 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Rap Lyrics Generation with Denoising Autoencoders
Apr 08, 2020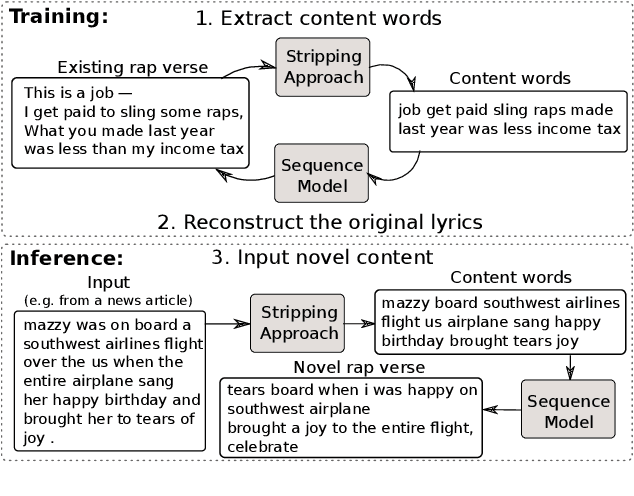
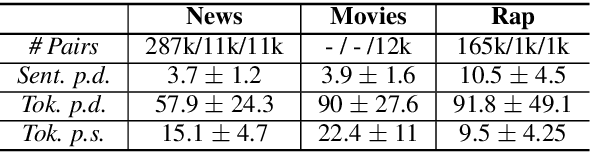
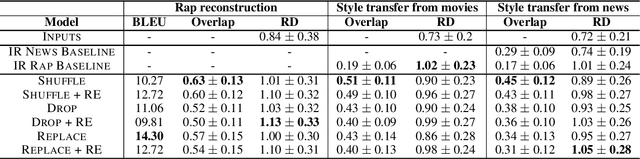
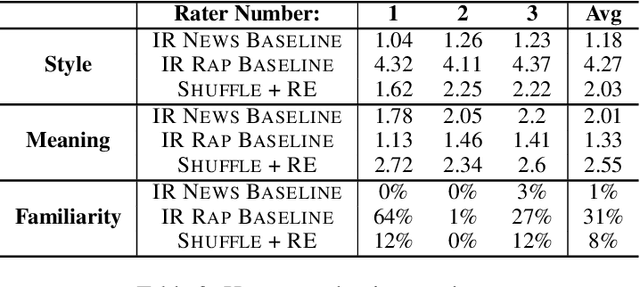
We develop a method for automatically synthesizing a rap verse given an input text written in another form, such as a summary of a news article. Our approach is to train a Transformer-based denoising autoencoder to reconstruct rap lyrics from content words. We study three different approaches for automatically stripping content words that convey the essential meaning of the lyrics. Moreover, we propose a BERT-based paraphrasing scheme for rhyme enhancement and show that it increases the average rhyme density of the lyrics by 10%. Experimental results on three diverse input domains -- existing rap lyrics, news, and movie plot summaries -- show that our method is capable of generating coherent and technically fluent rap verses that preserve the input content words. Human evaluation demonstrates that our approach gives a good trade-off between content preservation and style transfer compared to a strong information retrieval baseline.
