 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Character-Word Compositional Neural Language Model for Finnish
Dec 10, 2016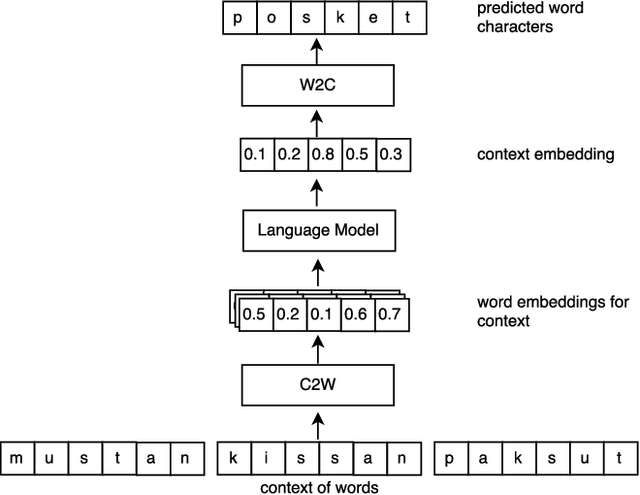
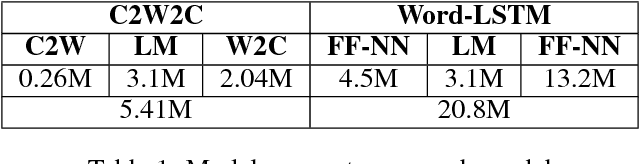
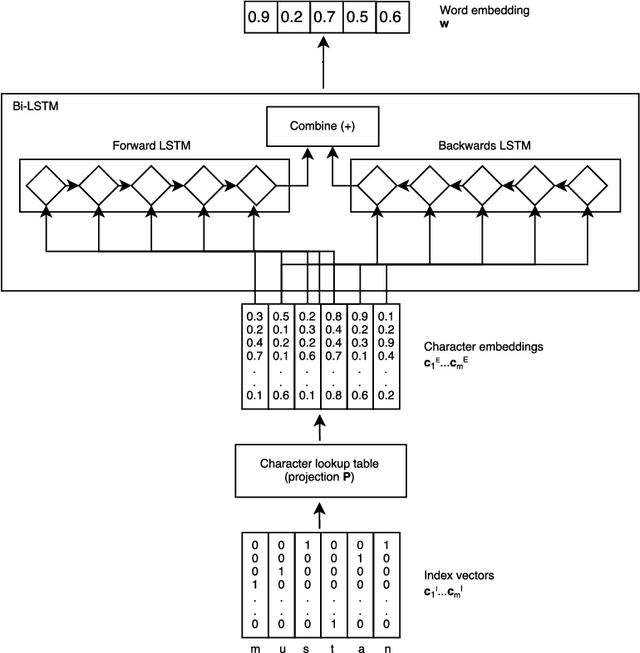

Inspired by recent research, we explore ways to model the highly morphological Finnish language at the level of characters while maintaining the performance of word-level models. We propose a new Character-to-Word-to-Character (C2W2C) compositional language model that uses characters as input and output while still internally processing word level embeddings. Our preliminary experiments, using the Finnish Europarl V7 corpus, indicate that C2W2C can respond well to the challenges of morphologically rich languages such as high out of vocabulary rates, the prediction of novel words, and growing vocabulary size. Notably, the model is able to correctly score inflectional forms that are not present in the training data and sample grammatically and semantically correct Finnish sentences character by character.
DopeLearning: A Computational Approach to Rap Lyrics Generation
Jun 09, 2016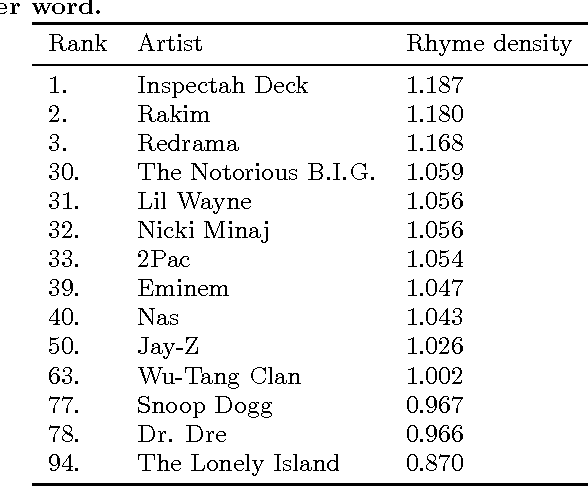
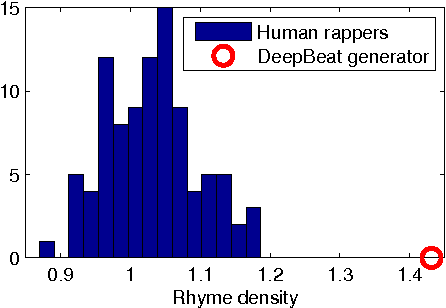

