 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers learn through gradual rank increase
Jun 12, 2023



We identify incremental learning dynamics in transformers, where the difference between trained and initial weights progressively increases in rank. We rigorously prove this occurs under the simplifying assumptions of diagonal weight matrices and small initialization. Our experiments support the theory and also show that phenomenon can occur in practice without the simplifying assumptions.
The NTK approximation is valid for longer than you think
May 22, 2023We study when the neural tangent kernel (NTK) approximation is valid for training a model with the square loss. In the lazy training setting of Chizat et al. 2019, we show that rescaling the model by a factor of $\alpha = O(T)$ suffices for the NTK approximation to be valid until training time $T$. Our bound is tight and improves on the previous bound of Chizat et al. 2019, which required a larger rescaling factor of $\alpha = O(T^2)$.
Stabilizing Transformer Training by Preventing Attention Entropy Collapse
Mar 11, 2023Training stability is of great importance to Transformers. In this work, we investigate the training dynamics of Transformers by examining the evolution of the attention layers. In particular, we track the attention entropy for each attention head during the course of training, which is a proxy for model sharpness. We identify a common pattern across different architectures and tasks, where low attention entropy is accompanied by high training instability, which can take the form of oscillating loss or divergence. We denote the pathologically low attention entropy, corresponding to highly concentrated attention scores, as $\textit{entropy collapse}$. As a remedy, we propose $\sigma$Reparam, a simple and efficient solution where we reparametrize all linear layers with spectral normalization and an additional learned scalar. We demonstrate that the proposed reparameterization successfully prevents entropy collapse in the attention layers, promoting more stable training. Additionally, we prove a tight lower bound of the attention entropy, which decreases exponentially fast with the spectral norm of the attention logits, providing additional motivation for our approach. We conduct experiments with $\sigma$Reparam on image classification, image self-supervised learning, machine translation, automatic speech recognition, and language modeling tasks, across Transformer architectures. We show that $\sigma$Reparam provides stability and robustness with respect to the choice of hyperparameters, going so far as enabling training (a) a Vision Transformer to competitive performance without warmup, weight decay, layer normalization or adaptive optimizers; (b) deep architectures in machine translation and (c) speech recognition to competitive performance without warmup and adaptive optimizers.