Felix: Flexible Text Editing Through Tagging and Insertion
Mar 24, 2020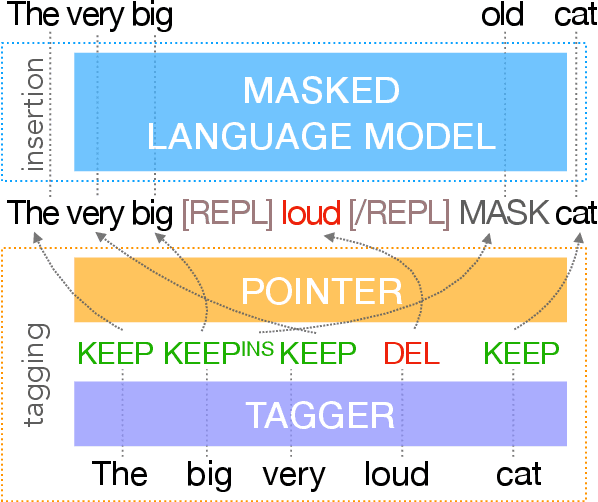
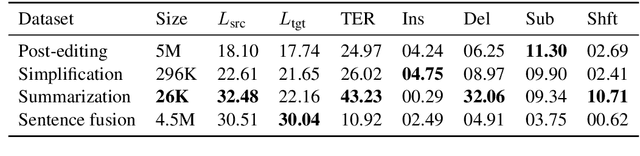

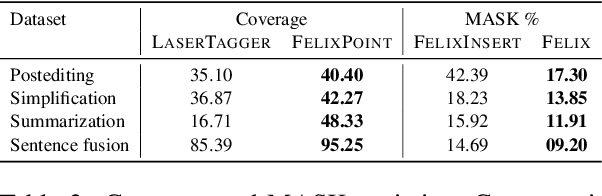
We present Felix --- a flexible text-editing approach for generation, designed to derive the maximum benefit from the ideas of decoding with bi-directional contexts and self-supervised pre-training. In contrast to conventional sequence-to-sequence (seq2seq) models, Felix is efficient in low-resource settings and fast at inference time, while being capable of modeling flexible input-output transformations. We achieve this by decomposing the text-editing task into two sub-tasks: tagging to decide on the subset of input tokens and their order in the output text and insertion to in-fill the missing tokens in the output not present in the input. The tagging model employs a novel Pointer mechanism, while the insertion model is based on a Masked Language Model. Both of these models are chosen to be non-autoregressive to guarantee faster inference. Felix performs favourably when compared to recent text-editing methods and strong seq2seq baselines when evaluated on four NLG tasks: Sentence Fusion, Machine Translation Automatic Post-Editing, Summarization, and Text Simplification.
Encode, Tag, Realize: High-Precision Text Editing
Sep 03, 2019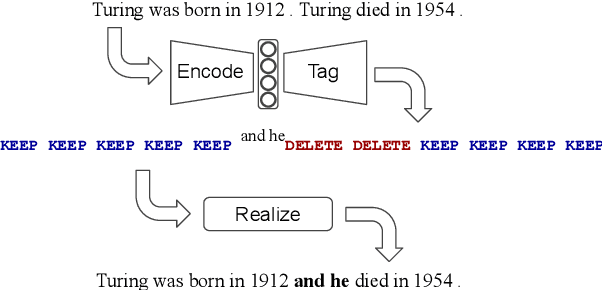

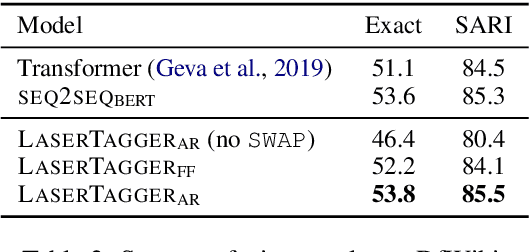
We propose LaserTagger - a sequence tagging approach that casts text generation as a text editing task. Target texts are reconstructed from the inputs using three main edit operations: keeping a token, deleting it, and adding a phrase before the token. To predict the edit operations, we propose a novel model, which combines a BERT encoder with an autoregressive Transformer decoder. This approach is evaluated on English text on four tasks: sentence fusion, sentence splitting, abstractive summarization, and grammar correction. LaserTagger achieves new state-of-the-art results on three of these tasks, performs comparably to a set of strong seq2seq baselines with a large number of training examples, and outperforms them when the number of examples is limited. Furthermore, we show that at inference time tagging can be more than two orders of magnitude faster than comparable seq2seq models, making it more attractive for running in a live environment.