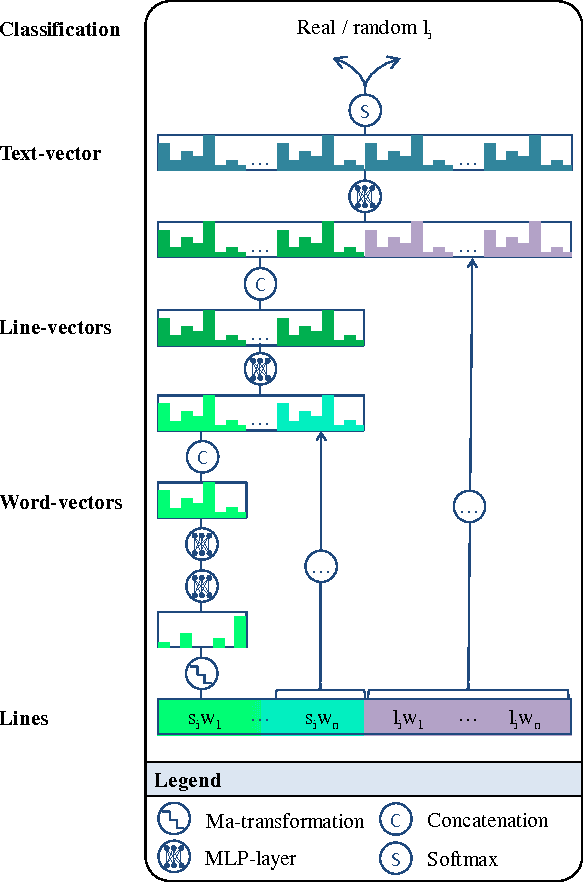
Writing rap lyrics requires both creativity to construct a meaningful, interesting story and lyrical skills to produce complex rhyme patterns, which form the cornerstone of good flow. We present a rap lyrics generation method that captures both of these aspects. First, we develop a prediction model to identify the next line of existing lyrics from a set of candidate next lines. This model is based on two machine-learning techniques: the RankSVM algorithm and a deep neural network model with a novel structure. Results show that the prediction model can identify the true next line among 299 randomly selected lines with an accuracy of 17%, i.e., over 50 times more likely than by random. Second, we employ the prediction model to combine lines from existing songs, producing lyrics with rhyme and a meaning. An evaluation of the produced lyrics shows that in terms of quantitative rhyme density, the method outperforms the best human rappers by 21%. The rap lyrics generator has been deployed as an online tool called DeepBeat, and the performance of the tool has been assessed by analyzing its usage logs. This analysis shows that machine-learned rankings correlate with user preferences.
Good Debt or Bad Debt: Detecting Semantic Orientations in Economic Texts
Jul 23, 2013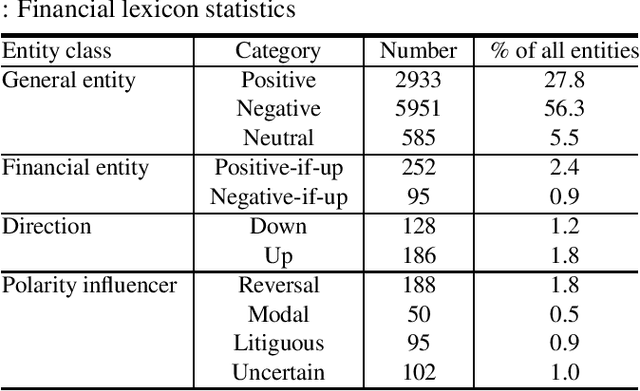

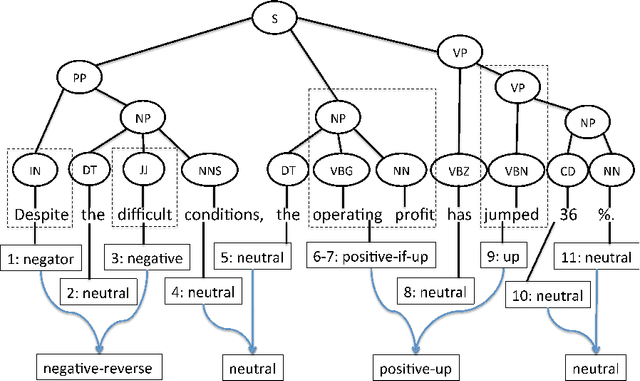
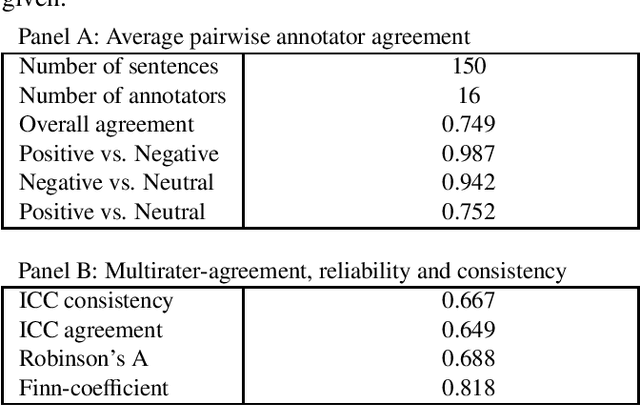
The use of robo-readers to analyze news texts is an emerging technology trend in computational finance. In recent research, a substantial effort has been invested to develop sophisticated financial polarity-lexicons that can be used to investigate how financial sentiments relate to future company performance. However, based on experience from other fields, where sentiment analysis is commonly applied, it is well-known that the overall semantic orientation of a sentence may differ from the prior polarity of individual words. The objective of this article is to investigate how semantic orientations can be better detected in financial and economic news by accommodating the overall phrase-structure information and domain-specific use of language. Our three main contributions are: (1) establishment of a human-annotated finance phrase-bank, which can be used as benchmark for training and evaluating alternative models; (2) presentation of a technique to enhance financial lexicons with attributes that help to identify expected direction of events that affect overall sentiment; (3) development of a linearized phrase-structure model for detecting contextual semantic orientations in financial and economic news texts. The relevance of the newly added lexicon features and the benefit of using the proposed learning-algorithm are demonstrated in a comparative study against previously used general sentiment models as well as the popular word frequency models used in recent financial studies. The proposed framework is parsimonious and avoids the explosion in feature-space caused by the use of conventional n-gram features.