The Slingshot Mechanism: An Empirical Study of Adaptive Optimizers and the Grokking Phenomenon
Jun 13, 2022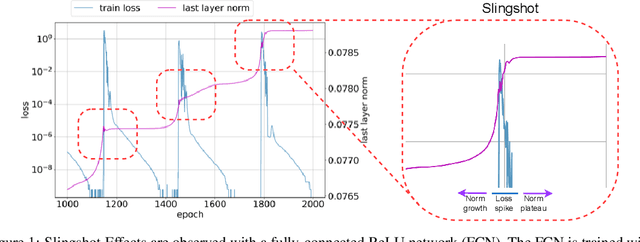
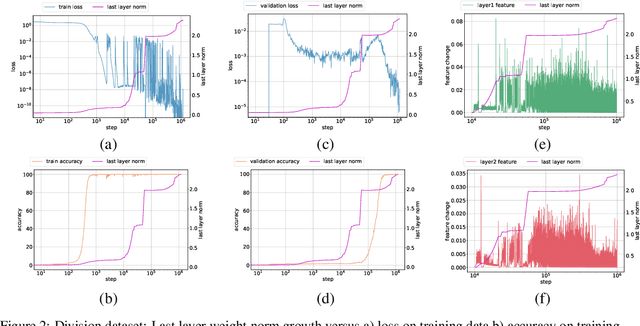
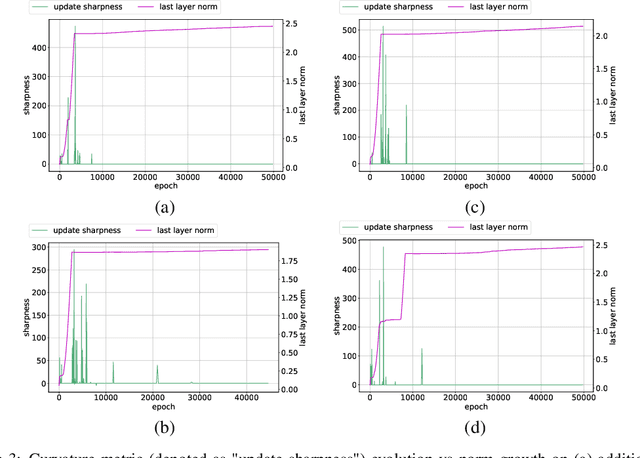
The grokking phenomenon as reported by Power et al. ( arXiv:2201.02177 ) refers to a regime where a long period of overfitting is followed by a seemingly sudden transition to perfect generalization. In this paper, we attempt to reveal the underpinnings of Grokking via a series of empirical studies. Specifically, we uncover an optimization anomaly plaguing adaptive optimizers at extremely late stages of training, referred to as the Slingshot Mechanism. A prominent artifact of the Slingshot Mechanism can be measured by the cyclic phase transitions between stable and unstable training regimes, and can be easily monitored by the cyclic behavior of the norm of the last layers weights. We empirically observe that without explicit regularization, Grokking as reported in ( arXiv:2201.02177 ) almost exclusively happens at the onset of Slingshots, and is absent without it. While common and easily reproduced in more general settings, the Slingshot Mechanism does not follow from any known optimization theories that we are aware of, and can be easily overlooked without an in depth examination. Our work points to a surprising and useful inductive bias of adaptive gradient optimizers at late stages of training, calling for a revised theoretical analysis of their origin.
Learning Representation from Neural Fisher Kernel with Low-rank Approximation
Feb 04, 2022
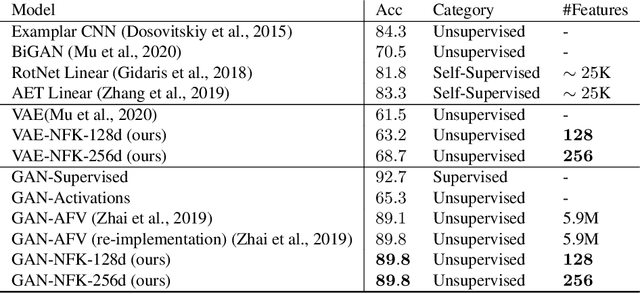
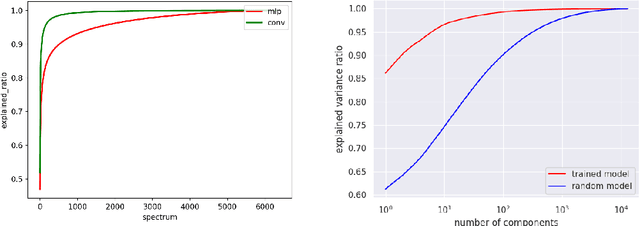
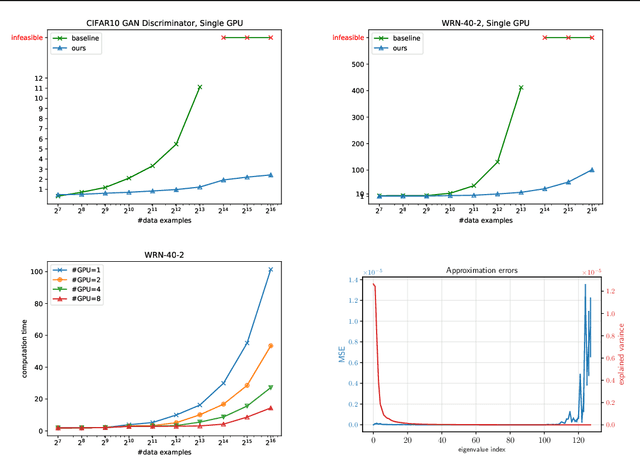
In this paper, we study the representation of neural networks from the view of kernels. We first define the Neural Fisher Kernel (NFK), which is the Fisher Kernel applied to neural networks. We show that NFK can be computed for both supervised and unsupervised learning models, which can serve as a unified tool for representation extraction. Furthermore, we show that practical NFKs exhibit low-rank structures. We then propose an efficient algorithm that computes a low rank approximation of NFK, which scales to large datasets and networks. We show that the low-rank approximation of NFKs derived from unsupervised generative models and supervised learning models gives rise to high-quality compact representations of data, achieving competitive results on a variety of machine learning tasks.