DiscoFuse: A Large-Scale Dataset for Discourse-Based Sentence Fusion
Mar 18, 2019
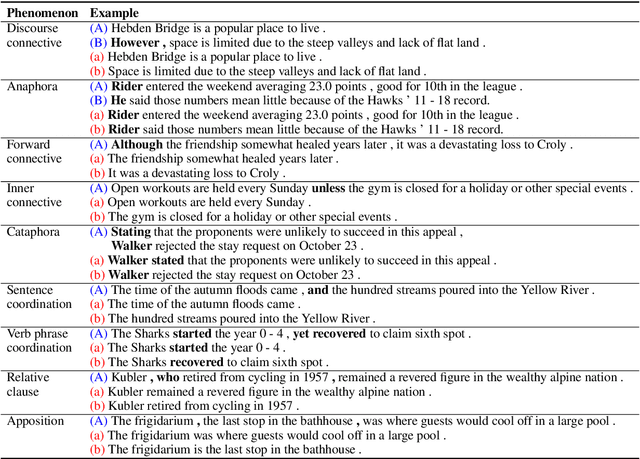
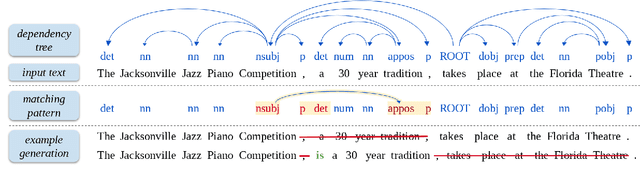

Sentence fusion is the task of joining several independent sentences into a single coherent text. Current datasets for sentence fusion are small and insufficient for training modern neural models. In this paper, we propose a method for automatically-generating fusion examples from raw text and present DiscoFuse, a large scale dataset for discourse-based sentence fusion. We author a set of rules for identifying a diverse set of discourse phenomena in raw text, and decomposing the text into two independent sentences. We apply our approach on two document collections: Wikipedia and Sports articles, yielding 60 million fusion examples annotated with discourse information required to reconstruct the fused text. We develop a sequence-to-sequence model on DiscoFuse and thoroughly analyze its strengths and weaknesses with respect to the various discourse phenomena, using both automatic as well as human evaluation. Finally, we conduct transfer learning experiments with WebSplit, a recent dataset for text simplification. We show that pretraining on DiscoFuse substantially improves performance on WebSplit when viewed as a sentence fusion task.
Responsible team players wanted: an analysis of soft skill requirements in job advertisements
Oct 13, 2018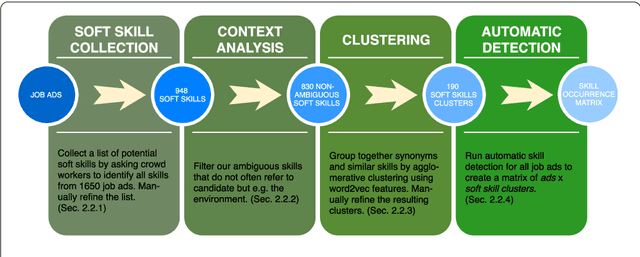
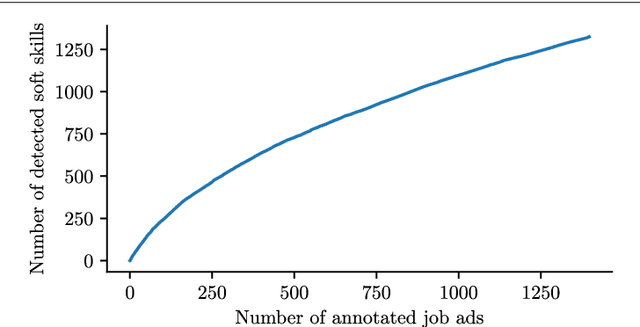
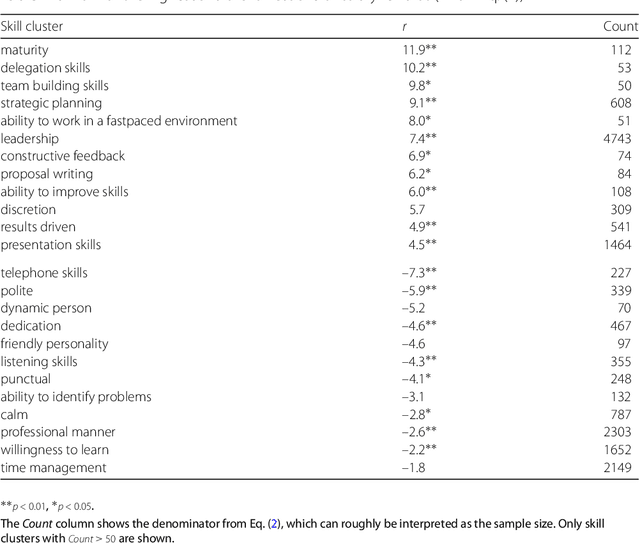
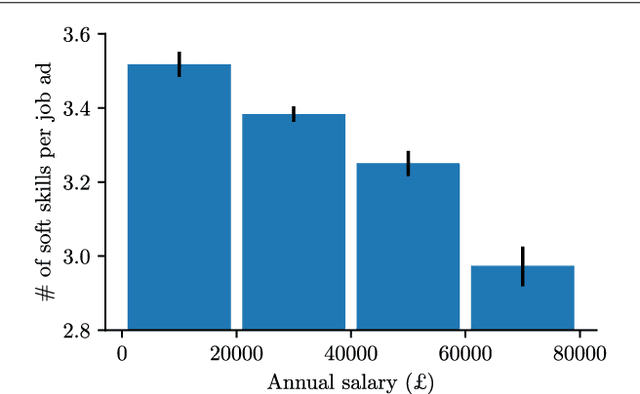
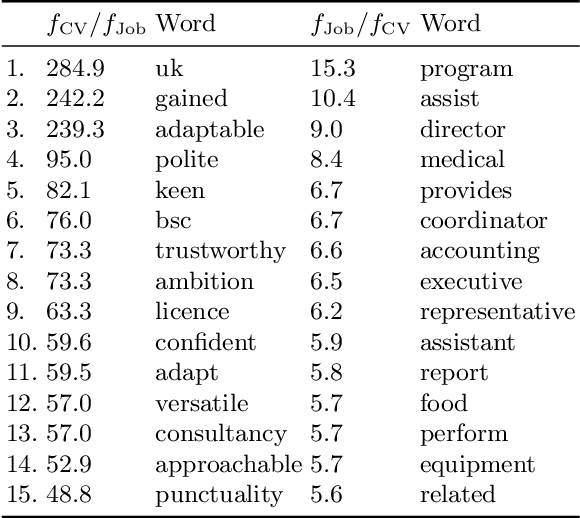
