 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScope Restriction for Scalable Real-Time Railway Rescheduling: An Exploratory Study
May 05, 2023



With the aim to stimulate future research, we describe an exploratory study of a railway rescheduling problem. A widely used approach in practice and state of the art is to decompose these complex problems by geographical scope. Instead, we propose defining a core problem that restricts a rescheduling problem in response to a disturbance to only trains that need to be rescheduled, hence restricting the scope in both time and space. In this context, the difficulty resides in defining a scoper that can predict a subset of train services that will be affected by a given disturbance. We report preliminary results using the Flatland simulation environment that highlights the potential and challenges of this idea. We provide an extensible playground open-source implementation based on the Flatland railway environment and Answer-Set Programming.
Flatland Competition 2020: MAPF and MARL for Efficient Train Coordination on a Grid World
Mar 30, 2021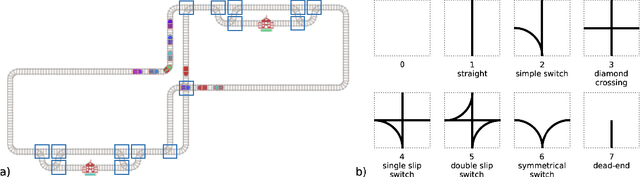
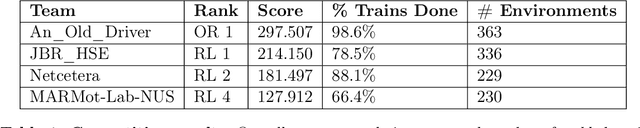
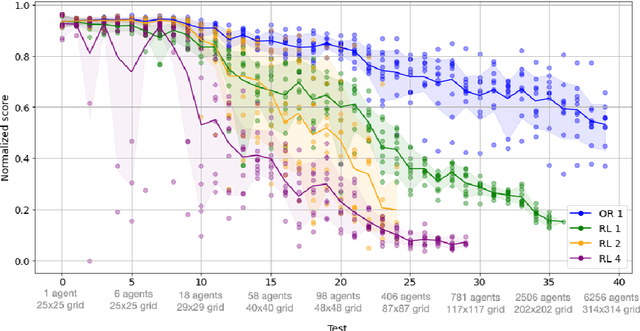
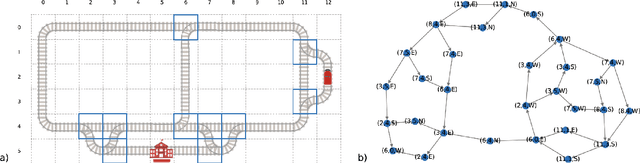
The Flatland competition aimed at finding novel approaches to solve the vehicle re-scheduling problem (VRSP). The VRSP is concerned with scheduling trips in traffic networks and the re-scheduling of vehicles when disruptions occur, for example the breakdown of a vehicle. While solving the VRSP in various settings has been an active area in operations research (OR) for decades, the ever-growing complexity of modern railway networks makes dynamic real-time scheduling of traffic virtually impossible. Recently, multi-agent reinforcement learning (MARL) has successfully tackled challenging tasks where many agents need to be coordinated, such as multiplayer video games. However, the coordination of hundreds of agents in a real-life setting like a railway network remains challenging and the Flatland environment used for the competition models these real-world properties in a simplified manner. Submissions had to bring as many trains (agents) to their target stations in as little time as possible. While the best submissions were in the OR category, participants found many promising MARL approaches. Using both centralized and decentralized learning based approaches, top submissions used graph representations of the environment to construct tree-based observations. Further, different coordination mechanisms were implemented, such as communication and prioritization between agents. This paper presents the competition setup, four outstanding solutions to the competition, and a cross-comparison between them.