Implicit Greedy Rank Learning in Autoencoders via Overparameterized Linear Networks
Jul 02, 2021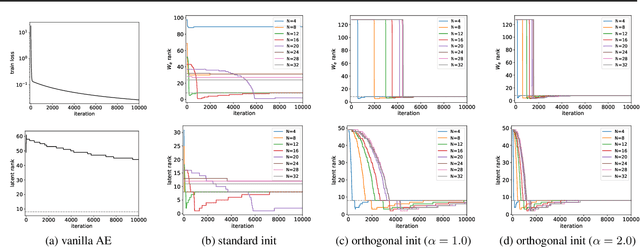
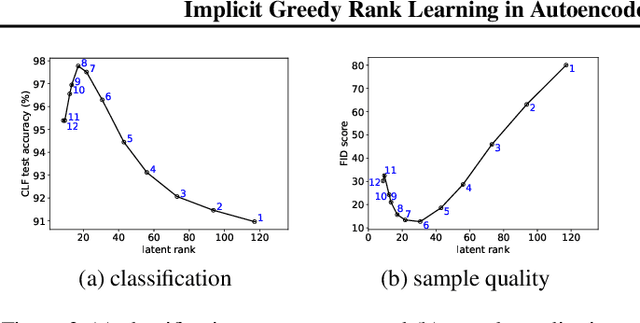
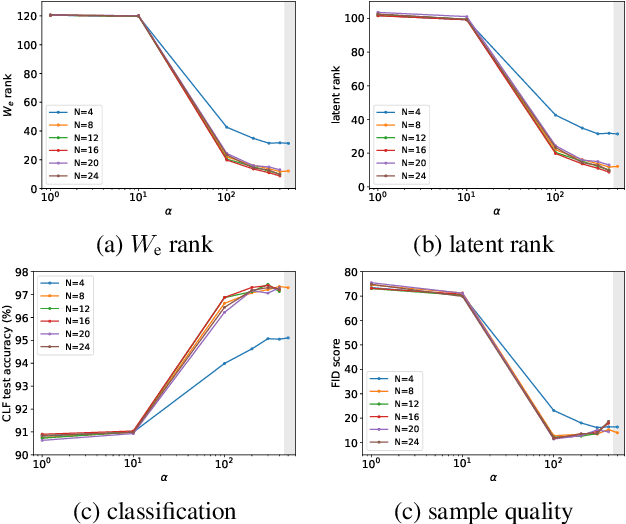
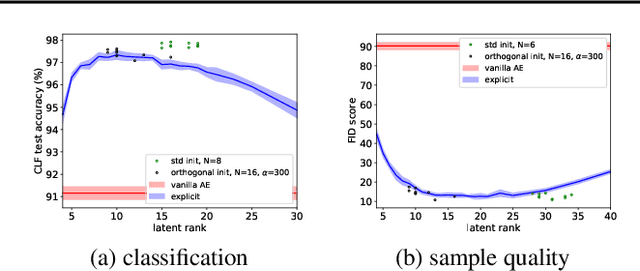
Deep linear networks trained with gradient descent yield low rank solutions, as is typically studied in matrix factorization. In this paper, we take a step further and analyze implicit rank regularization in autoencoders. We show greedy learning of low-rank latent codes induced by a linear sub-network at the autoencoder bottleneck. We further propose orthogonal initialization and principled learning rate adjustment to mitigate sensitivity of training dynamics to spectral prior and linear depth. With linear autoencoders on synthetic data, our method converges stably to ground-truth latent code rank. With nonlinear autoencoders, our method converges to latent ranks optimal for downstream classification and image sampling.