During the past decades the importance of soft skills for labour market outcomes has grown substantially. This carries implications for labour market inequality, since previous research shows that soft skills are not valued equally across race and gender. This work explores the role of soft skills in job advertisements by drawing on methods from computational science as well as on theoretical and empirical insights from economics, sociology and psychology. We present a semi-automatic approach based on crowdsourcing and text mining for extracting a list of soft skills. We find that soft skills are a crucial component of job ads, especially of low-paid jobs and jobs in female-dominated professions.Our work shows that soft skills can serve as partial predictors of the gender composition in job categories and that not all soft skills receive equal wage returns at the labour market. Especially "female" skills are associated with wage penalties. Our results expand the growing literature on soft skills and highlight the importance of soft skills for occupational gender segregation at labour markets.
Learning Representations for Soft Skill Matching
Jul 20, 2018

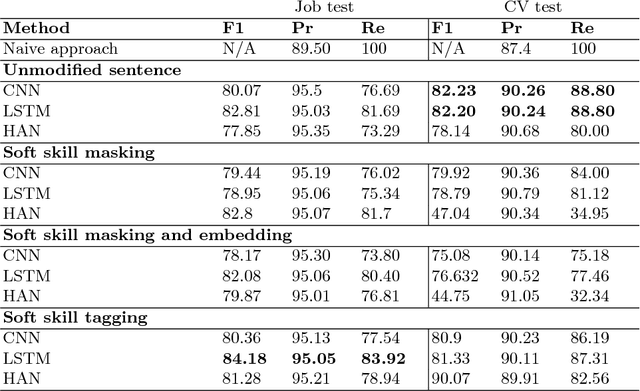
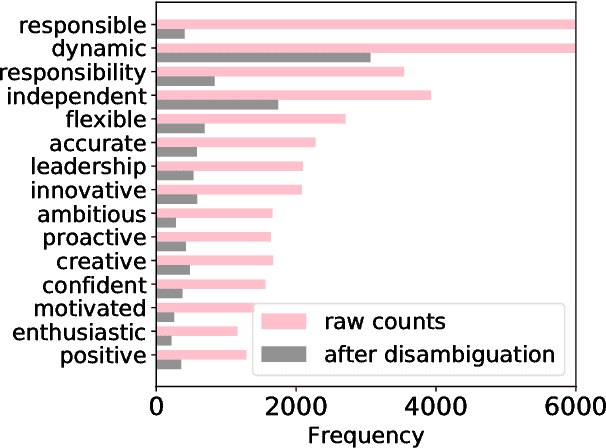
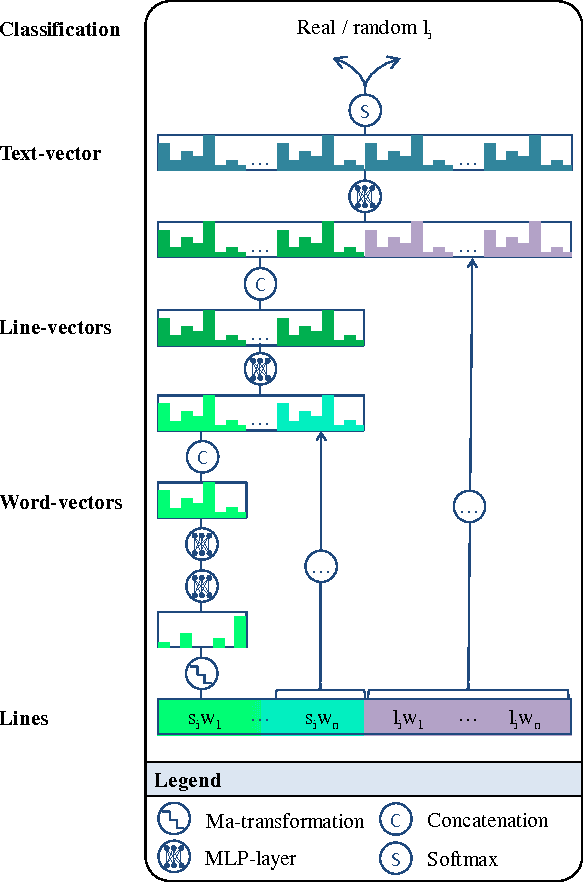
Employers actively look for talents having not only specific hard skills but also various soft skills. To analyze the soft skill demands on the job market, it is important to be able to detect soft skill phrases from job advertisements automatically. However, a naive matching of soft skill phrases can lead to false positive matches when a soft skill phrase, such as friendly, is used to describe a company, a team, or another entity, rather than a desired candidate. In this paper, we propose a phrase-matching-based approach