimensional problems. Future work will focus on extending these findings to larger matrices and more complex matrix operations while exploring the effect of using different numerical representations in ICL.
Automating Data Science Pipelines with Tensor Completion
Oct 08, 2024



Hyperparameter optimization is an essential component in many data science pipelines and typically entails exhaustive time and resource-consuming computations in order to explore the combinatorial search space. Similar to this problem, other key operations in data science pipelines exhibit the exact same properties. Important examples are: neural architecture search, where the goal is to identify the best design choices for a neural network, and query cardinality estimation, where given different predicate values for a SQL query the goal is to estimate the size of the output. In this paper, we abstract away those essential components of data science pipelines and we model them as instances of tensor completion, where each variable of the search space corresponds to one mode of the tensor, and the goal is to identify all missing entries of the tensor, corresponding to all combinations of variable values, starting from a very small sample of observed entries. In order to do so, we first conduct a thorough experimental evaluation of existing state-of-the-art tensor completion techniques and introduce domain-inspired adaptations (such as smoothness across the discretized variable space) and an ensemble technique which is able to achieve state-of-the-art performance. We extensively evaluate existing and proposed methods in a number of datasets generated corresponding to (a) hyperparameter optimization for non-neural network models, (b) neural architecture search, and (c) variants of query cardinality estimation, demonstrating the effectiveness of tensor completion as a tool for automating data science pipelines. Furthermore, we release our generated datasets and code in order to provide benchmarks for future work on this topic.
Your Diffusion Model is Secretly a Noise Classifier and Benefits from Contrastive Training
Jul 12, 2024



Diffusion models learn to denoise data and the trained denoiser is then used to generate new samples from the data distribution. In this paper, we revisit the diffusion sampling process and identify a fundamental cause of sample quality degradation: the denoiser is poorly estimated in regions that are far Outside Of the training Distribution (OOD), and the sampling process inevitably evaluates in these OOD regions. This can become problematic for all sampling methods, especially when we move to parallel sampling which requires us to initialize and update the entire sample trajectory of dynamics in parallel, leading to many OOD evaluations. To address this problem, we introduce a new self-supervised training objective that differentiates the levels of noise added to a sample, leading to improved OOD denoising performance. The approach is based on our observation that diffusion models implicitly define a log-likelihood ratio that distinguishes distributions with different amounts of noise, and this expression depends on denoiser performance outside the standard training distribution. We show by diverse experiments that the proposed contrastive diffusion training is effective for both sequential and parallel settings, and it improves the performance and speed of parallel samplers significantly.