Implicit Acceleration and Feature Learning in Infinitely Wide Neural Networks with Bottlenecks
Jul 02, 2021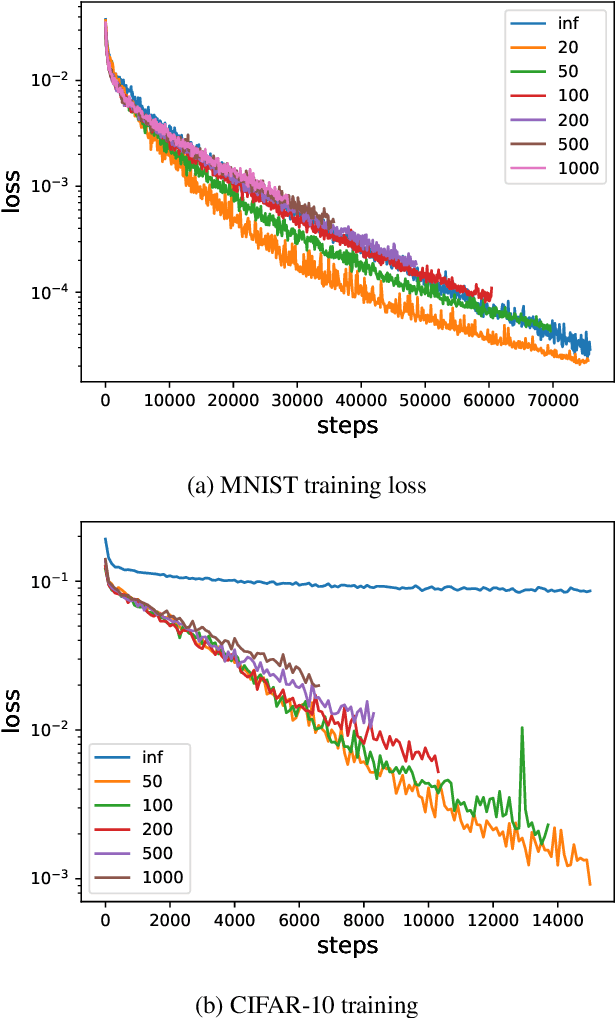
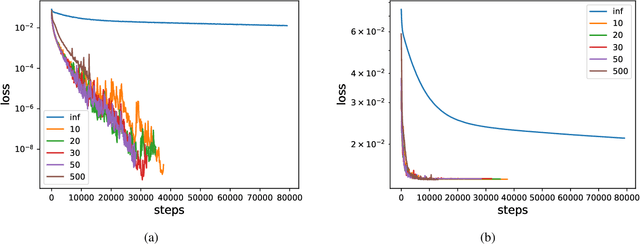
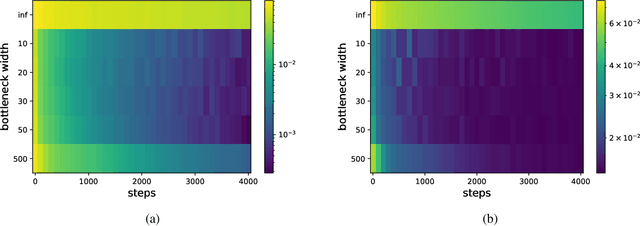
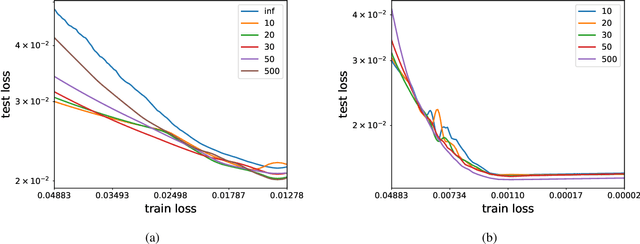
We analyze the learning dynamics of infinitely wide neural networks with a finite sized bottle-neck. Unlike the neural tangent kernel limit, a bottleneck in an otherwise infinite width network al-lows data dependent feature learning in its bottle-neck representation. We empirically show that a single bottleneck in infinite networks dramatically accelerates training when compared to purely in-finite networks, with an improved overall performance. We discuss the acceleration phenomena by drawing similarities to infinitely wide deep linear models, where the acceleration effect of a bottleneck can be understood theoretically.