which differentiates between soft skill phrases referring to a candidate vs. something else. The disambiguation is formulated as a binary text classification problem where the prediction is made for the potential soft skill based on the context where it occurs. To inform the model about the soft skill for which the prediction is made, we develop several approaches, including soft skill masking and soft skill tagging. We compare several neural network based approaches, including CNN, LSTM and Hierarchical Attention Model. The proposed tagging-based input representation using LSTM achieved the highest recall of 83.92% on the job dataset when fixing a precision to 95%.
Automatic Prediction of Discourse Connectives
Feb 01, 2018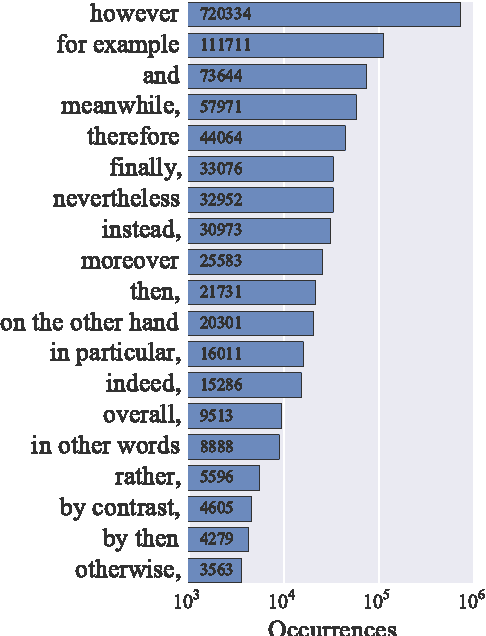

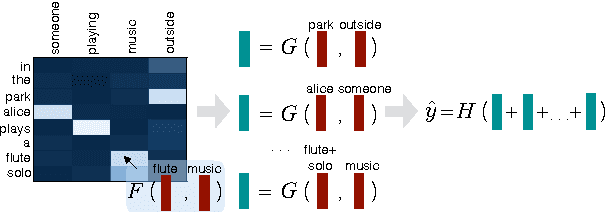
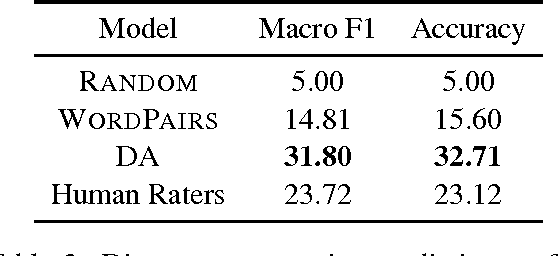
Accurate prediction of suitable discourse connectives (however, furthermore, etc.) is a key component of any system aimed at building coherent and fluent discourses from shorter sentences and passages. As an example, a dialog system might assemble a long and informative answer by sampling passages extracted from different documents retrieved from the Web. We formulate the task of discourse connective prediction and release a dataset of 2.9M sentence pairs separated by discourse connectives for this task. Then, we evaluate the hardness of the task for human raters, apply a recently proposed decomposable attention (DA) model to this task and observe that the automatic predictor has a higher F1 than human raters (32 vs. 30). Nevertheless, under specific conditions the raters still outperform the DA model, suggesting that there is headroom for future improvements.