Flatland-RL : Multi-Agent Reinforcement Learning on Trains
Dec 11, 2020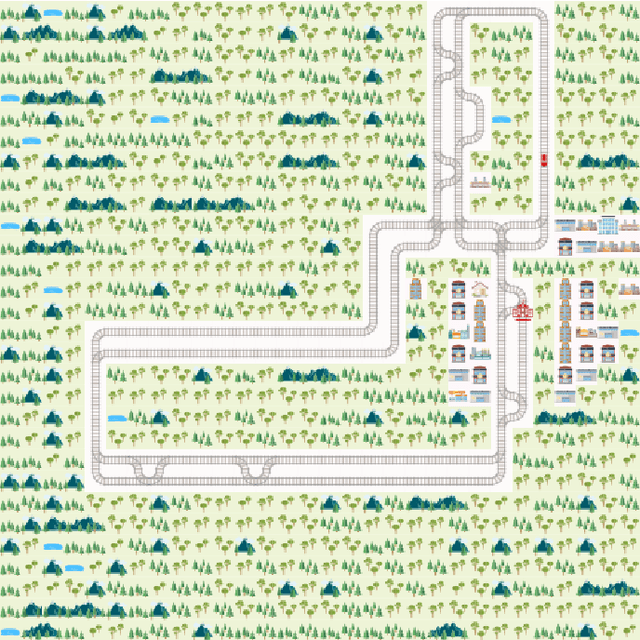
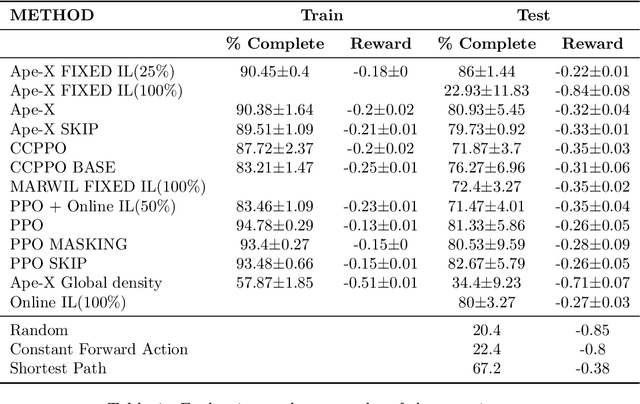
Efficient automated scheduling of trains remains a major challenge for modern railway systems. The underlying vehicle rescheduling problem (VRSP) has been a major focus of Operations Research (OR) since decades. Traditional approaches use complex simulators to study VRSP, where experimenting with a broad range of novel ideas is time consuming and has a huge computational overhead. In this paper, we introduce a two-dimensional simplified grid environment called "Flatland" that allows for faster experimentation. Flatland does not only reduce the complexity of the full physical simulation, but also provides an easy-to-use interface to test novel approaches for the VRSP, such as Reinforcement Learning (RL) and Imitation Learning (IL). In order to probe the potential of Machine Learning (ML) research on Flatland, we (1) ran a first series of RL and IL experiments and (2) design and executed a public Benchmark at NeurIPS 2020 to engage a large community of researchers to work on this problem. Our own experimental results, on the one hand, demonstrate that ML has potential in solving the VRSP on Flatland. On the other hand, we identify key topics that need further research. Overall, the Flatland environment has proven to be a robust and valuable framework to investigate the VRSP for railway networks. Our experiments provide a good starting point for further research and for the participants of the NeurIPS 2020 Flatland Benchmark. All of these efforts together have the potential to have a substantial impact on shaping the mobility of the future.
Improving Sample Efficiency and Multi-Agent Communication in RL-based Train Rescheduling
Apr 28, 2020
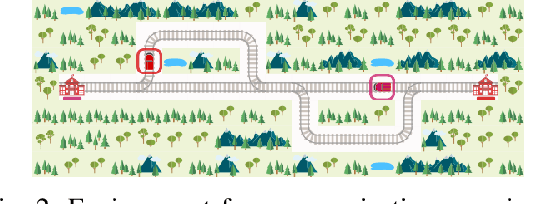
We present preliminary results from our sixth placed entry to the Flatland international competition for train rescheduling, including two improvements for optimized reinforcement learning (RL) training efficiency, and two hypotheses with respect to the prospect of deep RL for complex real-world control tasks: first, that current state of the art policy gradient methods seem inappropriate in the domain of high-consequence environments; second, that learning explicit communication actions (an emerging machine-to-machine language, so to speak) might offer a remedy. These hypotheses need to be confirmed by future work. If confirmed, they hold promises with respect to optimizing highly efficient logistics ecosystems like the Swiss Federal Railways railway network.