Tensor Programs IIb: Architectural Universality of Neural Tangent Kernel Training Dynamics
May 08, 2021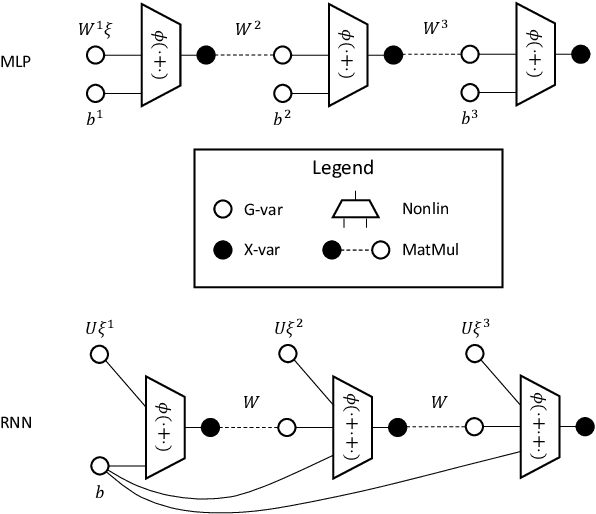
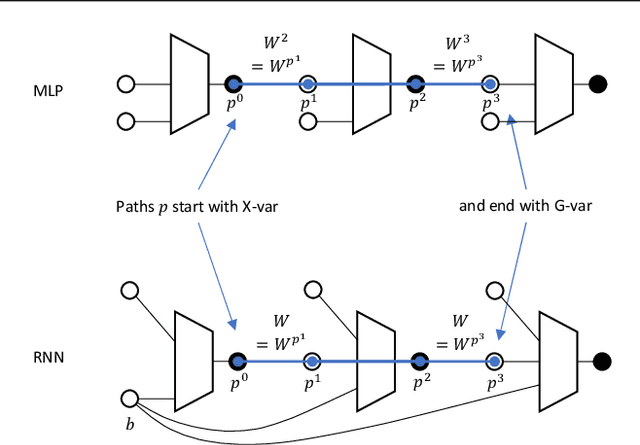
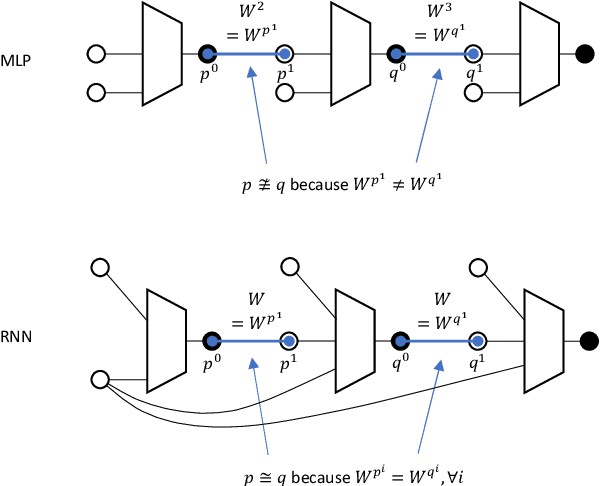
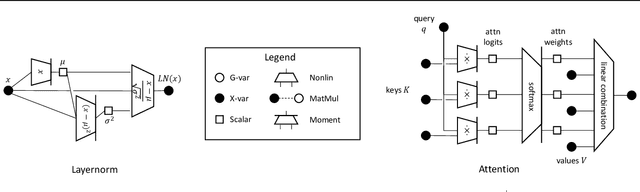
Yang (2020a) recently showed that the Neural Tangent Kernel (NTK) at initialization has an infinite-width limit for a large class of architectures including modern staples such as ResNet and Transformers. However, their analysis does not apply to training. Here, we show the same neural networks (in the so-called NTK parametrization) during training follow a kernel gradient descent dynamics in function space, where the kernel is the infinite-width NTK. This completes the proof of the *architectural universality* of NTK behavior. To achieve this result, we apply the Tensor Programs technique: Write the entire SGD dynamics inside a Tensor Program and analyze it via the Master Theorem. To facilitate this proof, we develop a graphical notation for Tensor Programs.