Domain Adaptation for Resume Classification Using Convolutional Neural Networks
Jul 18, 2017
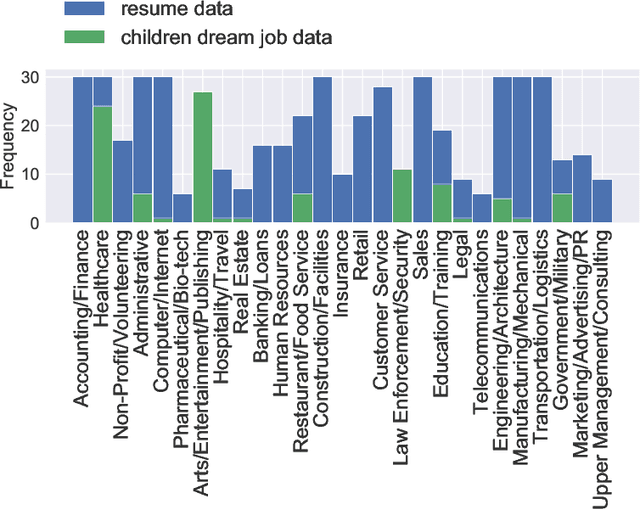
We propose a novel method for classifying resume data of job applicants into 27 different job categories using convolutional neural networks. Since resume data is costly and hard to obtain due to its sensitive nature, we use domain adaptation. In particular, we train a classifier on a large number of freely available job description snippets and then use it to classify resume data. We empirically verify a reasonable classification performance of our approach despite having only a small amount of labeled resume data available.
DopeLearning: A Computational Approach to Rap Lyrics Generation
Jun 09, 2016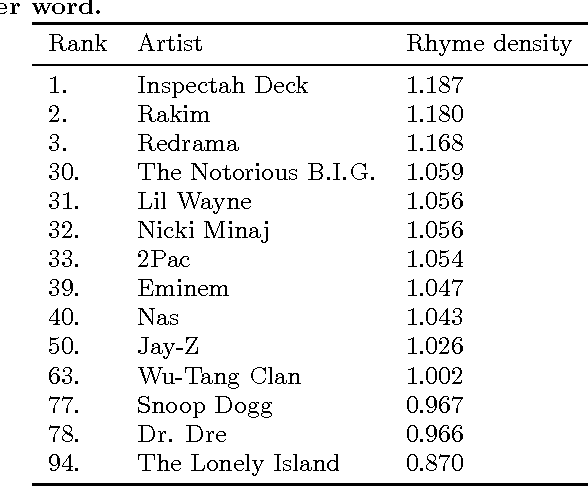
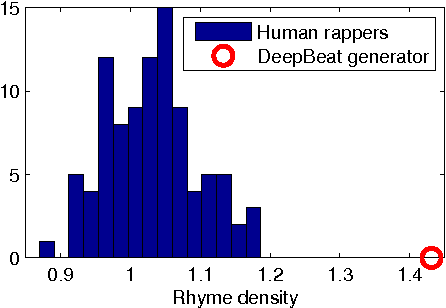

Writing rap lyrics requires both creativity to construct a meaningful, interesting story and lyrical skills to produce complex rhyme patterns, which form the cornerstone of good flow. We present a rap lyrics generation method that captures both of these aspects. First, we develop a prediction model to identify the next line of existing lyrics from a set of candidate next lines. This model is based on two machine-learning techniques: the RankSVM algorithm and a deep neural network model with a novel structure. Results show that the prediction model can identify the true next line among 299 randomly selected lines with an accuracy of 17%, i.e., over 50 times more likely than by random. Second, we employ the prediction model to combine lines from existing songs, producing lyrics with rhyme and a meaning. An evaluation of the produced lyrics shows that in terms of quantitative rhyme density, the method outperforms the best human rappers by 21%. The rap lyrics generator has been deployed as an online tool called DeepBeat, and the performance of the tool has been assessed by analyzing its usage logs. This analysis shows that machine-learned rankings correlate with user preferences.