Collegial Ensembles
Jun 17, 2020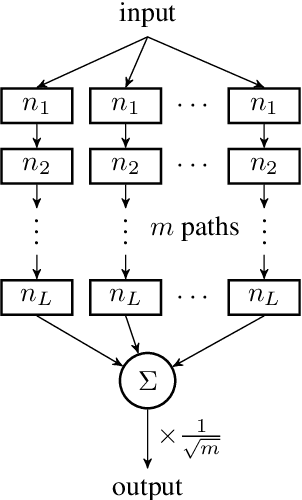
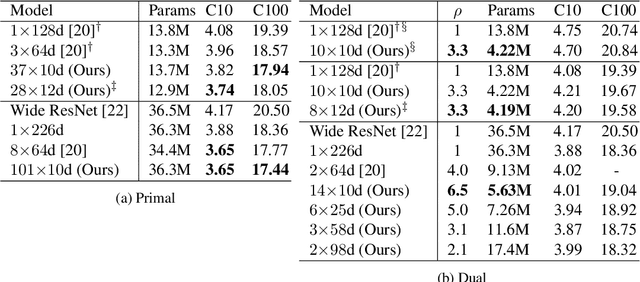
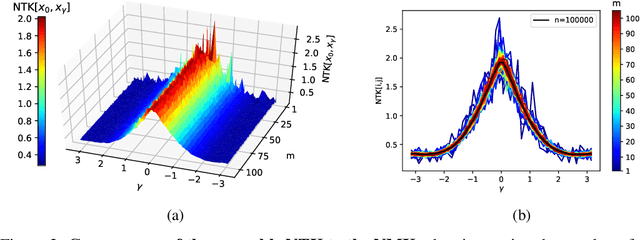
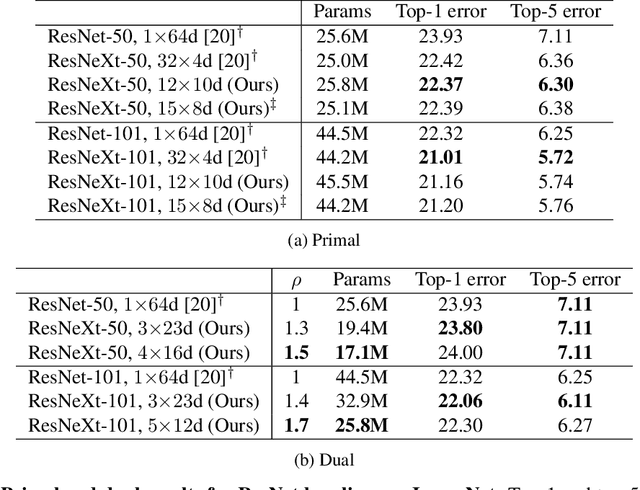
Modern neural network performance typically improves as model size increases. A recent line of research on the Neural Tangent Kernel (NTK) of over-parameterized networks indicates that the improvement with size increase is a product of a better conditioned loss landscape. In this work, we investigate a form of over-parameterization achieved through ensembling, where we define collegial ensembles (CE) as the aggregation of multiple independent models with identical architectures, trained as a single model. We show that the optimization dynamics of CE simplify dramatically when the number of models in the ensemble is large, resembling the dynamics of wide models, yet scale much more favorably. We use recent theoretical results on the finite width corrections of the NTK to perform efficient architecture search in a space of finite width CE that aims to either minimize capacity, or maximize trainability under a set of constraints. The resulting ensembles can be efficiently implemented in practical architectures using group convolutions and block diagonal layers. Finally, we show how our framework can be used to analytically derive optimal group convolution modules originally found using expensive grid searches, without having to train a single model.
On the Optimization Dynamics of Wide Hypernetworks
Apr 05, 2020Recent results in the theoretical study of deep learning have shown that the optimization dynamics of wide neural networks exhibit a surprisingly simple behaviour. In this work, we study the optimization dynamics of hypernetworks, which are architectures in which a learned meta-network produces the weights of a task-specific primary network. Hypernetworks have been demonstrated repeatedly to obtain state of the art results. However, their theoretical understanding is still lacking. As can be expected, the optimization process of multiplicative models is much more complicated than optimizing standard ReLU networks. It is shown that for an infinitely wide neural network with a gating layer the cost function cannot be accurately approximated by it first order Taylor approximation. Specifically, for a fixed sized primary network of depth H, the first H terms of the Taylor approximation of the cost function are non-zero, even when the meta-network is infinitely wide. However, for an infinitely wide meta and primary networks, the learning dynamics is determined by a linear model obtained from the first-order Taylor expansion of the network around its initial parameters and the kernel of this process is given by the Hadamard product of the kernels induced by the meta and primary networks. As part of our study, we partially solve an open problem suggested by Dyer & Gur-Ari (2020) and show that the convergence rate of the r order term of the Taylor expansion of the cost function, along the optimization trajectories of SGD is n^{1-r}, where n is the width of the learned neural network, improving upon the n^{-1} bound suggested by the conjecture of Dyer & Gur-Ari, while matching their empirical observations.