Semi-Supervised Anomaly Detection - Towards Model-Independent Searches of New Physics
Apr 16, 2012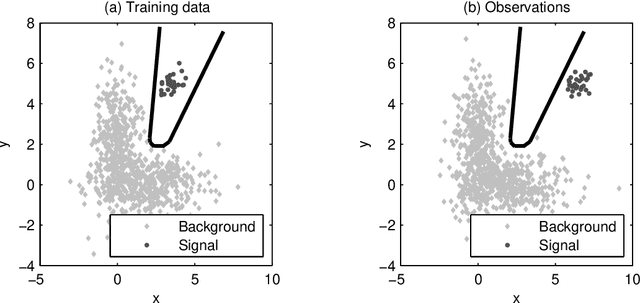
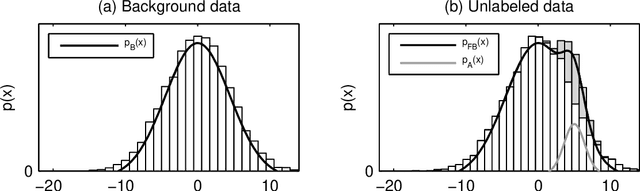
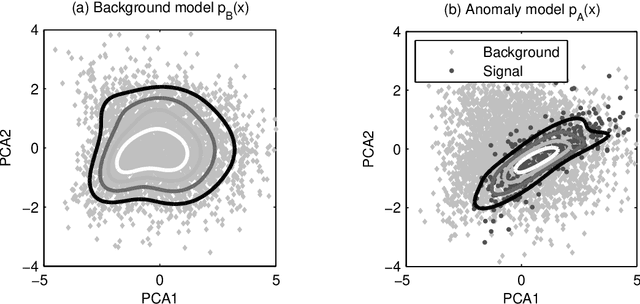
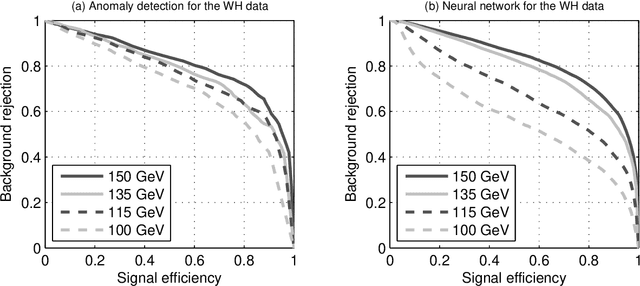
Most classification algorithms used in high energy physics fall under the category of supervised machine learning. Such methods require a training set containing both signal and background events and are prone to classification errors should this training data be systematically inaccurate for example due to the assumed MC model. To complement such model-dependent searches, we propose an algorithm based on semi-supervised anomaly detection techniques, which does not require a MC training sample for the signal data. We first model the background using a multivariate Gaussian mixture model. We then search for deviations from this model by fitting to the observations a mixture of the background model and a number of additional Gaussians. This allows us to perform pattern recognition of any anomalous excess over the background. We show by a comparison to neural network classifiers that such an approach is a lot more robust against misspecification of the signal MC than supervised classification. In cases where there is an unexpected signal, a neural network might fail to correctly identify it, while anomaly detection does not suffer from such a limitation. On the other hand, when there are no systematic errors in the training data, both methods perform comparably.